 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-adaptive SympNets for separable Hamiltonian systems
Sep 19, 2025Measurement data is often sampled irregularly i.e. not on equidistant time grids. This is also true for Hamiltonian systems. However, existing machine learning methods, which learn symplectic integrators, such as SympNets [20] and H\'enonNets [4] still require training data generated by fixed step sizes. To learn time-adaptive symplectic integrators, an extension to SympNets, which we call TSympNets, was introduced in [20]. We adapt the architecture of TSympNets and extend them to non-autonomous Hamiltonian systems. So far the approximation qualities of TSympNets were unknown. We close this gap by providing a universal approximation theorem for separable Hamiltonian systems and show that it is not possible to extend it to non-separable Hamiltonian systems. To investigate these theoretical approximation capabilities, we perform different numerical experiments. Furthermore we fix a mistake in a proof of a substantial theorem [25, Theorem 2] for the approximation of symplectic maps in general, but specifically for symplectic machine learning methods.
Symplectic convolutional neural networks
Aug 27, 2025We propose a new symplectic convolutional neural network (CNN) architecture by leveraging symplectic neural networks, proper symplectic decomposition, and tensor techniques. Specifically, we first introduce a mathematically equivalent form of the convolution layer and then, using symplectic neural networks, we demonstrate a way to parameterize the layers of the CNN to ensure that the convolution layer remains symplectic. To construct a complete autoencoder, we introduce a symplectic pooling layer. We demonstrate the performance of the proposed neural network on three examples: the wave equation, the nonlinear Schr\"odinger (NLS) equation, and the sine-Gordon equation. The numerical results indicate that the symplectic CNN outperforms the linear symplectic autoencoder obtained via proper symplectic decomposition.
Interpretable Spatial-Temporal Fusion Transformers: Multi-Output Prediction for Parametric Dynamical Systems with Time-Varying Inputs
May 01, 2025


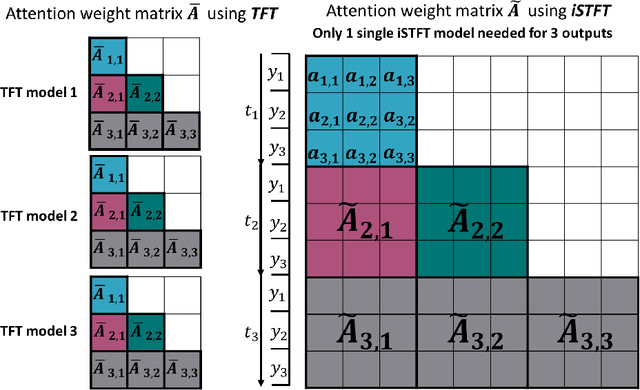
We explore the promising performance of a transformer model in predicting outputs of parametric dynamical systems with external time-varying input signals. The outputs of such systems vary not only with physical parameters but also with external time-varying input signals. Accurately catching the dynamics of such systems is challenging. We have adapted and extended an existing transformer model for single output prediction to a multiple-output transformer that is able to predict multiple output responses of these systems. The multiple-output transformer generalizes the interpretability of the original transformer. The generalized interpretable attention weight matrix explores not only the temporal correlations in the sequence, but also the interactions between the multiple outputs, providing explanation for the spatial correlation in the output domain. This multiple-output transformer accurately predicts the sequence of multiple outputs, regardless of the nonlinearity of the system and the dimensionality of the parameter space.
Subspace-Distance-Enabled Active Learning for Efficient Data-Driven Model Reduction of Parametric Dynamical Systems
May 01, 2025In situations where the solution of a high-fidelity dynamical system needs to be evaluated repeatedly, over a vast pool of parametric configurations and in absence of access to the underlying governing equations, data-driven model reduction techniques are preferable. We propose a novel active learning approach to build a parametric data-driven reduced-order model (ROM) by greedily picking the most important parameter samples from the parameter domain. As a result, during the ROM construction phase, the number of high-fidelity solutions dynamically grow in a principled fashion. The high-fidelity solution snapshots are expressed in several parameter-specific linear subspaces, with the help of proper orthogonal decomposition (POD), and the relative distance between these subspaces is used as a guiding mechanism to perform active learning. For successfully achieving this, we provide a distance measure to evaluate the similarity between pairs of linear subspaces with different dimensions, and also show that this distance measure is a metric. The usability of the proposed subspace-distance-enabled active learning (SDE-AL) framework is demonstrated by augmenting two existing non-intrusive reduced-order modeling approaches, and providing their active-learning-driven (ActLearn) extensions, namely, SDE-ActLearn-POD-KSNN, and SDE-ActLearn-POD-NN. Furthermore, we report positive results for two parametric physical models, highlighting the efficiency of the proposed SDE-AL approach.
Data-Augmented Predictive Deep Neural Network: Enhancing the extrapolation capabilities of non-intrusive surrogate models
Oct 17, 2024



Numerically solving a large parametric nonlinear dynamical system is challenging due to its high complexity and the high computational costs. In recent years, machine-learning-aided surrogates are being actively researched. However, many methods fail in accurately generalizing in the entire time interval $[0, T]$, when the training data is available only in a training time interval $[0, T_0]$, with $T_0<T$. To improve the extrapolation capabilities of the surrogate models in the entire time domain, we propose a new deep learning framework, where kernel dynamic mode decomposition (KDMD) is employed to evolve the dynamics of the latent space generated by the encoder part of a convolutional autoencoder (CAE). After adding the KDMD-decoder-extrapolated data into the original data set, we train the CAE along with a feed-forward deep neural network using the augmented data. The trained network can predict future states outside the training time interval at any out-of-training parameter samples. The proposed method is tested on two numerical examples: a FitzHugh-Nagumo model and a model of incompressible flow past a cylinder. Numerical results show accurate and fast prediction performance in both the time and the parameter domain.
Structure-preserving learning for multi-symplectic PDEs
Sep 16, 2024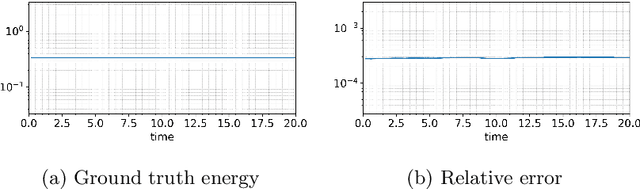
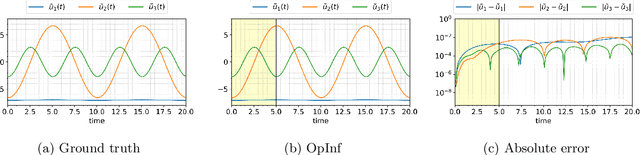

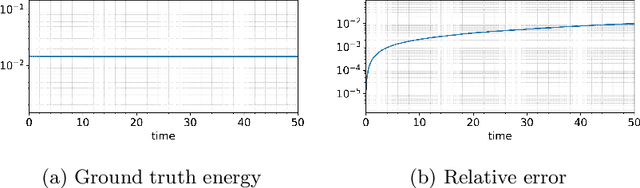
This paper presents an energy-preserving machine learning method for inferring reduced-order models (ROMs) by exploiting the multi-symplectic form of partial differential equations (PDEs). The vast majority of energy-preserving reduced-order methods use symplectic Galerkin projection to construct reduced-order Hamiltonian models by projecting the full models onto a symplectic subspace. However, symplectic projection requires the existence of fully discrete operators, and in many cases, such as black-box PDE solvers, these operators are inaccessible. In this work, we propose an energy-preserving machine learning method that can infer the dynamics of the given PDE using data only, so that the proposed framework does not depend on the fully discrete operators. In this context, the proposed method is non-intrusive. The proposed method is grey box in the sense that it requires only some basic knowledge of the multi-symplectic model at the partial differential equation level. We prove that the proposed method satisfies spatially discrete local energy conservation and preserves the multi-symplectic conservation laws. We test our method on the linear wave equation, the Korteweg-de Vries equation, and the Zakharov-Kuznetsov equation. We test the generalization of our learned models by testing them far outside the training time interval.
Active Sampling of Interpolation Points to Identify Dominant Subspaces for Model Reduction
Sep 05, 2024



Model reduction is an active research field to construct low-dimensional surrogate models of high fidelity to accelerate engineering design cycles. In this work, we investigate model reduction for linear structured systems using dominant reachable and observable subspaces. When the training set $-$ containing all possible interpolation points $-$ is large, then these subspaces can be determined by solving many large-scale linear systems. However, for high-fidelity models, this easily becomes computationally intractable. To circumvent this issue, in this work, we propose an active sampling strategy to sample only a few points from the given training set, which can allow us to estimate those subspaces accurately. To this end, we formulate the identification of the subspaces as the solution of the generalized Sylvester equations, guiding us to select the most relevant samples from the training set to achieve our goals. Consequently, we construct solutions of the matrix equations in low-rank forms, which encode subspace information. We extensively discuss computational aspects and efficient usage of the low-rank factors in the process of obtaining reduced-order models. We illustrate the proposed active sampling scheme to obtain reduced-order models via dominant reachable and observable subspaces and present its comparison with the method where all the points from the training set are taken into account. It is shown that the active sample strategy can provide us $17$x speed-up without sacrificing any noticeable accuracy.
Divergence-free neural operators for stress field modeling in polycrystalline materials
Aug 27, 2024The purpose of the current work is the development and comparison of Fourier neural operators (FNOs) for surrogate modeling of the quasi-static mechanical response of polycrystalline materials. Three types of such FNOs are considered here: a physics-guided FNO (PgFNO), a physics-informed FNO (PiFNO), and a physics-encoded FNO (PeFNO). These are trained and compared with the help of stress field data from a reference model for heterogeneous elastic materials with a periodic grain microstructure. Whereas PgFNO training is based solely on these data, that of the PiFNO and PeFNO is in addition constrained by the requirement that stress fields satisfy mechanical equilibrium, i.e., be divergence-free. The difference between the PiFNO and PeFNO lies in how this constraint is taken into account; in the PiFNO, it is included in the loss function, whereas in the PeFNO, it is "encoded" in the operator architecture. In the current work, this encoding is based on a stress potential and Fourier transforms. As a result, only the training of the PiFNO is constrained by mechanical equilibrium; in contrast, mechanical equilibrium constrains both the training and output of the PeFNO. Due in particular to this, stress fields calculated by the trained PeFNO are significantly more accurate than those calculated by the trained PiFNO in the example cases considered.
GN-SINDy: Greedy Sampling Neural Network in Sparse Identification of Nonlinear Partial Differential Equations
May 14, 2024



The sparse identification of nonlinear dynamical systems (SINDy) is a data-driven technique employed for uncovering and representing the fundamental dynamics of intricate systems based on observational data. However, a primary obstacle in the discovery of models for nonlinear partial differential equations (PDEs) lies in addressing the challenges posed by the curse of dimensionality and large datasets. Consequently, the strategic selection of the most informative samples within a given dataset plays a crucial role in reducing computational costs and enhancing the effectiveness of SINDy-based algorithms. To this aim, we employ a greedy sampling approach to the snapshot matrix of a PDE to obtain its valuable samples, which are suitable to train a deep neural network (DNN) in a SINDy framework. SINDy based algorithms often consist of a data collection unit, constructing a dictionary of basis functions, computing the time derivative, and solving a sparse identification problem which ends to regularised least squares minimization. In this paper, we extend the results of a SINDy based deep learning model discovery (DeePyMoD) approach by integrating greedy sampling technique in its data collection unit and new sparsity promoting algorithms in the least squares minimization unit. In this regard we introduce the greedy sampling neural network in sparse identification of nonlinear partial differential equations (GN-SINDy) which blends a greedy sampling method, the DNN, and the SINDy algorithm. In the implementation phase, to show the effectiveness of GN-SINDy, we compare its results with DeePyMoD by using a Python package that is prepared for this purpose on numerous PDE discovery
Stability-Certified Learning of Control Systems with Quadratic Nonlinearities
Mar 01, 2024This work primarily focuses on an operator inference methodology aimed at constructing low-dimensional dynamical models based on a priori hypotheses about their structure, often informed by established physics or expert insights. Stability is a fundamental attribute of dynamical systems, yet it is not always assured in models derived through inference. Our main objective is to develop a method that facilitates the inference of quadratic control dynamical systems with inherent stability guarantees. To this aim, we investigate the stability characteristics of control systems with energy-preserving nonlinearities, thereby identifying conditions under which such systems are bounded-input bounded-state stable. These insights are subsequently applied to the learning process, yielding inferred models that are inherently stable by design. The efficacy of our proposed framework is demonstrated through a couple of numerical examples.