 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnHype: CLIP-Guided Hypernetworks for Dynamic LoRA Unlearning
Feb 03, 2026Recent advances in large-scale diffusion models have intensified concerns about their potential misuse, particularly in generating realistic yet harmful or socially disruptive content. This challenge has spurred growing interest in effective machine unlearning, the process of selectively removing specific knowledge or concepts from a model without compromising its overall generative capabilities. Among various approaches, Low-Rank Adaptation (LoRA) has emerged as an effective and efficient method for fine-tuning models toward targeted unlearning. However, LoRA-based methods often exhibit limited adaptability to concept semantics and struggle to balance removing closely related concepts with maintaining generalization across broader meanings. Moreover, these methods face scalability challenges when multiple concepts must be erased simultaneously. To address these limitations, we introduce UnHype, a framework that incorporates hypernetworks into single- and multi-concept LoRA training. The proposed architecture can be directly plugged into Stable Diffusion as well as modern flow-based text-to-image models, where it demonstrates stable training behavior and effective concept control. During inference, the hypernetwork dynamically generates adaptive LoRA weights based on the CLIP embedding, enabling more context-aware, scalable unlearning. We evaluate UnHype across several challenging tasks, including object erasure, celebrity erasure, and explicit content removal, demonstrating its effectiveness and versatility. Repository: https://github.com/gmum/UnHype.
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Mar 03, 2025Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
Two-headed eye-segmentation approach for biometric identification
Sep 30, 2022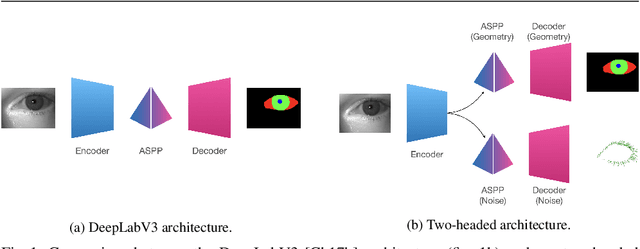
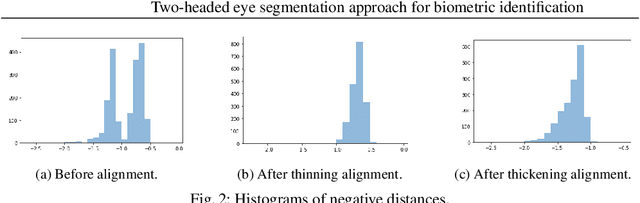
Iris-based identification systems are among the most popular approaches for person identification. Such systems require good-quality segmentation modules that ideally identify the regions for different eye components. This paper introduces the new two-headed architecture, where the eye components and eyelashes are segmented using two separate decoding modules. Moreover, we investigate various training scenarios by adopting different training losses. Thanks to the two-headed approach, we were also able to examine the quality of the model with the convex prior, which enforces the convexity of the segmented shapes. We conducted an extensive evaluation of various learning scenarios on real-life conditions high-resolution near-infrared iris images.
BinGAN: Learning Compact Binary Descriptors with a Regularized GAN
Nov 06, 2018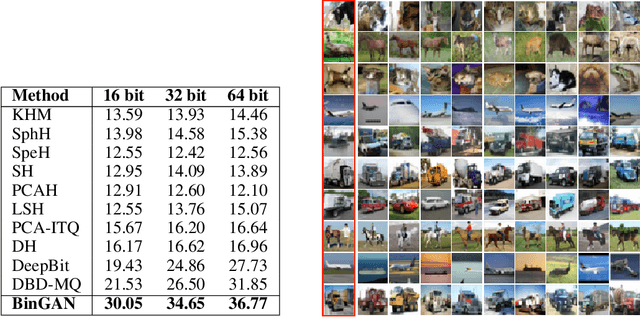
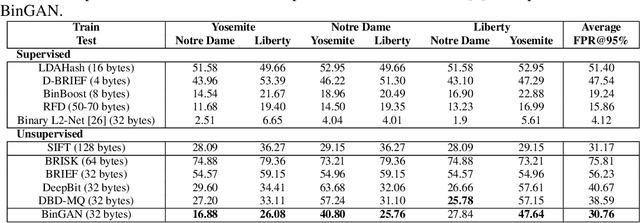


In this paper, we propose a novel regularization method for Generative Adversarial Networks, which allows the model to learn discriminative yet compact binary representations of image patches (image descriptors). We employ the dimensionality reduction that takes place in the intermediate layers of the discriminator network and train binarized low-dimensional representation of the penultimate layer to mimic the distribution of the higher-dimensional preceding layers. To achieve this, we introduce two loss terms that aim at: (i) reducing the correlation between the dimensions of the binarized low-dimensional representation of the penultimate layer i. e. maximizing joint entropy) and (ii) propagating the relations between the dimensions in the high-dimensional space to the low-dimensional space. We evaluate the resulting binary image descriptors on two challenging applications, image matching and retrieval, and achieve state-of-the-art results.
Training Triplet Networks with GAN
Apr 06, 2017Triplet networks are widely used models that are characterized by good performance in classification and retrieval tasks. In this work we propose to train a triplet network by putting it as the discriminator in Generative Adversarial Nets (GANs). We make use of the good capability of representation learning of the discriminator to increase the predictive quality of the model. We evaluated our approach on Cifar10 and MNIST datasets and observed significant improvement on the classification performance using the simple k-nn method.