 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeySync: A Robust Approach for Leakage-free Lip Synchronization in High Resolution
May 01, 2025Lip synchronization, known as the task of aligning lip movements in an existing video with new input audio, is typically framed as a simpler variant of audio-driven facial animation. However, as well as suffering from the usual issues in talking head generation (e.g., temporal consistency), lip synchronization presents significant new challenges such as expression leakage from the input video and facial occlusions, which can severely impact real-world applications like automated dubbing, but are often neglected in existing works. To address these shortcomings, we present KeySync, a two-stage framework that succeeds in solving the issue of temporal consistency, while also incorporating solutions for leakage and occlusions using a carefully designed masking strategy. We show that KeySync achieves state-of-the-art results in lip reconstruction and cross-synchronization, improving visual quality and reducing expression leakage according to LipLeak, our novel leakage metric. Furthermore, we demonstrate the effectiveness of our new masking approach in handling occlusions and validate our architectural choices through several ablation studies. Code and model weights can be found at https://antonibigata.github.io/KeySync.
Contextual Speech Extraction: Leveraging Textual History as an Implicit Cue for Target Speech Extraction
Mar 11, 2025



In this paper, we investigate a novel approach for Target Speech Extraction (TSE), which relies solely on textual context to extract the target speech. We refer to this task as Contextual Speech Extraction (CSE). Unlike traditional TSE methods that rely on pre-recorded enrollment utterances, video of the target speaker's face, spatial information, or other explicit cues to identify the target stream, our proposed method requires only a few turns of previous dialogue (or monologue) history. This approach is naturally feasible in mobile messaging environments where voice recordings are typically preceded by textual dialogue that can be leveraged implicitly. We present three CSE models and analyze their performances on three datasets. Through our experiments, we demonstrate that even when the model relies purely on dialogue history, it can achieve over 90 % accuracy in identifying the correct target stream with only two previous dialogue turns. Furthermore, we show that by leveraging both textual context and enrollment utterances as cues during training, we further enhance our model's flexibility and effectiveness, allowing us to use either cue during inference, or combine both for improved performance. Samples and code available on https://miraodasilva.github.io/cse-project-page .
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Mar 03, 2025Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
Unified Speech Recognition: A Single Model for Auditory, Visual, and Audiovisual Inputs
Nov 04, 2024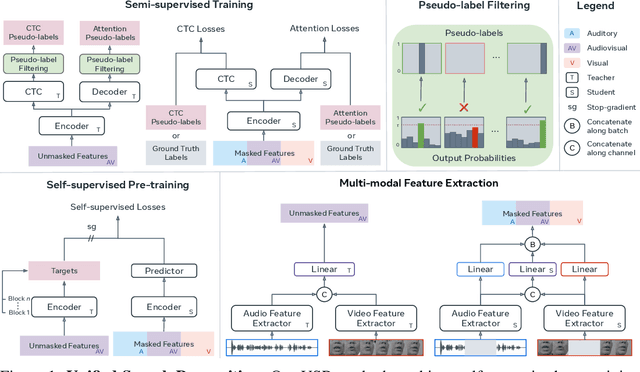

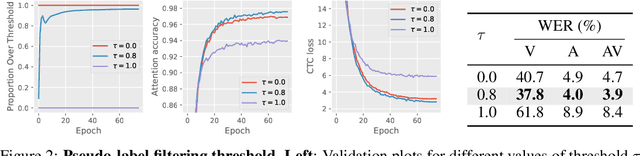
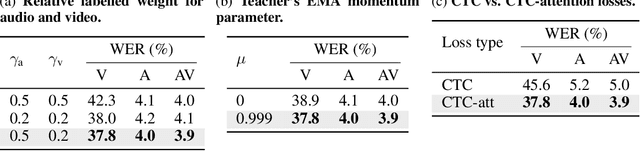
Research in auditory, visual, and audiovisual speech recognition (ASR, VSR, and AVSR, respectively) has traditionally been conducted independently. Even recent self-supervised studies addressing two or all three tasks simultaneously tend to yield separate models, leading to disjoint inference pipelines with increased memory requirements and redundancies. This paper proposes unified training strategies for these systems. We demonstrate that training a single model for all three tasks enhances VSR and AVSR performance, overcoming typical optimisation challenges when training from scratch. Moreover, we introduce a greedy pseudo-labelling approach to more effectively leverage unlabelled samples, addressing shortcomings in related self-supervised methods. Finally, we develop a self-supervised pre-training method within our framework, proving its effectiveness alongside our semi-supervised approach. Despite using a single model for all tasks, our unified approach achieves state-of-the-art performance compared to recent methods on LRS3 and LRS2 for ASR, VSR, and AVSR, as well as on the newly released WildVSR dataset. Code and models are available at https://github.com/ahaliassos/usr.
RT-LA-VocE: Real-Time Low-SNR Audio-Visual Speech Enhancement
Jul 10, 2024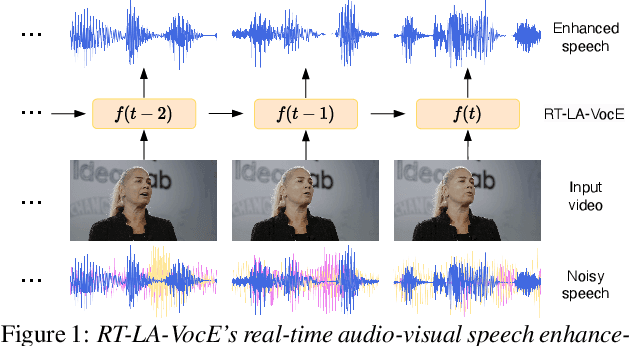

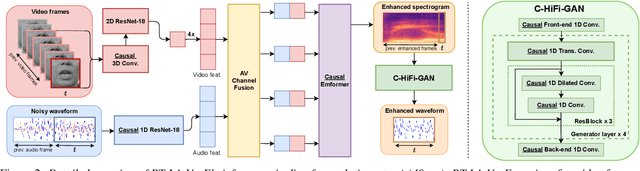

In this paper, we aim to generate clean speech frame by frame from a live video stream and a noisy audio stream without relying on future inputs. To this end, we propose RT-LA-VocE, which completely re-designs every component of LA-VocE, a state-of-the-art non-causal audio-visual speech enhancement model, to perform causal real-time inference with a 40ms input frame. We do so by devising new visual and audio encoders that rely solely on past frames, replacing the Transformer encoder with the Emformer, and designing a new causal neural vocoder C-HiFi-GAN. On the popular AVSpeech dataset, we show that our algorithm achieves state-of-the-art results in all real-time scenarios. More importantly, each component is carefully tuned to minimize the algorithm latency to the theoretical minimum (40ms) while maintaining a low end-to-end processing latency of 28.15ms per frame, enabling real-time frame-by-frame enhancement with minimal delay.
BRAVEn: Improving Self-Supervised Pre-training for Visual and Auditory Speech Recognition
Apr 02, 2024Self-supervision has recently shown great promise for learning visual and auditory speech representations from unlabelled data. In this work, we propose BRAVEn, an extension to the recent RAVEn method, which learns speech representations entirely from raw audio-visual data. Our modifications to RAVEn enable BRAVEn to achieve state-of-the-art results among self-supervised methods in various settings. Moreover, we observe favourable scaling behaviour by increasing the amount of unlabelled data well beyond other self-supervised works. In particular, we achieve 20.0% / 1.7% word error rate for VSR / ASR on the LRS3 test set, with only 30 hours of labelled data and no external ASR models. Our results suggest that readily available unlabelled audio-visual data can largely replace costly transcribed data.
Laughing Matters: Introducing Laughing-Face Generation using Diffusion Models
May 15, 2023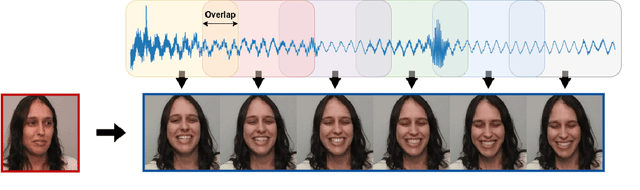
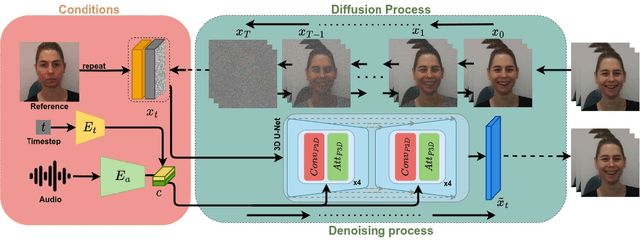
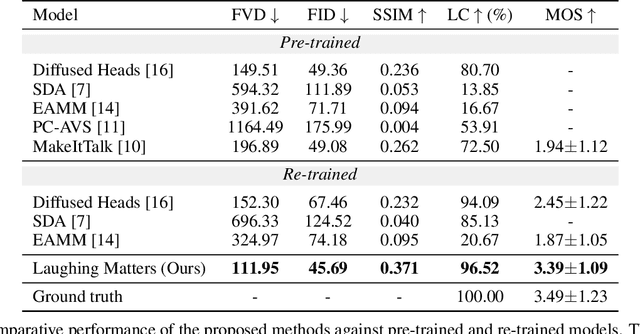
Speech-driven animation has gained significant traction in recent years, with current methods achieving near-photorealistic results. However, the field remains underexplored regarding non-verbal communication despite evidence demonstrating its importance in human interaction. In particular, generating laughter sequences presents a unique challenge due to the intricacy and nuances of this behaviour. This paper aims to bridge this gap by proposing a novel model capable of generating realistic laughter sequences, given a still portrait and an audio clip containing laughter. We highlight the failure cases of traditional facial animation methods and leverage recent advances in diffusion models to produce convincing laughter videos. We train our model on a diverse set of laughter datasets and introduce an evaluation metric specifically designed for laughter. When compared with previous speech-driven approaches, our model achieves state-of-the-art performance across all metrics, even when these are re-trained for laughter generation.
Jointly Learning Visual and Auditory Speech Representations from Raw Data
Dec 12, 2022We present RAVEn, a self-supervised multi-modal approach to jointly learn visual and auditory speech representations. Our pre-training objective involves encoding masked inputs, and then predicting contextualised targets generated by slowly-evolving momentum encoders. Driven by the inherent differences between video and audio, our design is asymmetric w.r.t. the two modalities' pretext tasks: Whereas the auditory stream predicts both the visual and auditory targets, the visual one predicts only the auditory targets. We observe strong results in low- and high-resource labelled data settings when fine-tuning the visual and auditory encoders resulting from a single pre-training stage, in which the encoders are jointly trained. Notably, RAVEn surpasses all self-supervised methods on visual speech recognition (VSR) on LRS3, and combining RAVEn with self-training using only 30 hours of labelled data even outperforms a recent semi-supervised method trained on 90,000 hours of non-public data. At the same time, we achieve state-of-the-art results in the LRS3 low-resource setting for auditory speech recognition (as well as for VSR). Our findings point to the viability of learning powerful speech representations entirely from raw video and audio, i.e., without relying on handcrafted features. Code and models will be made public.
LA-VocE: Low-SNR Audio-visual Speech Enhancement using Neural Vocoders
Nov 20, 2022Audio-visual speech enhancement aims to extract clean speech from a noisy environment by leveraging not only the audio itself but also the target speaker's lip movements. This approach has been shown to yield improvements over audio-only speech enhancement, particularly for the removal of interfering speech. Despite recent advances in speech synthesis, most audio-visual approaches continue to use spectral mapping/masking to reproduce the clean audio, often resulting in visual backbones added to existing speech enhancement architectures. In this work, we propose LA-VocE, a new two-stage approach that predicts mel-spectrograms from noisy audio-visual speech via a transformer-based architecture, and then converts them into waveform audio using a neural vocoder (HiFi-GAN). We train and evaluate our framework on thousands of speakers and 11+ different languages, and study our model's ability to adapt to different levels of background noise and speech interference. Our experiments show that LA-VocE outperforms existing methods according to multiple metrics, particularly under very noisy scenarios.
SVTS: Scalable Video-to-Speech Synthesis
May 04, 2022
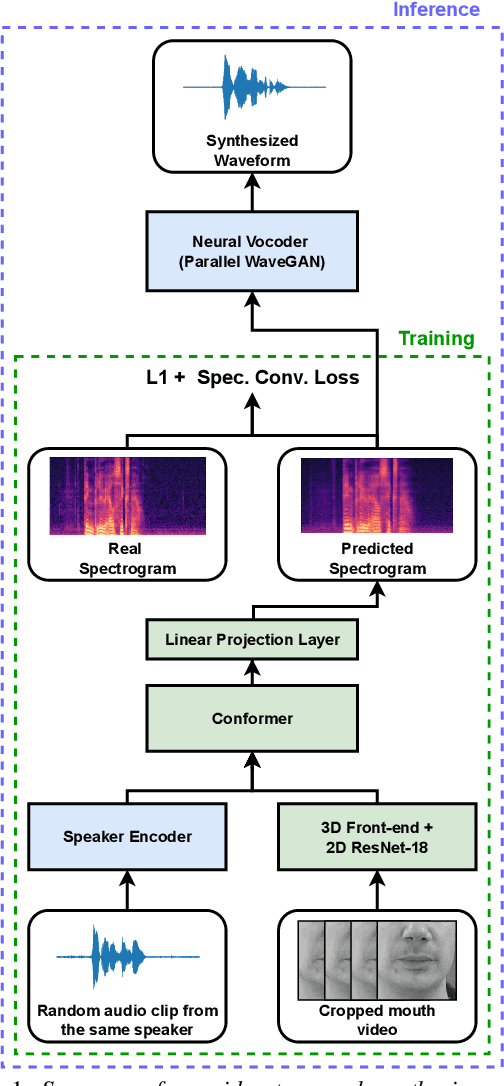
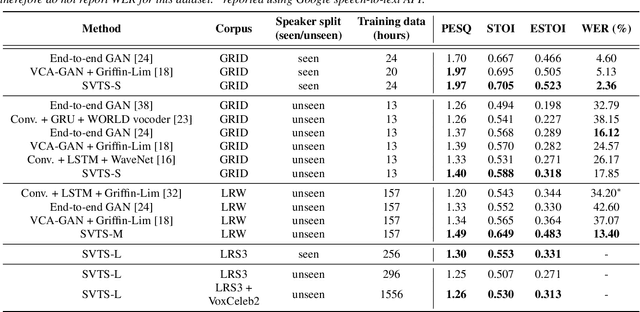

Video-to-speech synthesis (also known as lip-to-speech) refers to the translation of silent lip movements into the corresponding audio. This task has received an increasing amount of attention due to its self-supervised nature (i.e., can be trained without manual labelling) combined with the ever-growing collection of audio-visual data available online. Despite these strong motivations, contemporary video-to-speech works focus mainly on small- to medium-sized corpora with substantial constraints in both vocabulary and setting. In this work, we introduce a scalable video-to-speech framework consisting of two components: a video-to-spectrogram predictor and a pre-trained neural vocoder, which converts the mel-frequency spectrograms into waveform audio. We achieve state-of-the art results for GRID and considerably outperform previous approaches on LRW. More importantly, by focusing on spectrogram prediction using a simple feedforward model, we can efficiently and effectively scale our method to very large and unconstrained datasets: To the best of our knowledge, we are the first to show intelligible results on the challenging LRS3 dataset.