 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Speech Recognition: A Single Model for Auditory, Visual, and Audiovisual Inputs
Paper and Code
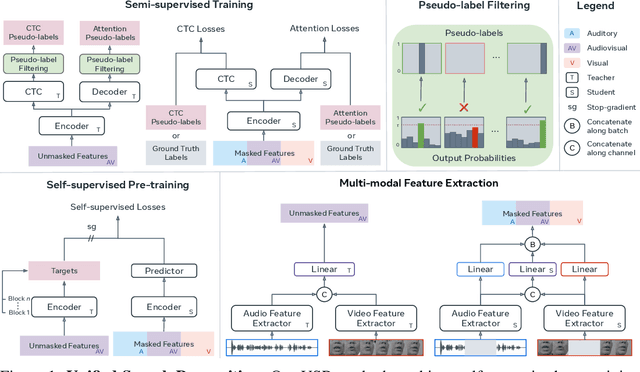

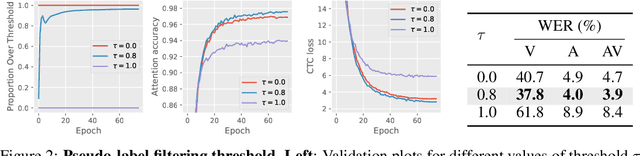
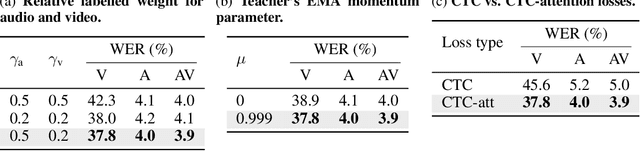
Research in auditory, visual, and audiovisual speech recognition (ASR, VSR, and AVSR, respectively) has traditionally been conducted independently. Even recent self-supervised studies addressing two or all three tasks simultaneously tend to yield separate models, leading to disjoint inference pipelines with increased memory requirements and redundancies. This paper proposes unified training strategies for these systems. We demonstrate that training a single model for all three tasks enhances VSR and AVSR performance, overcoming typical optimisation challenges when training from scratch. Moreover, we introduce a greedy pseudo-labelling approach to more effectively leverage unlabelled samples, addressing shortcomings in related self-supervised methods. Finally, we develop a self-supervised pre-training method within our framework, proving its effectiveness alongside our semi-supervised approach. Despite using a single model for all tasks, our unified approach achieves state-of-the-art performance compared to recent methods on LRS3 and LRS2 for ASR, VSR, and AVSR, as well as on the newly released WildVSR dataset. Code and models are available at https://github.com/ahaliassos/usr.