 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Bid with Unknown Private Values in Budget-Constrained First-Price Auctions
May 10, 2026The transition to First-Price Auctions (FPA) in digital advertising has spurred significant research, yet existing work typically assumes access to a valuation oracle, ignoring the reality that values must be inferred from censored data. While Linear Treatment Effect (LTE) models address this by learning value uplift, they have not been adapted to realistic settings with hard Budget constraints or Return-on-Spend (RoS) targets requiring regret and violation control. In this work, we propose a unified primal-dual framework for constrained FPAs that jointly learns the latent LTE valuation parameters and the competitor's bid distribution. This simultaneous learning introduces a critical technical challenge: the estimation error is dynamically scaled by the Lagrangian multiplier, potentially leading to unbounded regret. We resolve this by leveraging a strong Slater condition and a novel adaptive burn-in procedure to stabilize the dual variables. Our approach achieves near-optimal regret guarantees, providing the first theoretically grounded solution for constrained bidding with latent valuations.
The (Marginal) Value of a Search Ad: An Online Causal Framework for Repeated Second-price Auctions
May 03, 2026Existing auto-bidding algorithms in digital advertising often treat the value of an ad opportunity as the revenue obtained when an ad is shown and/or clicked, and bid accordingly. This can lead to wasteful spending because the true value is the marginal gain from paid exposure: even without winning a sponsored slot, an advertiser may still earn revenue via an organic search result (e.g., on Google or Amazon). Motivated by recent work, we model ad value as a treatment effect--the outcome difference between winning and losing the auction--and study online learning for bidding in second-price (Vickrey) auctions under this causal perspective. We develop algorithms that attain rate-optimal regret under several feedback models. A key ingredient exploits the information revealed by the second-price payment rule, which strictly improves regret relative to analogous learning problems in first-price auctions.
Adversarial Combinatorial Semi-bandits with Graph Feedback
Feb 26, 2025In combinatorial semi-bandits, a learner repeatedly selects from a combinatorial decision set of arms, receives the realized sum of rewards, and observes the rewards of the individual selected arms as feedback. In this paper, we extend this framework to include \emph{graph feedback}, where the learner observes the rewards of all neighboring arms of the selected arms in a feedback graph $G$. We establish that the optimal regret over a time horizon $T$ scales as $\widetilde{\Theta}(S\sqrt{T}+\sqrt{\alpha ST})$, where $S$ is the size of the combinatorial decisions and $\alpha$ is the independence number of $G$. This result interpolates between the known regrets $\widetilde\Theta(S\sqrt{T})$ under full information (i.e., $G$ is complete) and $\widetilde\Theta(\sqrt{KST})$ under the semi-bandit feedback (i.e., $G$ has only self-loops), where $K$ is the total number of arms. A key technical ingredient is to realize a convexified action using a random decision vector with negative correlations.
Joint Value Estimation and Bidding in Repeated First-Price Auctions
Feb 24, 2025We study regret minimization in repeated first-price auctions (FPAs), where a bidder observes only the realized outcome after each auction -- win or loss. This setup reflects practical scenarios in online display advertising where the actual value of an impression depends on the difference between two potential outcomes, such as clicks or conversion rates, when the auction is won versus lost. We analyze three outcome models: (1) adversarial outcomes without features, (2) linear potential outcomes with features, and (3) linear treatment effects in features. For each setting, we propose algorithms that jointly estimate private values and optimize bidding strategies, achieving near-optimal regret bounds. Notably, our framework enjoys a unique feature that the treatments are also actively chosen, and hence eliminates the need for the overlap condition commonly required in causal inference.
How DNNs break the Curse of Dimensionality: Compositionality and Symmetry Learning
Jul 08, 2024We show that deep neural networks (DNNs) can efficiently learn any composition of functions with bounded $F_{1}$-norm, which allows DNNs to break the curse of dimensionality in ways that shallow networks cannot. More specifically, we derive a generalization bound that combines a covering number argument for compositionality, and the $F_{1}$-norm (or the related Barron norm) for large width adaptivity. We show that the global minimizer of the regularized loss of DNNs can fit for example the composition of two functions $f^{*}=h\circ g$ from a small number of observations, assuming $g$ is smooth/regular and reduces the dimensionality (e.g. $g$ could be the modulo map of the symmetries of $f^{*}$), so that $h$ can be learned in spite of its low regularity. The measures of regularity we consider is the Sobolev norm with different levels of differentiability, which is well adapted to the $F_{1}$ norm. We compute scaling laws empirically and observe phase transitions depending on whether $g$ or $h$ is harder to learn, as predicted by our theory.
Stochastic contextual bandits with graph feedback: from independence number to MAS number
Feb 12, 2024We consider contextual bandits with graph feedback, a class of interactive learning problems with richer structures than vanilla contextual bandits, where taking an action reveals the rewards for all neighboring actions in the feedback graph under all contexts. Unlike the multi-armed bandits setting where a growing literature has painted a near-complete understanding of graph feedback, much remains unexplored in the contextual bandits counterpart. In this paper, we make inroads into this inquiry by establishing a regret lower bound $\Omega(\sqrt{\beta_M(G) T})$, where $M$ is the number of contexts, $G$ is the feedback graph, and $\beta_M(G)$ is our proposed graph-theoretical quantity that characterizes the fundamental learning limit for this class of problems. Interestingly, $\beta_M(G)$ interpolates between $\alpha(G)$ (the independence number of the graph) and $\mathsf{m}(G)$ (the maximum acyclic subgraph (MAS) number of the graph) as the number of contexts $M$ varies. We also provide algorithms that achieve near-optimal regrets for important classes of context sequences and/or feedback graphs, such as transitively closed graphs that find applications in auctions and inventory control. In particular, with many contexts, our results show that the MAS number completely characterizes the statistical complexity for contextual bandits, as opposed to the independence number in multi-armed bandits.
Which Frequencies do CNNs Need? Emergent Bottleneck Structure in Feature Learning
Feb 12, 2024We describe the emergence of a Convolution Bottleneck (CBN) structure in CNNs, where the network uses its first few layers to transform the input representation into a representation that is supported only along a few frequencies and channels, before using the last few layers to map back to the outputs. We define the CBN rank, which describes the number and type of frequencies that are kept inside the bottleneck, and partially prove that the parameter norm required to represent a function $f$ scales as depth times the CBN rank $f$. We also show that the parameter norm depends at next order on the regularity of $f$. We show that any network with almost optimal parameter norm will exhibit a CBN structure in both the weights and - under the assumption that the network is stable under large learning rate - the activations, which motivates the common practice of down-sampling; and we verify that the CBN results still hold with down-sampling. Finally we use the CBN structure to interpret the functions learned by CNNs on a number of tasks.
Coupling parameter and particle dynamics for adaptive sampling in Neural Galerkin schemes
Jun 27, 2023



Training nonlinear parametrizations such as deep neural networks to numerically approximate solutions of partial differential equations is often based on minimizing a loss that includes the residual, which is analytically available in limited settings only. At the same time, empirically estimating the training loss is challenging because residuals and related quantities can have high variance, especially for transport-dominated and high-dimensional problems that exhibit local features such as waves and coherent structures. Thus, estimators based on data samples from un-informed, uniform distributions are inefficient. This work introduces Neural Galerkin schemes that estimate the training loss with data from adaptive distributions, which are empirically represented via ensembles of particles. The ensembles are actively adapted by evolving the particles with dynamics coupled to the nonlinear parametrizations of the solution fields so that the ensembles remain informative for estimating the training loss. Numerical experiments indicate that few dynamic particles are sufficient for obtaining accurate empirical estimates of the training loss, even for problems with local features and with high-dimensional spatial domains.
Active operator inference for learning low-dimensional dynamical-system models from noisy data
Jul 26, 2021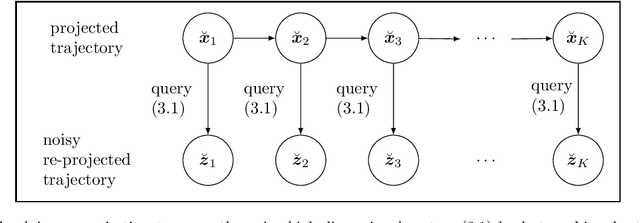

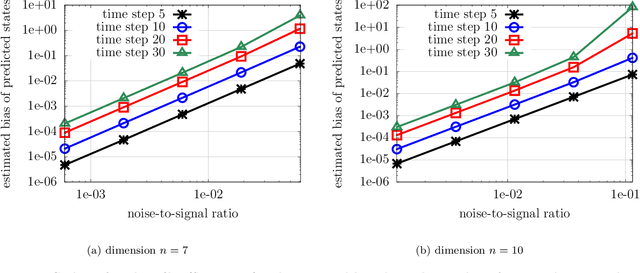
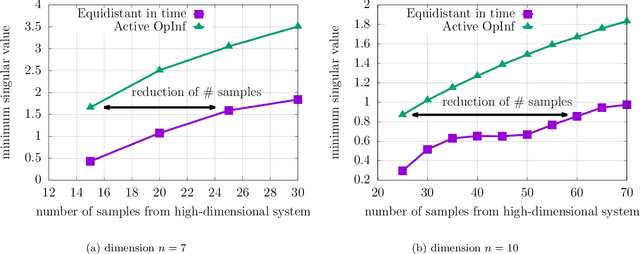
Noise poses a challenge for learning dynamical-system models because already small variations can distort the dynamics described by trajectory data. This work builds on operator inference from scientific machine learning to infer low-dimensional models from high-dimensional state trajectories polluted with noise. The presented analysis shows that, under certain conditions, the inferred operators are unbiased estimators of the well-studied projection-based reduced operators from traditional model reduction. Furthermore, the connection between operator inference and projection-based model reduction enables bounding the mean-squared errors of predictions made with the learned models with respect to traditional reduced models. The analysis also motivates an active operator inference approach that judiciously samples high-dimensional trajectories with the aim of achieving a low mean-squared error by reducing the effect of noise. Numerical experiments with high-dimensional linear and nonlinear state dynamics demonstrate that predictions obtained with active operator inference have orders of magnitude lower mean-squared errors than operator inference with traditional, equidistantly sampled trajectory data.