 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
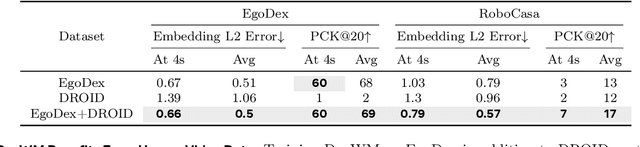
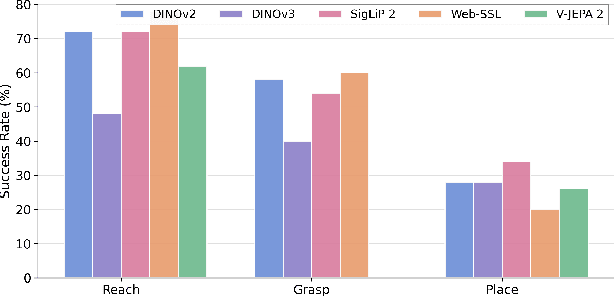
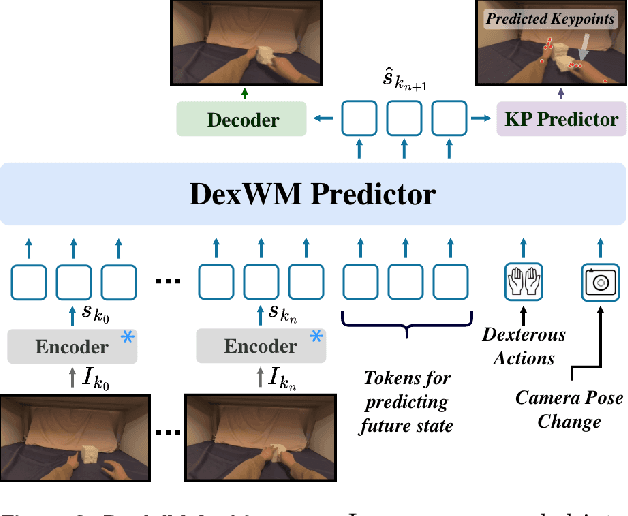
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
Navigation World Models
Dec 04, 2024



Navigation is a fundamental skill of agents with visual-motor capabilities. We introduce a Navigation World Model (NWM), a controllable video generation model that predicts future visual observations based on past observations and navigation actions. To capture complex environment dynamics, NWM employs a Conditional Diffusion Transformer (CDiT), trained on a diverse collection of egocentric videos of both human and robotic agents, and scaled up to 1 billion parameters. In familiar environments, NWM can plan navigation trajectories by simulating them and evaluating whether they achieve the desired goal. Unlike supervised navigation policies with fixed behavior, NWM can dynamically incorporate constraints during planning. Experiments demonstrate its effectiveness in planning trajectories from scratch or by ranking trajectories sampled from an external policy. Furthermore, NWM leverages its learned visual priors to imagine trajectories in unfamiliar environments from a single input image, making it a flexible and powerful tool for next-generation navigation systems.
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Nov 07, 2024



The ability to predict future outcomes given control actions is fundamental for physical reasoning. However, such predictive models, often called world models, have proven challenging to learn and are typically developed for task-specific solutions with online policy learning. We argue that the true potential of world models lies in their ability to reason and plan across diverse problems using only passive data. Concretely, we require world models to have the following three properties: 1) be trainable on offline, pre-collected trajectories, 2) support test-time behavior optimization, and 3) facilitate task-agnostic reasoning. To realize this, we present DINO World Model (DINO-WM), a new method to model visual dynamics without reconstructing the visual world. DINO-WM leverages spatial patch features pre-trained with DINOv2, enabling it to learn from offline behavioral trajectories by predicting future patch features. This design allows DINO-WM to achieve observational goals through action sequence optimization, facilitating task-agnostic behavior planning by treating desired goal patch features as prediction targets. We evaluate DINO-WM across various domains, including maze navigation, tabletop pushing, and particle manipulation. Our experiments demonstrate that DINO-WM can generate zero-shot behavioral solutions at test time without relying on expert demonstrations, reward modeling, or pre-learned inverse models. Notably, DINO-WM exhibits strong generalization capabilities compared to prior state-of-the-art work, adapting to diverse task families such as arbitrarily configured mazes, push manipulation with varied object shapes, and multi-particle scenarios.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
RoboHive: A Unified Framework for Robot Learning
Oct 10, 2023



We present RoboHive, a comprehensive software platform and ecosystem for research in the field of Robot Learning and Embodied Artificial Intelligence. Our platform encompasses a diverse range of pre-existing and novel environments, including dexterous manipulation with the Shadow Hand, whole-arm manipulation tasks with Franka and Fetch robots, quadruped locomotion, among others. Included environments are organized within and cover multiple domains such as hand manipulation, locomotion, multi-task, multi-agent, muscles, etc. In comparison to prior works, RoboHive offers a streamlined and unified task interface taking dependency on only a minimal set of well-maintained packages, features tasks with high physics fidelity and rich visual diversity, and supports common hardware drivers for real-world deployment. The unified interface of RoboHive offers a convenient and accessible abstraction for algorithmic research in imitation, reinforcement, multi-task, and hierarchical learning. Furthermore, RoboHive includes expert demonstrations and baseline results for most environments, providing a standard for benchmarking and comparisons. Details: https://sites.google.com/view/robohive
Train Offline, Test Online: A Real Robot Learning Benchmark
Jun 01, 2023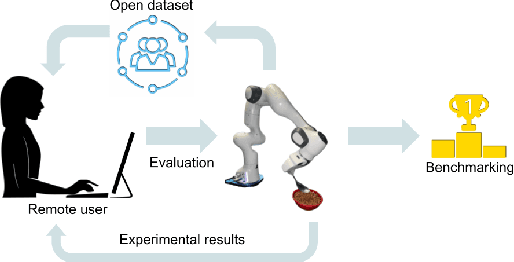
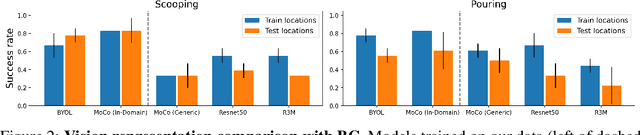
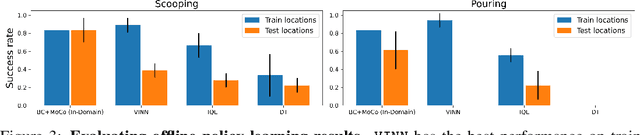

Three challenges limit the progress of robot learning research: robots are expensive (few labs can participate), everyone uses different robots (findings do not generalize across labs), and we lack internet-scale robotics data. We take on these challenges via a new benchmark: Train Offline, Test Online (TOTO). TOTO provides remote users with access to shared robotic hardware for evaluating methods on common tasks and an open-source dataset of these tasks for offline training. Its manipulation task suite requires challenging generalization to unseen objects, positions, and lighting. We present initial results on TOTO comparing five pretrained visual representations and four offline policy learning baselines, remotely contributed by five institutions. The real promise of TOTO, however, lies in the future: we release the benchmark for additional submissions from any user, enabling easy, direct comparison to several methods without the need to obtain hardware or collect data.
Real World Offline Reinforcement Learning with Realistic Data Source
Oct 12, 2022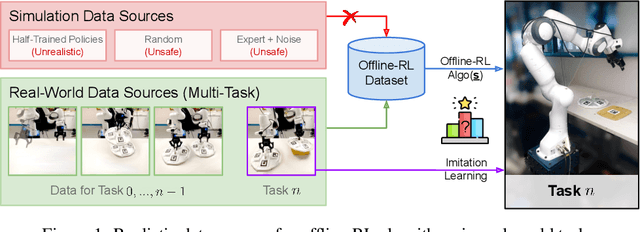

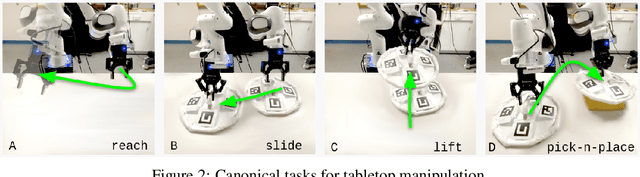

Offline reinforcement learning (ORL) holds great promise for robot learning due to its ability to learn from arbitrary pre-generated experience. However, current ORL benchmarks are almost entirely in simulation and utilize contrived datasets like replay buffers of online RL agents or sub-optimal trajectories, and thus hold limited relevance for real-world robotics. In this work (Real-ORL), we posit that data collected from safe operations of closely related tasks are more practical data sources for real-world robot learning. Under these settings, we perform an extensive (6500+ trajectories collected over 800+ robot hours and 270+ human labor hour) empirical study evaluating generalization and transfer capabilities of representative ORL methods on four real-world tabletop manipulation tasks. Our study finds that ORL and imitation learning prefer different action spaces, and that ORL algorithms can generalize from leveraging offline heterogeneous data sources and outperform imitation learning. We release our dataset and implementations at URL: https://sites.google.com/view/real-orl
Putting the Con in Context: Identifying Deceptive Actors in the Game of Mafia
Jul 05, 2022
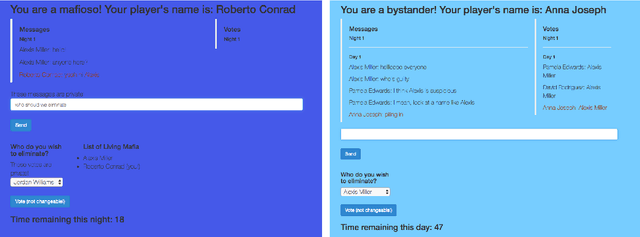


While neural networks demonstrate a remarkable ability to model linguistic content, capturing contextual information related to a speaker's conversational role is an open area of research. In this work, we analyze the effect of speaker role on language use through the game of Mafia, in which participants are assigned either an honest or a deceptive role. In addition to building a framework to collect a dataset of Mafia game records, we demonstrate that there are differences in the language produced by players with different roles. We confirm that classification models are able to rank deceptive players as more suspicious than honest ones based only on their use of language. Furthermore, we show that training models on two auxiliary tasks outperforms a standard BERT-based text classification approach. We also present methods for using our trained models to identify features that distinguish between player roles, which could be used to assist players during the Mafia game.
Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
Nov 19, 2020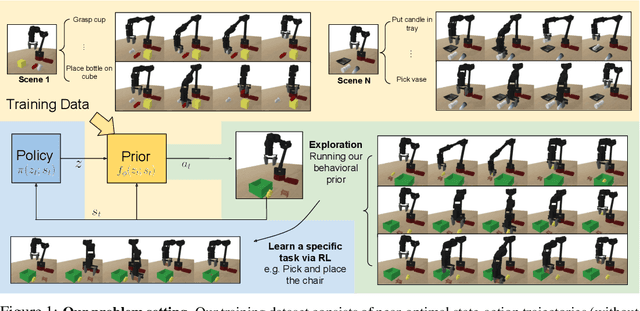
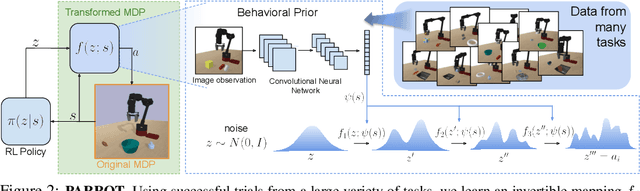
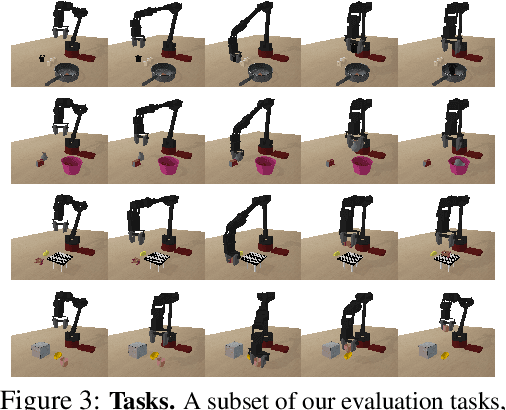

Reinforcement learning provides a general framework for flexible decision making and control, but requires extensive data collection for each new task that an agent needs to learn. In other machine learning fields, such as natural language processing or computer vision, pre-training on large, previously collected datasets to bootstrap learning for new tasks has emerged as a powerful paradigm to reduce data requirements when learning a new task. In this paper, we ask the following question: how can we enable similarly useful pre-training for RL agents? We propose a method for pre-training behavioral priors that can capture complex input-output relationships observed in successful trials from a wide range of previously seen tasks, and we show how this learned prior can be used for rapidly learning new tasks without impeding the RL agent's ability to try out novel behaviors. We demonstrate the effectiveness of our approach in challenging robotic manipulation domains involving image observations and sparse reward functions, where our method outperforms prior works by a substantial margin.