 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeySync: A Robust Approach for Leakage-free Lip Synchronization in High Resolution
May 01, 2025Lip synchronization, known as the task of aligning lip movements in an existing video with new input audio, is typically framed as a simpler variant of audio-driven facial animation. However, as well as suffering from the usual issues in talking head generation (e.g., temporal consistency), lip synchronization presents significant new challenges such as expression leakage from the input video and facial occlusions, which can severely impact real-world applications like automated dubbing, but are often neglected in existing works. To address these shortcomings, we present KeySync, a two-stage framework that succeeds in solving the issue of temporal consistency, while also incorporating solutions for leakage and occlusions using a carefully designed masking strategy. We show that KeySync achieves state-of-the-art results in lip reconstruction and cross-synchronization, improving visual quality and reducing expression leakage according to LipLeak, our novel leakage metric. Furthermore, we demonstrate the effectiveness of our new masking approach in handling occlusions and validate our architectural choices through several ablation studies. Code and model weights can be found at https://antonibigata.github.io/KeySync.
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Mar 03, 2025Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
DiffusionAct: Controllable Diffusion Autoencoder for One-shot Face Reenactment
Mar 25, 2024



Video-driven neural face reenactment aims to synthesize realistic facial images that successfully preserve the identity and appearance of a source face, while transferring the target head pose and facial expressions. Existing GAN-based methods suffer from either distortions and visual artifacts or poor reconstruction quality, i.e., the background and several important appearance details, such as hair style/color, glasses and accessories, are not faithfully reconstructed. Recent advances in Diffusion Probabilistic Models (DPMs) enable the generation of high-quality realistic images. To this end, in this paper we present DiffusionAct, a novel method that leverages the photo-realistic image generation of diffusion models to perform neural face reenactment. Specifically, we propose to control the semantic space of a Diffusion Autoencoder (DiffAE), in order to edit the facial pose of the input images, defined as the head pose orientation and the facial expressions. Our method allows one-shot, self, and cross-subject reenactment, without requiring subject-specific fine-tuning. We compare against state-of-the-art GAN-, StyleGAN2-, and diffusion-based methods, showing better or on-par reenactment performance.
One-shot Neural Face Reenactment via Finding Directions in GAN's Latent Space
Feb 05, 2024



In this paper, we present our framework for neural face/head reenactment whose goal is to transfer the 3D head orientation and expression of a target face to a source face. Previous methods focus on learning embedding networks for identity and head pose/expression disentanglement which proves to be a rather hard task, degrading the quality of the generated images. We take a different approach, bypassing the training of such networks, by using (fine-tuned) pre-trained GANs which have been shown capable of producing high-quality facial images. Because GANs are characterized by weak controllability, the core of our approach is a method to discover which directions in latent GAN space are responsible for controlling head pose and expression variations. We present a simple pipeline to learn such directions with the aid of a 3D shape model which, by construction, inherently captures disentangled directions for head pose, identity, and expression. Moreover, we show that by embedding real images in the GAN latent space, our method can be successfully used for the reenactment of real-world faces. Our method features several favorable properties including using a single source image (one-shot) and enabling cross-person reenactment. Extensive qualitative and quantitative results show that our approach typically produces reenacted faces of notably higher quality than those produced by state-of-the-art methods for the standard benchmarks of VoxCeleb1 & 2.
HyperReenact: One-Shot Reenactment via Jointly Learning to Refine and Retarget Faces
Jul 20, 2023



In this paper, we present our method for neural face reenactment, called HyperReenact, that aims to generate realistic talking head images of a source identity, driven by a target facial pose. Existing state-of-the-art face reenactment methods train controllable generative models that learn to synthesize realistic facial images, yet producing reenacted faces that are prone to significant visual artifacts, especially under the challenging condition of extreme head pose changes, or requiring expensive few-shot fine-tuning to better preserve the source identity characteristics. We propose to address these limitations by leveraging the photorealistic generation ability and the disentangled properties of a pretrained StyleGAN2 generator, by first inverting the real images into its latent space and then using a hypernetwork to perform: (i) refinement of the source identity characteristics and (ii) facial pose re-targeting, eliminating this way the dependence on external editing methods that typically produce artifacts. Our method operates under the one-shot setting (i.e., using a single source frame) and allows for cross-subject reenactment, without requiring any subject-specific fine-tuning. We compare our method both quantitatively and qualitatively against several state-of-the-art techniques on the standard benchmarks of VoxCeleb1 and VoxCeleb2, demonstrating the superiority of our approach in producing artifact-free images, exhibiting remarkable robustness even under extreme head pose changes. We make the code and the pretrained models publicly available at: https://github.com/StelaBou/HyperReenact .
StyleMask: Disentangling the Style Space of StyleGAN2 for Neural Face Reenactment
Sep 27, 2022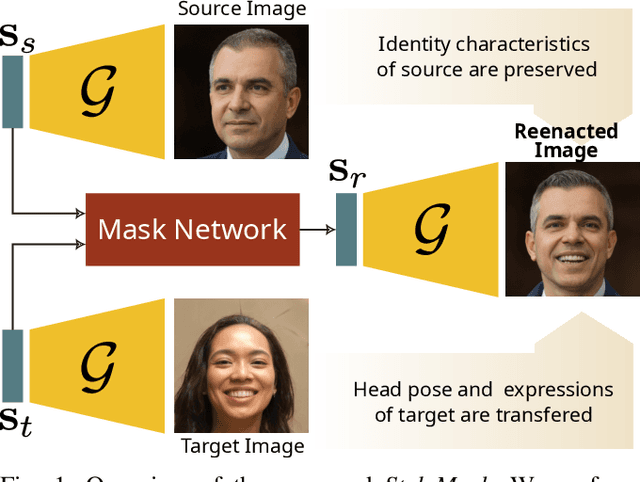



In this paper we address the problem of neural face reenactment, where, given a pair of a source and a target facial image, we need to transfer the target's pose (defined as the head pose and its facial expressions) to the source image, by preserving at the same time the source's identity characteristics (e.g., facial shape, hair style, etc), even in the challenging case where the source and the target faces belong to different identities. In doing so, we address some of the limitations of the state-of-the-art works, namely, a) that they depend on paired training data (i.e., source and target faces have the same identity), b) that they rely on labeled data during inference, and c) that they do not preserve identity in large head pose changes. More specifically, we propose a framework that, using unpaired randomly generated facial images, learns to disentangle the identity characteristics of the face from its pose by incorporating the recently introduced style space $\mathcal{S}$ of StyleGAN2, a latent representation space that exhibits remarkable disentanglement properties. By capitalizing on this, we learn to successfully mix a pair of source and target style codes using supervision from a 3D model. The resulting latent code, that is subsequently used for reenactment, consists of latent units corresponding to the facial pose of the target only and of units corresponding to the identity of the source only, leading to notable improvement in the reenactment performance compared to recent state-of-the-art methods. In comparison to state of the art, we quantitatively and qualitatively show that the proposed method produces higher quality results even on extreme pose variations. Finally, we report results on real images by first embedding them on the latent space of the pretrained generator. We make the code and pretrained models publicly available at: https://github.com/StelaBou/StyleMask
Finding Directions in GAN's Latent Space for Neural Face Reenactment
Jan 31, 2022
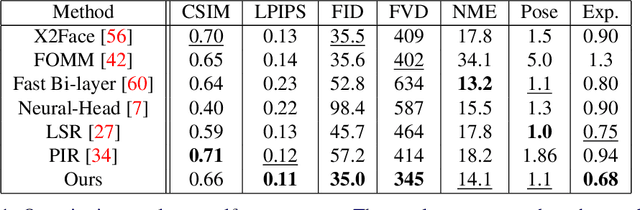
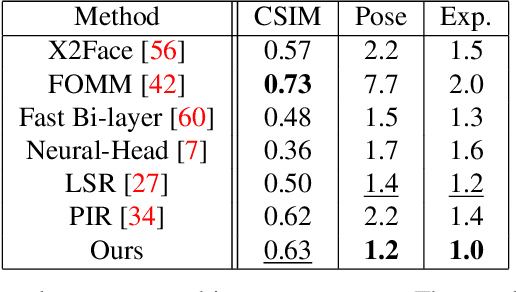

This paper is on face/head reenactment where the goal is to transfer the facial pose (3D head orientation and expression) of a target face to a source face. Previous methods focus on learning embedding networks for identity and pose disentanglement which proves to be a rather hard task, degrading the quality of the generated images. We take a different approach, bypassing the training of such networks, by using (fine-tuned) pre-trained GANs which have been shown capable of producing high-quality facial images. Because GANs are characterized by weak controllability, the core of our approach is a method to discover which directions in latent GAN space are responsible for controlling facial pose and expression variations. We present a simple pipeline to learn such directions with the aid of a 3D shape model which, by construction, already captures disentangled directions for facial pose, identity and expression. Moreover, we show that by embedding real images in the GAN latent space, our method can be successfully used for the reenactment of real-world faces. Our method features several favorable properties including using a single source image (one-shot) and enabling cross-person reenactment. Our qualitative and quantitative results show that our approach often produces reenacted faces of significantly higher quality than those produced by state-of-the-art methods for the standard benchmarks of VoxCeleb1 & 2.