 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirac-Frenkel dynamics with inertia for nonlinearly parametrized solutions of evolution problems
Jun 23, 2026Even when Dirac-Frenkel dynamics determine a well-defined evolution in function space, the corresponding parameter dynamics can be non-unique or ill-conditioned for redundant nonlinear parametrizations such as neural networks or mixture models. We propose to add inertia to the Dirac-Frenkel dynamics and show that this allows useful parameter velocity information to persist from the past trajectory in directions that are weakly informed, while well-informed parameter velocity directions continue to follow the Dirac-Frenkel dynamics. We prove that the inertial formulation yields well-posed parameter dynamics and provide a posteriori error bounds. After time discretization, the method requires the solution of the same type of regularized linear least-squares problem as standard Dirac-Frenkel dynamics, but with the previous velocity appearing as an anchor. Numerical experiments demonstrate the increased robustness obtained with inertia.
First-Order Trajectory Matching: Fast Ensemble Predictions of Chaotic, Turbulent, Stochastic Systems
Jun 09, 2026We introduce First-Order Trajectory Matching (FTM), a surrogate-modeling method that learns the first-order local transport of probability mass from trajectories of stochastic systems. By matching the symmetric first-order motion of trajectories, FTM learns the probability current velocity, whose flow preserves time marginals to match ensemble averages, while also capturing current-like trajectory quantities such as fluxes, circulations, and barrier-crossing currents. FTM learns the current velocity directly from trajectories, avoiding drift, diffusion, and score estimation. Our stability analysis separates discretization error from sampling variance and shows that the one-step simulation-free FTM loss is stable when temporal resolution and sample size are properly balanced. Across stochastic dynamical systems and PDE examples, we empirically demonstrate that FTM provides trajectory-aware ensemble predictions at low, deterministic-rollout cost.
Stochastic Lifting for Generating Trajectories of Stochastic Physical Systems
May 28, 2026Many stochastic physical systems evolve smoothly over time in the sense that the distribution of states changes regularly across time steps. The transition from current state to the next state can often be modeled as the combination of a smooth map and an explicit source of randomness. Stochastic Lifting exploits this structure by attaching an independent, high-dimensional random label to each state transition in the training data and fitting a transition map from the current state and label to the next state using a standard regression loss. The labels act as auxiliary coordinates that let the model represent multiple plausible next states from similar current states, avoiding collapse to a mean prediction in the finite-sample size regime. At inference, fresh labels are sampled at each time step and the learned map is rolled forward autoregressively, generating diverse trajectories with a single network evaluation per time step.
Two-Parameter Flows for Learning Population Dynamics of Physical Systems
May 25, 2026This work addresses the problem of learning the dynamics of high-dimensional probability densities over time using unlabeled samples, without assuming access to trajectory information. We introduce two-parameter flows that learn only sampling-time transports from a base distribution to each marginal and then extract a physics-time velocity by regressing on coupled synthetic trajectories. We prove that the resulting physics-time dynamics are unique and inherit regularity from the sampling-time transports. Because we can build on standard, well-developed conditional flow matching techniques for learning the base-to-marginal transports, our approach scales to high dimensions and avoids per-step optimal-transport couplings, while allowing admissible non-gradient dynamics that can naturally explain rotational or circulating physics phenomena.
Leveraging Gauge Freedom for Learning Non-Gradient Population Dynamics of Stochastic Systems
May 24, 2026Existing work on population dynamics inference often focuses on flows arising from vector fields that are the gradients of scalar potentials. Among all admissible flows that are compatible with the population dynamics, gradient flows are optimal in a specific sense: they minimize kinetic energy. The selection of fields based on different criteria corresponds to a gauge freedom when determining population dynamics, which we leverage in this work. We propose Non-Gradient Inference Flows (NGIF), an algorithm to infer non-gradient population dynamics using a weak formulation of the continuity equation. This allows us to parameterize general vector fields and choose other selection criteria beyond minimal kinetic energy. We demonstrate on a variety of low- and high-dimensional physics problems that this more general approach improves distributional accuracy over gradient-restricted baselines and better captures non-potential transport.
Nonlinear model reduction for transport-dominated problems
Feb 01, 2026This article surveys nonlinear model reduction methods that remain effective in regimes where linear reduced-space approximations are intrinsically inefficient, such as transport-dominated problems with wave-like phenomena and moving coherent structures, which are commonly associated with the Kolmogorov barrier. The article organizes nonlinear model reduction techniques around three key elements -- nonlinear parametrizations, reduced dynamics, and online solvers -- and categorizes existing approaches into transformation-based methods, online adaptive techniques, and formulations that combine generic nonlinear parametrizations with instantaneous residual minimization.
Hankel Singular Value Regularization for Highly Compressible State Space Models
Oct 27, 2025Deep neural networks using state space models as layers are well suited for long-range sequence tasks but can be challenging to compress after training. We use that regularizing the sum of Hankel singular values of state space models leads to a fast decay of these singular values and thus to compressible models. To make the proposed Hankel singular value regularization scalable, we develop an algorithm to efficiently compute the Hankel singular values during training iterations by exploiting the specific block-diagonal structure of the system matrices that is we use in our state space model parametrization. Experiments on Long Range Arena benchmarks demonstrate that the regularized state space layers are up to 10$\times$ more compressible than standard state space layers while maintaining high accuracy.
Operator Inference Aware Quadratic Manifolds with Isotropic Reduced Coordinates for Nonintrusive Model Reduction
Jul 28, 2025Quadratic manifolds for nonintrusive reduced modeling are typically trained to minimize the reconstruction error on snapshot data, which means that the error of models fitted to the embedded data in downstream learning steps is ignored. In contrast, we propose a greedy training procedure that takes into account both the reconstruction error on the snapshot data and the prediction error of reduced models fitted to the data. Because our procedure learns quadratic manifolds with the objective of achieving accurate reduced models, it avoids oscillatory and other non-smooth embeddings that can hinder learning accurate reduced models. Numerical experiments on transport and turbulent flow problems show that quadratic manifolds trained with the proposed greedy approach lead to reduced models with up to two orders of magnitude higher accuracy than quadratic manifolds trained with respect to the reconstruction error alone.
Parametric model reduction of mean-field and stochastic systems via higher-order action matching
Oct 15, 2024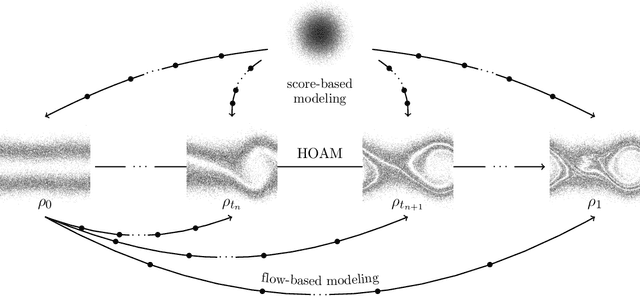

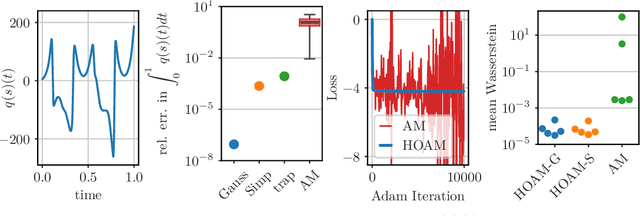
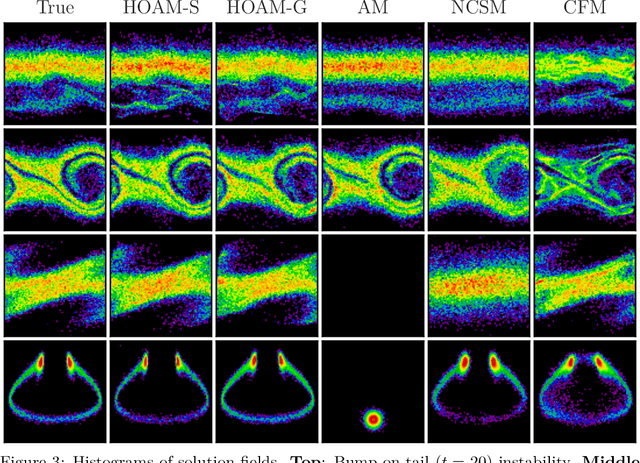
The aim of this work is to learn models of population dynamics of physical systems that feature stochastic and mean-field effects and that depend on physics parameters. The learned models can act as surrogates of classical numerical models to efficiently predict the system behavior over the physics parameters. Building on the Benamou-Brenier formula from optimal transport and action matching, we use a variational problem to infer parameter- and time-dependent gradient fields that represent approximations of the population dynamics. The inferred gradient fields can then be used to rapidly generate sample trajectories that mimic the dynamics of the physical system on a population level over varying physics parameters. We show that combining Monte Carlo sampling with higher-order quadrature rules is critical for accurately estimating the training objective from sample data and for stabilizing the training process. We demonstrate on Vlasov-Poisson instabilities as well as on high-dimensional particle and chaotic systems that our approach accurately predicts population dynamics over a wide range of parameters and outperforms state-of-the-art diffusion-based and flow-based modeling that simply condition on time and physics parameters.
System stabilization with policy optimization on unstable latent manifolds
Jul 08, 2024Stability is a basic requirement when studying the behavior of dynamical systems. However, stabilizing dynamical systems via reinforcement learning is challenging because only little data can be collected over short time horizons before instabilities are triggered and data become meaningless. This work introduces a reinforcement learning approach that is formulated over latent manifolds of unstable dynamics so that stabilizing policies can be trained from few data samples. The unstable manifolds are minimal in the sense that they contain the lowest dimensional dynamics that are necessary for learning policies that guarantee stabilization. This is in stark contrast to generic latent manifolds that aim to approximate all -- stable and unstable -- system dynamics and thus are higher dimensional and often require higher amounts of data. Experiments demonstrate that the proposed approach stabilizes even complex physical systems from few data samples for which other methods that operate either directly in the system state space or on generic latent manifolds fail.