 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeFlesh: Highly customizable Magnetic Touch Sensing using Cut-Cell Microstructures
Jun 11, 2025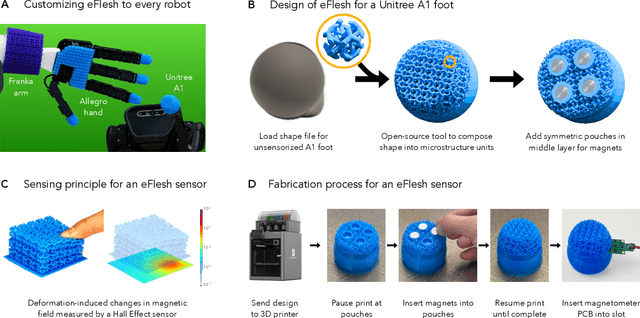


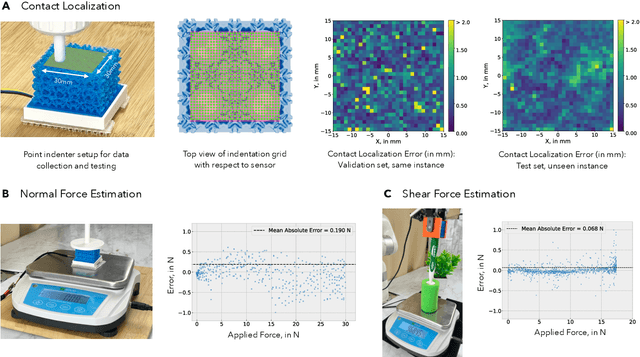
If human experience is any guide, operating effectively in unstructured environments -- like homes and offices -- requires robots to sense the forces during physical interaction. Yet, the lack of a versatile, accessible, and easily customizable tactile sensor has led to fragmented, sensor-specific solutions in robotic manipulation -- and in many cases, to force-unaware, sensorless approaches. With eFlesh, we bridge this gap by introducing a magnetic tactile sensor that is low-cost, easy to fabricate, and highly customizable. Building an eFlesh sensor requires only four components: a hobbyist 3D printer, off-the-shelf magnets (<$5), a CAD model of the desired shape, and a magnetometer circuit board. The sensor is constructed from tiled, parameterized microstructures, which allow for tuning the sensor's geometry and its mechanical response. We provide an open-source design tool that converts convex OBJ/STL files into 3D-printable STLs for fabrication. This modular design framework enables users to create application-specific sensors, and to adjust sensitivity depending on the task. Our sensor characterization experiments demonstrate the capabilities of eFlesh: contact localization RMSE of 0.5 mm, and force prediction RMSE of 0.27 N for normal force and 0.12 N for shear force. We also present a learned slip detection model that generalizes to unseen objects with 95% accuracy, and visuotactile control policies that improve manipulation performance by 40% over vision-only baselines -- achieving 91% average success rate for four precise tasks that require sub-mm accuracy for successful completion. All design files, code and the CAD-to-eFlesh STL conversion tool are open-sourced and available on https://e-flesh.com.
PRS: Sharp Feature Priors for Resolution-Free Surface Remeshing
Nov 30, 2023Surface reconstruction with preservation of geometric features is a challenging computer vision task. Despite significant progress in implicit shape reconstruction, state-of-the-art mesh extraction methods often produce aliased, perceptually distorted surfaces and lack scalability to high-resolution 3D shapes. We present a data-driven approach for automatic feature detection and remeshing that requires only a coarse, aliased mesh as input and scales to arbitrary resolution reconstructions. We define and learn a collection of surface-based fields to (1) capture sharp geometric features in the shape with an implicit vertexwise model and (2) approximate improvements in normals alignment obtained by applying edge-flips with an edgewise model. To support scaling to arbitrary complexity shapes, we learn our fields using local triangulated patches, fusing estimates on complete surface meshes. Our feature remeshing algorithm integrates the learned fields as sharp feature priors and optimizes vertex placement and mesh connectivity for maximum expected surface improvement. On a challenging collection of high-resolution shape reconstructions in the ABC dataset, our algorithm improves over state-of-the-art by 26% normals F-score and 42% perceptual $\text{RMSE}_{\text{v}}$.
Multi-sensor large-scale dataset for multi-view 3D reconstruction
Mar 11, 2022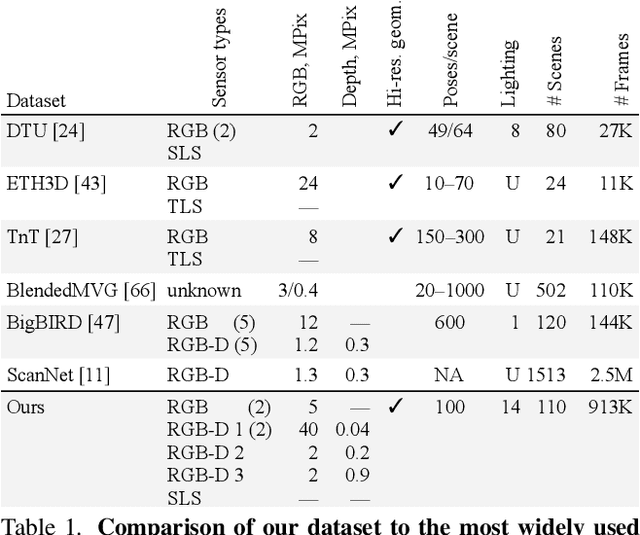
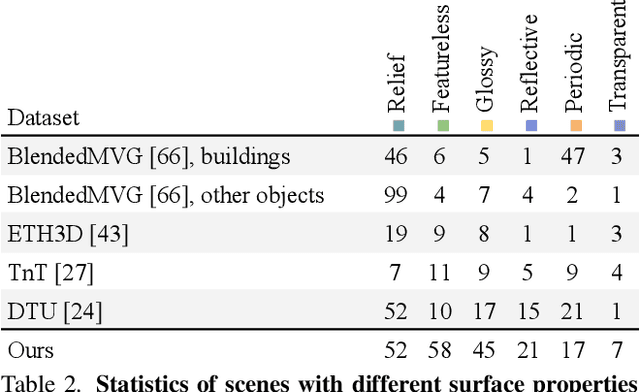

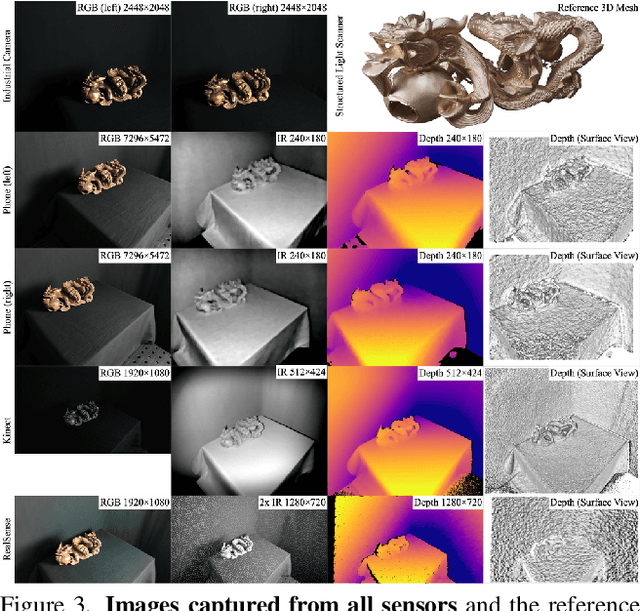
We present a new multi-sensor dataset for 3D surface reconstruction. It includes registered RGB and depth data from sensors of different resolutions and modalities: smartphones, Intel RealSense, Microsoft Kinect, industrial cameras, and structured-light scanner. The data for each scene is obtained under a large number of lighting conditions, and the scenes are selected to emphasize a diverse set of material properties challenging for existing algorithms. In the acquisition process, we aimed to maximize high-resolution depth data quality for challenging cases, to provide reliable ground truth for learning algorithms. Overall, we provide over 1.4 million images of 110 different scenes acquired at 14 lighting conditions from 100 viewing directions. We expect our dataset will be useful for evaluation and training of 3D reconstruction algorithms of different types and for other related tasks. Our dataset and accompanying software will be available online.
Neural Fields as Learnable Kernels for 3D Reconstruction
Nov 26, 2021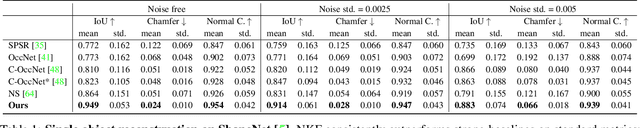

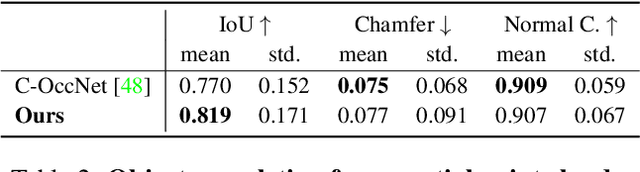
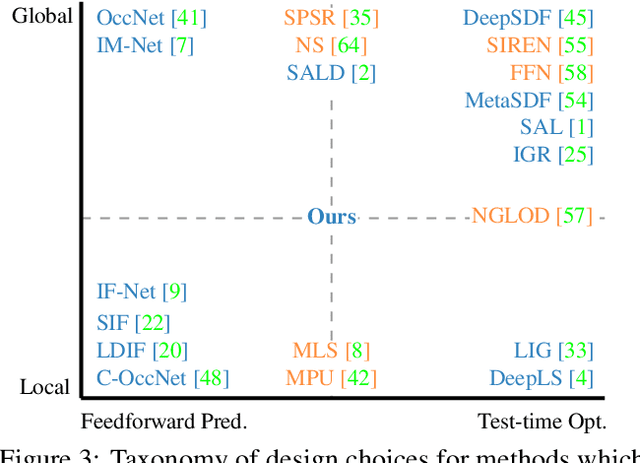
We present Neural Kernel Fields: a novel method for reconstructing implicit 3D shapes based on a learned kernel ridge regression. Our technique achieves state-of-the-art results when reconstructing 3D objects and large scenes from sparse oriented points, and can reconstruct shape categories outside the training set with almost no drop in accuracy. The core insight of our approach is that kernel methods are extremely effective for reconstructing shapes when the chosen kernel has an appropriate inductive bias. We thus factor the problem of shape reconstruction into two parts: (1) a backbone neural network which learns kernel parameters from data, and (2) a kernel ridge regression that fits the input points on-the-fly by solving a simple positive definite linear system using the learned kernel. As a result of this factorization, our reconstruction gains the benefits of data-driven methods under sparse point density while maintaining interpolatory behavior, which converges to the ground truth shape as input sampling density increases. Our experiments demonstrate a strong generalization capability to objects outside the train-set category and scanned scenes. Source code and pretrained models are available at https://nv-tlabs.github.io/nkf.
An Extensible Benchmark Suite for Learning to Simulate Physical Systems
Aug 09, 2021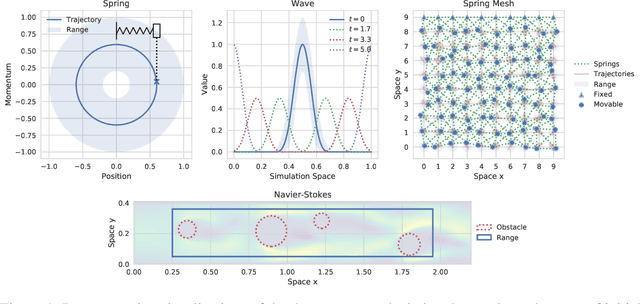

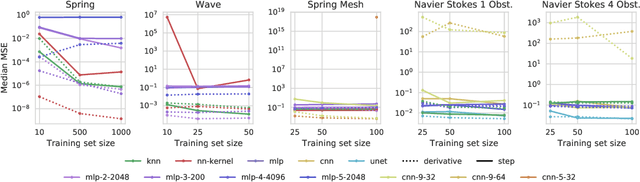
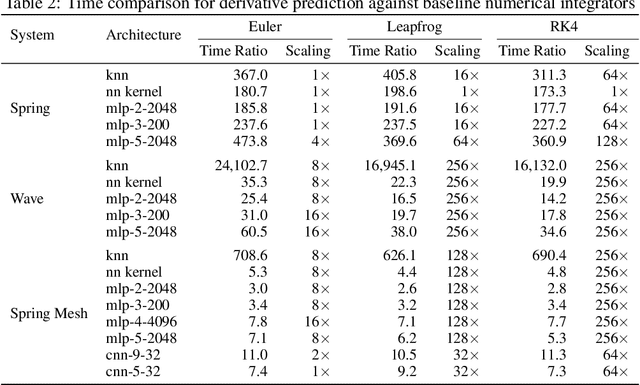
Simulating physical systems is a core component of scientific computing, encompassing a wide range of physical domains and applications. Recently, there has been a surge in data-driven methods to complement traditional numerical simulations methods, motivated by the opportunity to reduce computational costs and/or learn new physical models leveraging access to large collections of data. However, the diversity of problem settings and applications has led to a plethora of approaches, each one evaluated on a different setup and with different evaluation metrics. We introduce a set of benchmark problems to take a step towards unified benchmarks and evaluation protocols. We propose four representative physical systems, as well as a collection of both widely used classical time integrators and representative data-driven methods (kernel-based, MLP, CNN, nearest neighbors). Our framework allows evaluating objectively and systematically the stability, accuracy, and computational efficiency of data-driven methods. Additionally, it is configurable to permit adjustments for accommodating other learning tasks and for establishing a foundation for future developments in machine learning for scientific computing.
3D Parametric Wireframe Extraction Based on Distance Fields
Jul 13, 2021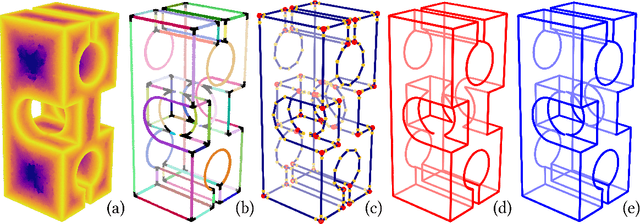

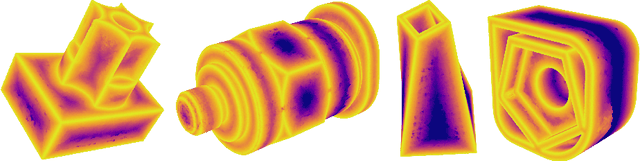
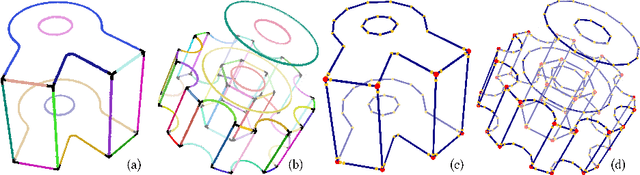
We present a pipeline for parametric wireframe extraction from densely sampled point clouds. Our approach processes a scalar distance field that represents proximity to the nearest sharp feature curve. In intermediate stages, it detects corners, constructs curve segmentation, and builds a topological graph fitted to the wireframe. As an output, we produce parametric spline curves that can be edited and sampled arbitrarily. We evaluate our method on 50 complex 3D shapes and compare it to the novel deep learning-based technique, demonstrating superior quality.
Towards Unpaired Depth Enhancement and Super-Resolution in the Wild
May 25, 2021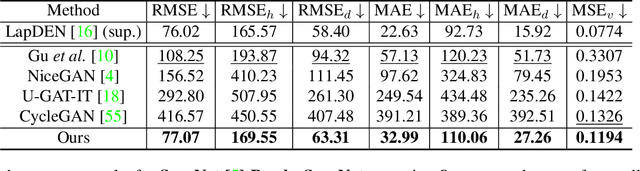
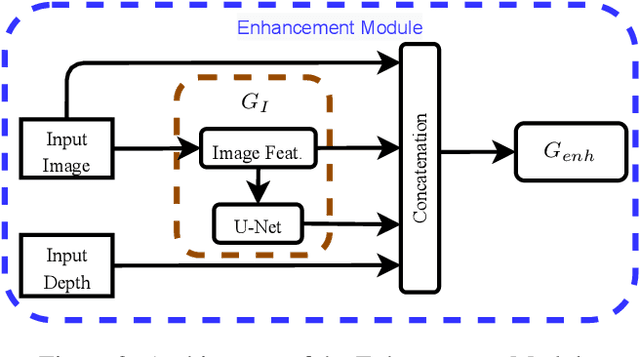
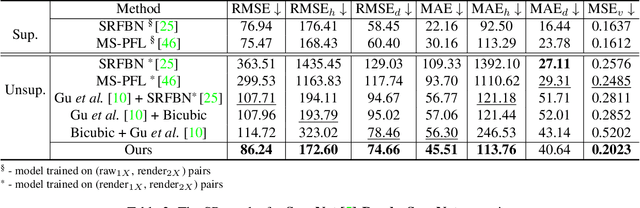
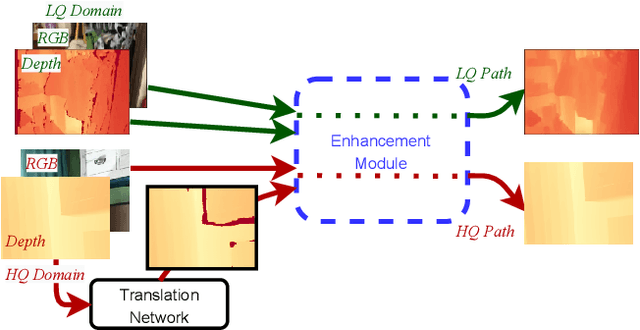
Depth maps captured with commodity sensors are often of low quality and resolution; these maps need to be enhanced to be used in many applications. State-of-the-art data-driven methods of depth map super-resolution rely on registered pairs of low- and high-resolution depth maps of the same scenes. Acquisition of real-world paired data requires specialized setups. Another alternative, generating low-resolution maps from high-resolution maps by subsampling, adding noise and other artificial degradation methods, does not fully capture the characteristics of real-world low-resolution images. As a consequence, supervised learning methods trained on such artificial paired data may not perform well on real-world low-resolution inputs. We consider an approach to depth map enhancement based on learning from unpaired data. While many techniques for unpaired image-to-image translation have been proposed, most are not directly applicable to depth maps. We propose an unpaired learning method for simultaneous depth enhancement and super-resolution, which is based on a learnable degradation model and surface normal estimates as features to produce more accurate depth maps. We demonstrate that our method outperforms existing unpaired methods and performs on par with paired methods on a new benchmark for unpaired learning that we developed.
Orienting Point Clouds with Dipole Propagation
May 04, 2021
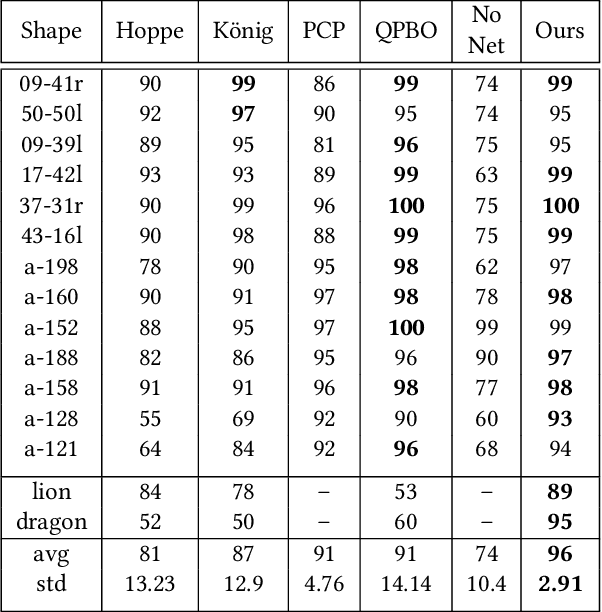
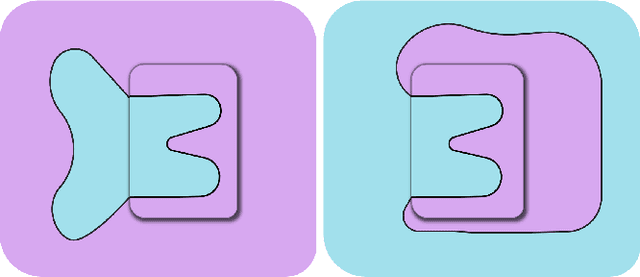
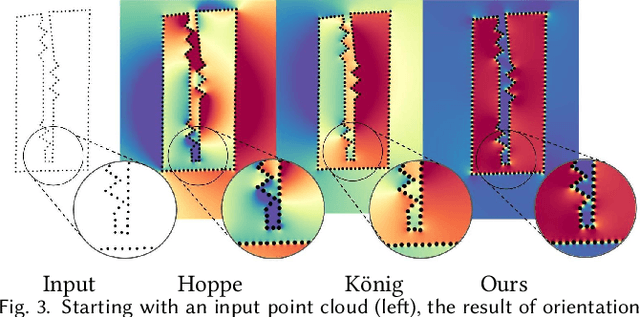
Establishing a consistent normal orientation for point clouds is a notoriously difficult problem in geometry processing, requiring attention to both local and global shape characteristics. The normal direction of a point is a function of the local surface neighborhood; yet, point clouds do not disclose the full underlying surface structure. Even assuming known geodesic proximity, calculating a consistent normal orientation requires the global context. In this work, we introduce a novel approach for establishing a globally consistent normal orientation for point clouds. Our solution separates the local and global components into two different sub-problems. In the local phase, we train a neural network to learn a coherent normal direction per patch (i.e., consistently oriented normals within a single patch). In the global phase, we propagate the orientation across all coherent patches using a dipole propagation. Our dipole propagation decides to orient each patch using the electric field defined by all previously orientated patches. This gives rise to a global propagation that is stable, as well as being robust to nearby surfaces, holes, sharp features and noise.
Towards Part-Based Understanding of RGB-D Scans
Dec 03, 2020
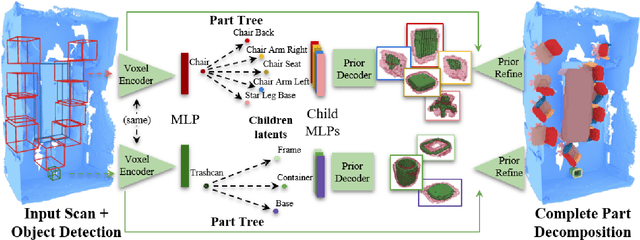

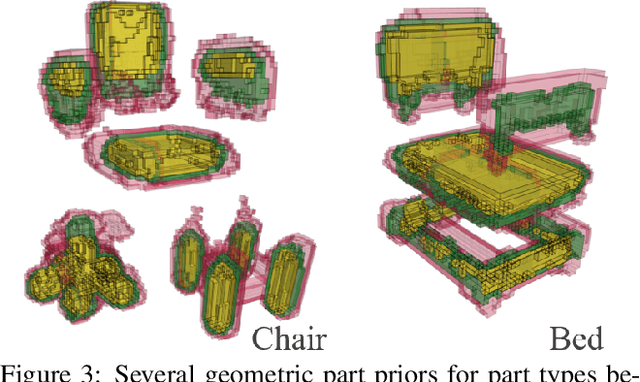
Recent advances in 3D semantic scene understanding have shown impressive progress in 3D instance segmentation, enabling object-level reasoning about 3D scenes; however, a finer-grained understanding is required to enable interactions with objects and their functional understanding. Thus, we propose the task of part-based scene understanding of real-world 3D environments: from an RGB-D scan of a scene, we detect objects, and for each object predict its decomposition into geometric part masks, which composed together form the complete geometry of the observed object. We leverage an intermediary part graph representation to enable robust completion as well as building of part priors, which we use to construct the final part mask predictions. Our experiments demonstrate that guiding part understanding through part graph to part prior-based predictions significantly outperforms alternative approaches to the task of semantic part completion.
DEF: Deep Estimation of Sharp Geometric Features in 3D Shapes
Nov 30, 2020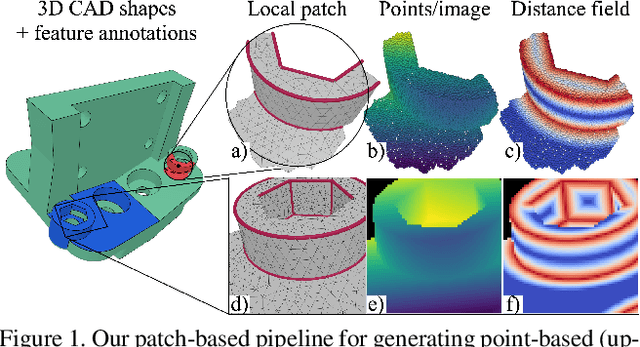
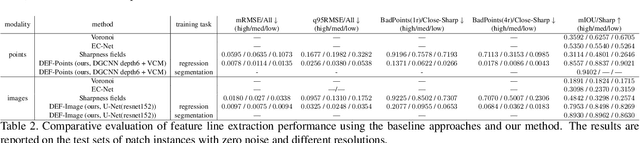
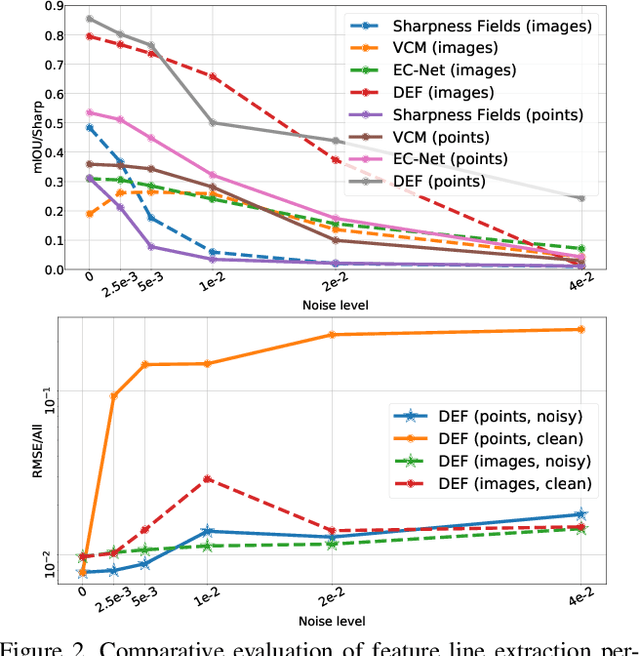
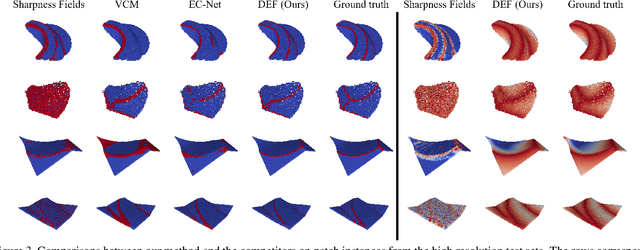
Sharp feature lines carry essential information about human-made objects, enabling compact 3D shape representations, high-quality surface reconstruction, and are a signal source for mesh processing. While extracting high-quality lines from noisy and undersampled data is challenging for traditional methods, deep learning-powered algorithms can leverage global and semantic information from the training data to aid in the process. We propose Deep Estimators of Features (DEFs), a learning-based framework for predicting sharp geometric features in sampled 3D shapes. Differently from existing data-driven methods, which reduce this problem to feature classification, we propose to regress a scalar field representing the distance from point samples to the closest feature line on local patches. By fusing the result of individual patches, we can process large 3D models, which are impossible to process for existing data-driven methods due to their size and complexity. Extensive experimental evaluation of DEFs is implemented on synthetic and real-world 3D shape datasets and suggests advantages of our image- and point-based estimators over competitor methods, as well as improved noise robustness and scalability of our approach.