 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRT-LA-VocE: Real-Time Low-SNR Audio-Visual Speech Enhancement
Paper and Code
Jul 10, 2024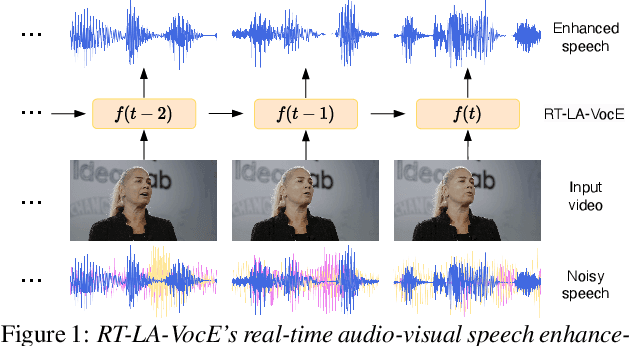

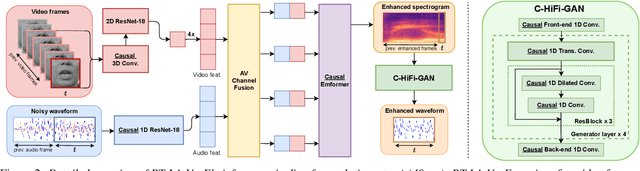

In this paper, we aim to generate clean speech frame by frame from a live video stream and a noisy audio stream without relying on future inputs. To this end, we propose RT-LA-VocE, which completely re-designs every component of LA-VocE, a state-of-the-art non-causal audio-visual speech enhancement model, to perform causal real-time inference with a 40ms input frame. We do so by devising new visual and audio encoders that rely solely on past frames, replacing the Transformer encoder with the Emformer, and designing a new causal neural vocoder C-HiFi-GAN. On the popular AVSpeech dataset, we show that our algorithm achieves state-of-the-art results in all real-time scenarios. More importantly, each component is carefully tuned to minimize the algorithm latency to the theoretical minimum (40ms) while maintaining a low end-to-end processing latency of 28.15ms per frame, enabling real-time frame-by-frame enhancement with minimal delay.