 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashLips: 100-FPS Mask-Free Latent Lip-Sync using Reconstruction Instead of Diffusion or GANs
Dec 23, 2025We present FlashLips, a two-stage, mask-free lip-sync system that decouples lips control from rendering and achieves real-time performance running at over 100 FPS on a single GPU, while matching the visual quality of larger state-of-the-art models. Stage 1 is a compact, one-step latent-space editor that reconstructs an image using a reference identity, a masked target frame, and a low-dimensional lips-pose vector, trained purely with reconstruction losses - no GANs or diffusion. To remove explicit masks at inference, we use self-supervision: we generate mouth-altered variants of the target image, that serve as pseudo ground truth for fine-tuning, teaching the network to localize edits to the lips while preserving the rest. Stage 2 is an audio-to-pose transformer trained with a flow-matching objective to predict lips-poses vectors from speech. Together, these stages form a simple and stable pipeline that combines deterministic reconstruction with robust audio control, delivering high perceptual quality and faster-than-real-time speed.
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Mar 03, 2025Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Apr 29, 2024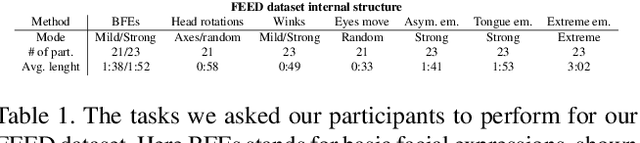
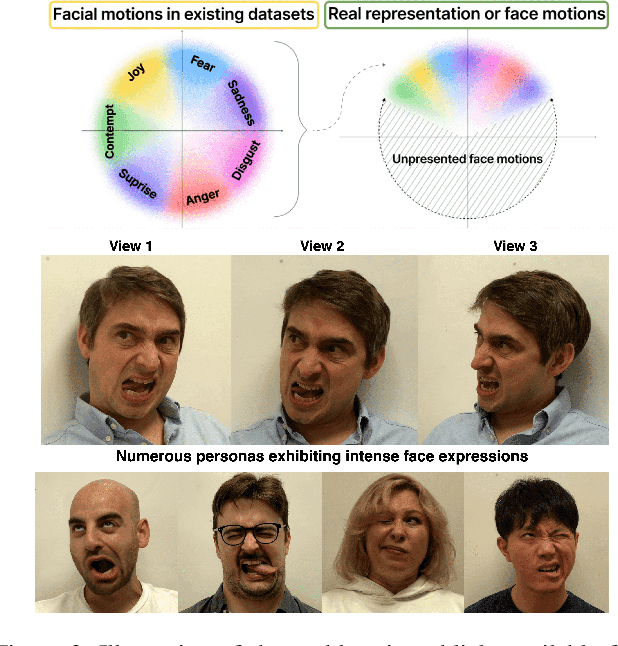
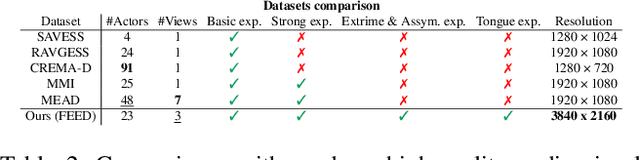
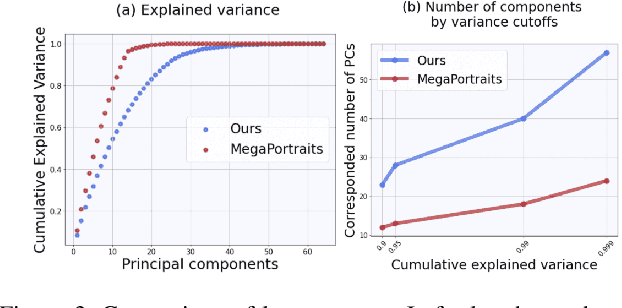
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
Laughing Matters: Introducing Laughing-Face Generation using Diffusion Models
May 15, 2023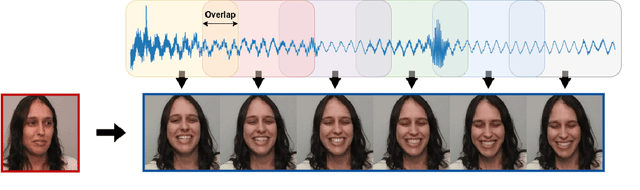
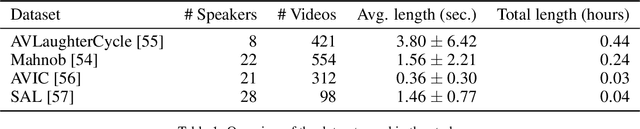
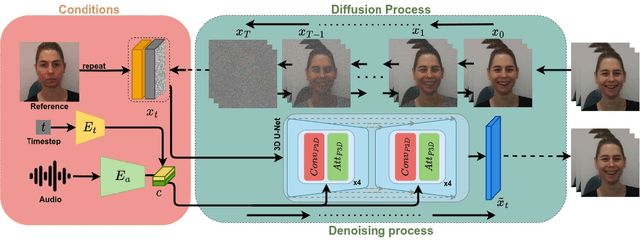
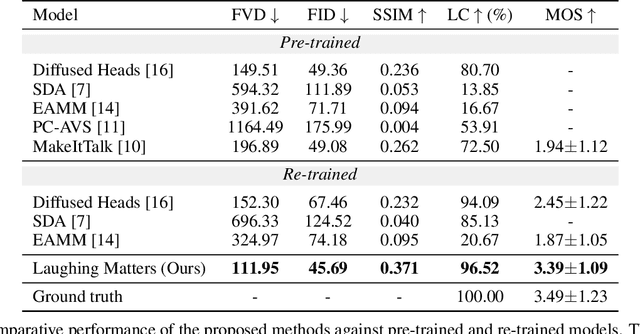
Speech-driven animation has gained significant traction in recent years, with current methods achieving near-photorealistic results. However, the field remains underexplored regarding non-verbal communication despite evidence demonstrating its importance in human interaction. In particular, generating laughter sequences presents a unique challenge due to the intricacy and nuances of this behaviour. This paper aims to bridge this gap by proposing a novel model capable of generating realistic laughter sequences, given a still portrait and an audio clip containing laughter. We highlight the failure cases of traditional facial animation methods and leverage recent advances in diffusion models to produce convincing laughter videos. We train our model on a diverse set of laughter datasets and introduce an evaluation metric specifically designed for laughter. When compared with previous speech-driven approaches, our model achieves state-of-the-art performance across all metrics, even when these are re-trained for laughter generation.
MegaPortraits: One-shot Megapixel Neural Head Avatars
Jul 15, 2022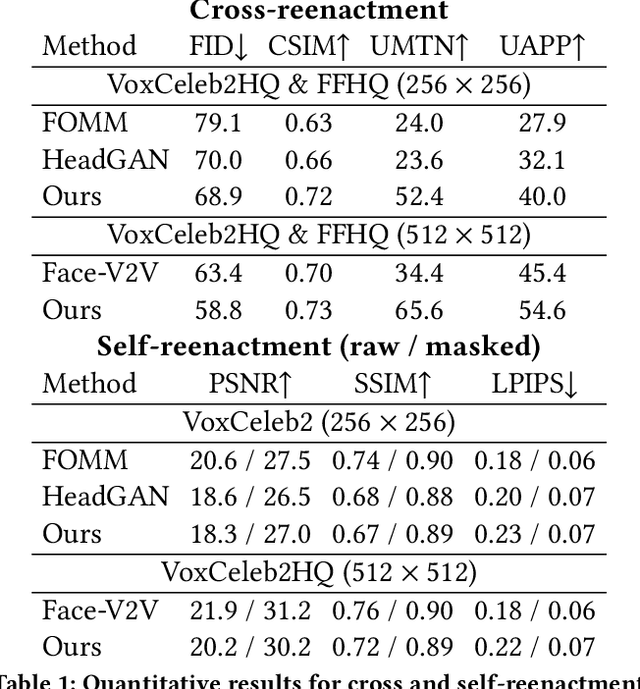
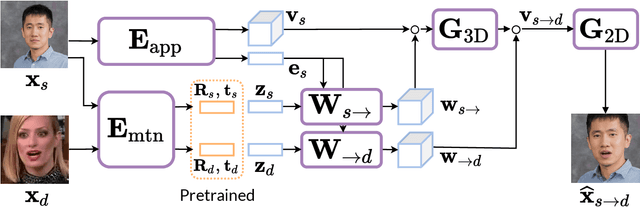
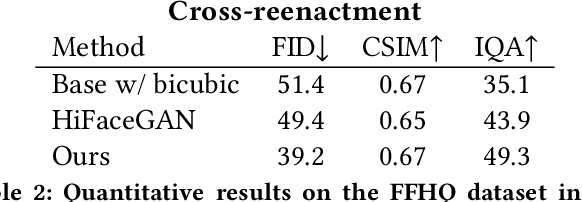

In this work, we advance the neural head avatar technology to the megapixel resolution while focusing on the particularly challenging task of cross-driving synthesis, i.e., when the appearance of the driving image is substantially different from the animated source image. We propose a set of new neural architectures and training methods that can leverage both medium-resolution video data and high-resolution image data to achieve the desired levels of rendered image quality and generalization to novel views and motion. We demonstrate that suggested architectures and methods produce convincing high-resolution neural avatars, outperforming the competitors in the cross-driving scenario. Lastly, we show how a trained high-resolution neural avatar model can be distilled into a lightweight student model which runs in real-time and locks the identities of neural avatars to several dozens of pre-defined source images. Real-time operation and identity lock are essential for many practical applications head avatar systems.
Towards Unpaired Depth Enhancement and Super-Resolution in the Wild
May 25, 2021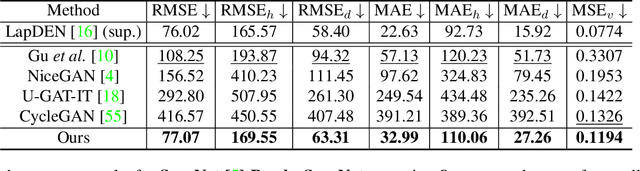
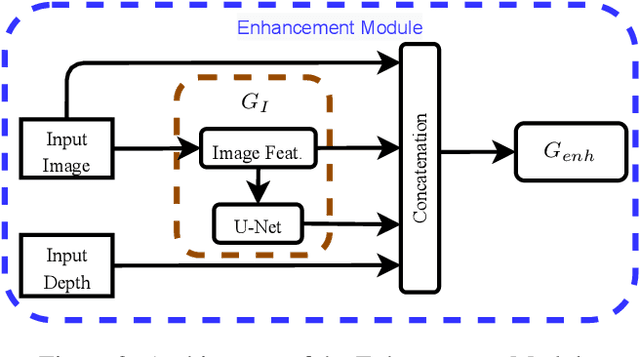
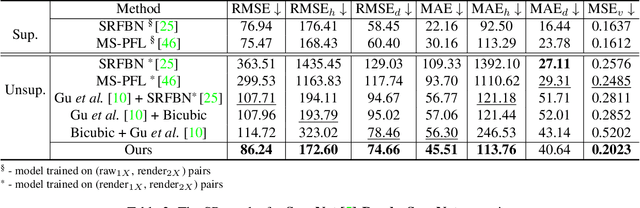
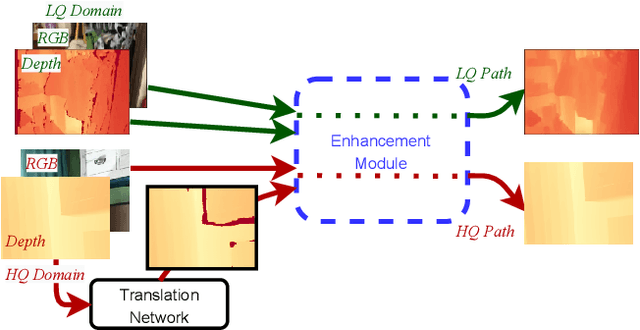
Depth maps captured with commodity sensors are often of low quality and resolution; these maps need to be enhanced to be used in many applications. State-of-the-art data-driven methods of depth map super-resolution rely on registered pairs of low- and high-resolution depth maps of the same scenes. Acquisition of real-world paired data requires specialized setups. Another alternative, generating low-resolution maps from high-resolution maps by subsampling, adding noise and other artificial degradation methods, does not fully capture the characteristics of real-world low-resolution images. As a consequence, supervised learning methods trained on such artificial paired data may not perform well on real-world low-resolution inputs. We consider an approach to depth map enhancement based on learning from unpaired data. While many techniques for unpaired image-to-image translation have been proposed, most are not directly applicable to depth maps. We propose an unpaired learning method for simultaneous depth enhancement and super-resolution, which is based on a learnable degradation model and surface normal estimates as features to produce more accurate depth maps. We demonstrate that our method outperforms existing unpaired methods and performs on par with paired methods on a new benchmark for unpaired learning that we developed.
Interpretable Deep Learning for Pattern Recognition in Brain Differences Between Men and Women
Jun 20, 2020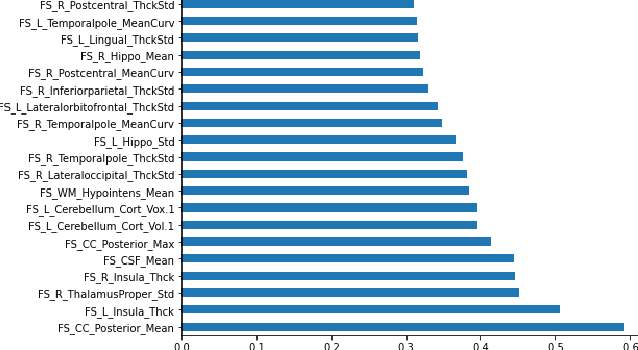

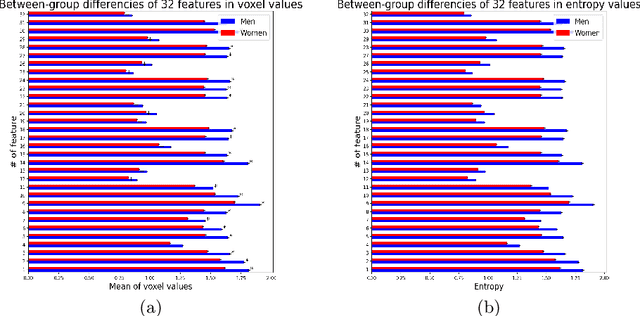
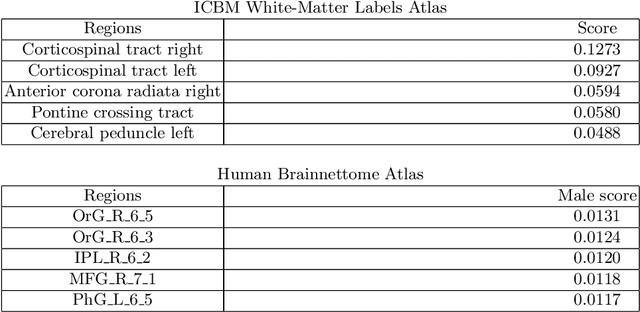
Deep learning shows high potential for many medical image analysis tasks. Neural networks work with full-size data without extensive preprocessing and feature generation and, thus, information loss. Recent work has shown that morphological difference between specific brain regions can be found on MRI with deep learning techniques. We consider the pattern recognition task based on a large open-access dataset of healthy subjects - an exploration of brain differences between men and women. However, interpretation of the lately proposed models is based on a region of interest and can not be extended to pixel or voxel-wise image interpretation, which is considered to be more informative. In this paper, we confirm the previous findings in sex differences from diffusion-tensor imaging on T1 weighted brain MRI scans. We compare the results of three voxel-based 3D CNN interpretation methods: Meaningful Perturbations, GradCam and Guided Backpropagation and provide the open-source code.