 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-lingual Visual Speech Representations
Paper and Code
Mar 14, 2023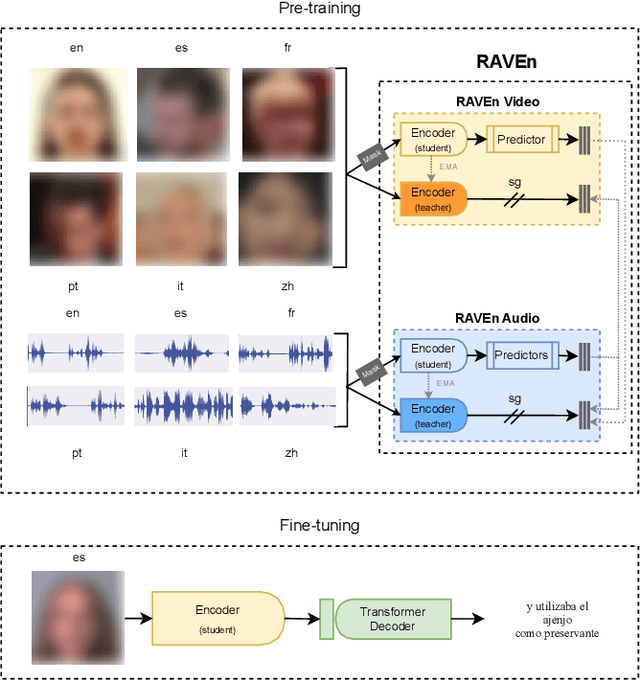



Cross-lingual self-supervised learning has been a growing research topic in the last few years. However, current works only explored the use of audio signals to create representations. In this work, we study cross-lingual self-supervised visual representation learning. We use the recently-proposed Raw Audio-Visual Speech Encoders (RAVEn) framework to pre-train an audio-visual model with unlabelled multilingual data, and then fine-tune the visual model on labelled transcriptions. Our experiments show that: (1) multi-lingual models with more data outperform monolingual ones, but, when keeping the amount of data fixed, monolingual models tend to reach better performance; (2) multi-lingual outperforms English-only pre-training; (3) using languages which are more similar yields better results; and (4) fine-tuning on unseen languages is competitive to using the target language in the pre-training set. We hope our study inspires future research on non-English-only speech representation learning.