 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashLips: 100-FPS Mask-Free Latent Lip-Sync using Reconstruction Instead of Diffusion or GANs
Dec 23, 2025We present FlashLips, a two-stage, mask-free lip-sync system that decouples lips control from rendering and achieves real-time performance running at over 100 FPS on a single GPU, while matching the visual quality of larger state-of-the-art models. Stage 1 is a compact, one-step latent-space editor that reconstructs an image using a reference identity, a masked target frame, and a low-dimensional lips-pose vector, trained purely with reconstruction losses - no GANs or diffusion. To remove explicit masks at inference, we use self-supervision: we generate mouth-altered variants of the target image, that serve as pseudo ground truth for fine-tuning, teaching the network to localize edits to the lips while preserving the rest. Stage 2 is an audio-to-pose transformer trained with a flow-matching objective to predict lips-poses vectors from speech. Together, these stages form a simple and stable pipeline that combines deterministic reconstruction with robust audio control, delivering high perceptual quality and faster-than-real-time speed.
BRAVEn: Improving Self-Supervised Pre-training for Visual and Auditory Speech Recognition
Apr 02, 2024Self-supervision has recently shown great promise for learning visual and auditory speech representations from unlabelled data. In this work, we propose BRAVEn, an extension to the recent RAVEn method, which learns speech representations entirely from raw audio-visual data. Our modifications to RAVEn enable BRAVEn to achieve state-of-the-art results among self-supervised methods in various settings. Moreover, we observe favourable scaling behaviour by increasing the amount of unlabelled data well beyond other self-supervised works. In particular, we achieve 20.0% / 1.7% word error rate for VSR / ASR on the LRS3 test set, with only 30 hours of labelled data and no external ASR models. Our results suggest that readily available unlabelled audio-visual data can largely replace costly transcribed data.
Learning Cross-lingual Visual Speech Representations
Mar 14, 2023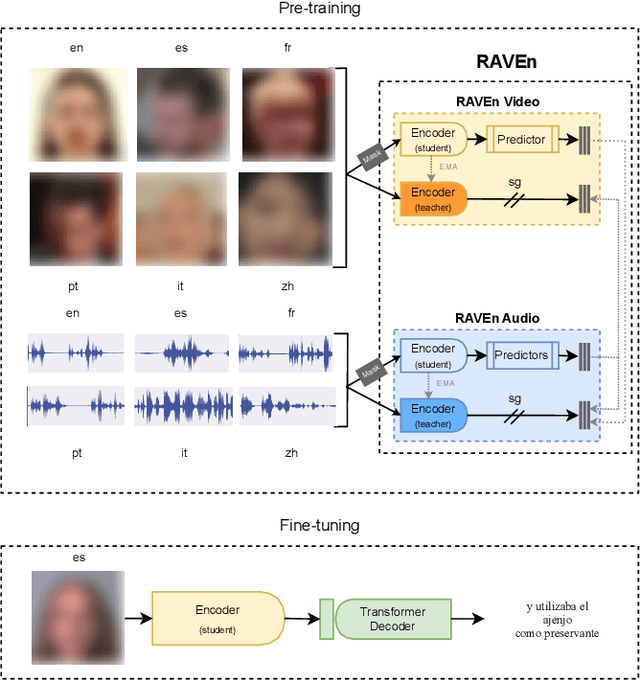



Cross-lingual self-supervised learning has been a growing research topic in the last few years. However, current works only explored the use of audio signals to create representations. In this work, we study cross-lingual self-supervised visual representation learning. We use the recently-proposed Raw Audio-Visual Speech Encoders (RAVEn) framework to pre-train an audio-visual model with unlabelled multilingual data, and then fine-tune the visual model on labelled transcriptions. Our experiments show that: (1) multi-lingual models with more data outperform monolingual ones, but, when keeping the amount of data fixed, monolingual models tend to reach better performance; (2) multi-lingual outperforms English-only pre-training; (3) using languages which are more similar yields better results; and (4) fine-tuning on unseen languages is competitive to using the target language in the pre-training set. We hope our study inspires future research on non-English-only speech representation learning.