 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceCrafter: Identity-Conditional Diffusion with Disentangled Control over Facial Pose, Expression, and Emotion
May 21, 2025Human facial images encode a rich spectrum of information, encompassing both stable identity-related traits and mutable attributes such as pose, expression, and emotion. While recent advances in image generation have enabled high-quality identity-conditional face synthesis, precise control over non-identity attributes remains challenging, and disentangling identity from these mutable factors is particularly difficult. To address these limitations, we propose a novel identity-conditional diffusion model that introduces two lightweight control modules designed to independently manipulate facial pose, expression, and emotion without compromising identity preservation. These modules are embedded within the cross-attention layers of the base diffusion model, enabling precise attribute control with minimal parameter overhead. Furthermore, our tailored training strategy, which leverages cross-attention between the identity feature and each non-identity control feature, encourages identity features to remain orthogonal to control signals, enhancing controllability and diversity. Quantitative and qualitative evaluations, along with perceptual user studies, demonstrate that our method surpasses existing approaches in terms of control accuracy over pose, expression, and emotion, while also improving generative diversity under identity-only conditioning.
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Apr 29, 2024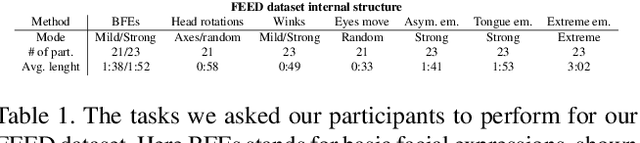
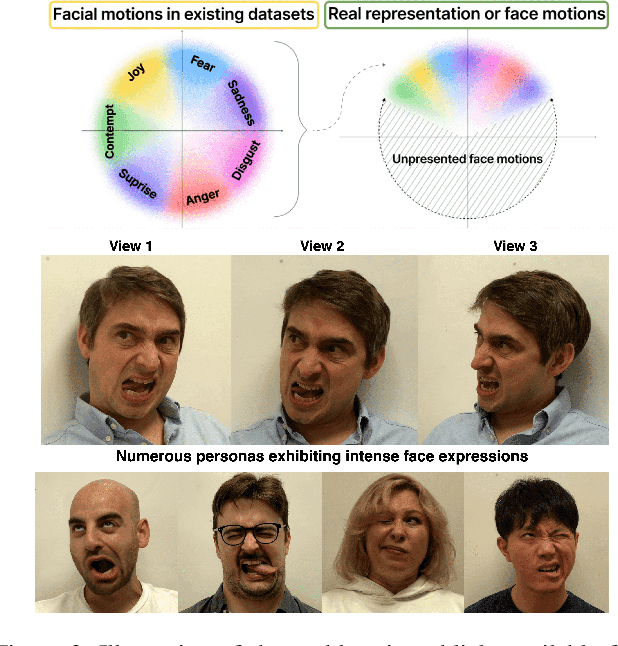
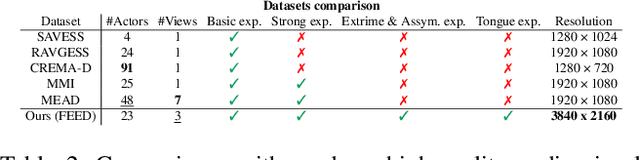
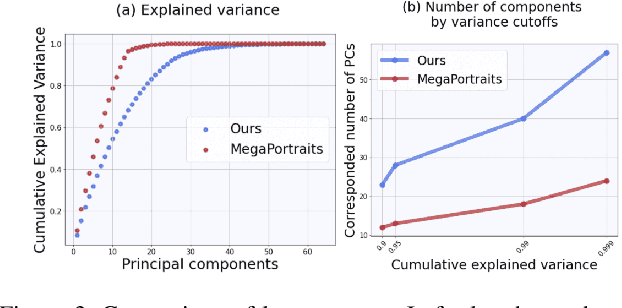
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
CroissantLLM: A Truly Bilingual French-English Language Model
Feb 02, 2024



We introduce CroissantLLM, a 1.3B language model pretrained on a set of 3T English and French tokens, to bring to the research and industrial community a high-performance, fully open-sourced bilingual model that runs swiftly on consumer-grade local hardware. To that end, we pioneer the approach of training an intrinsically bilingual model with a 1:1 English-to-French pretraining data ratio, a custom tokenizer, and bilingual finetuning datasets. We release the training dataset, notably containing a French split with manually curated, high-quality, and varied data sources. To assess performance outside of English, we craft a novel benchmark, FrenchBench, consisting of an array of classification and generation tasks, covering various orthogonal aspects of model performance in the French Language. Additionally, rooted in transparency and to foster further Large Language Model research, we release codebases, and dozens of checkpoints across various model sizes, training data distributions, and training steps, as well as fine-tuned Chat models, and strong translation models. We evaluate our model through the FMTI framework, and validate 81 % of the transparency criteria, far beyond the scores of even most open initiatives. This work enriches the NLP landscape, breaking away from previous English-centric work in order to strengthen our understanding of multilinguality in language models.
Laughing Matters: Introducing Laughing-Face Generation using Diffusion Models
May 15, 2023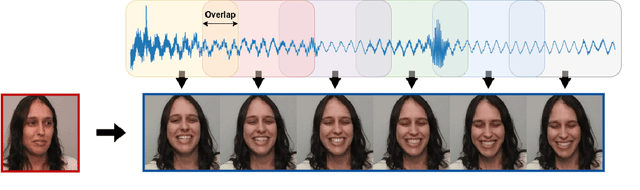
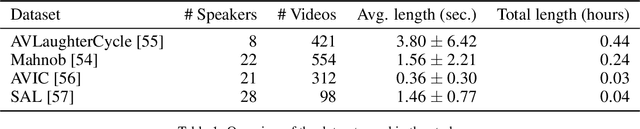
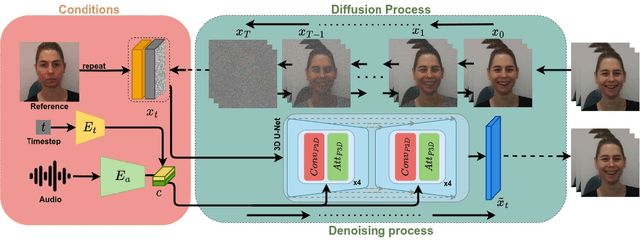
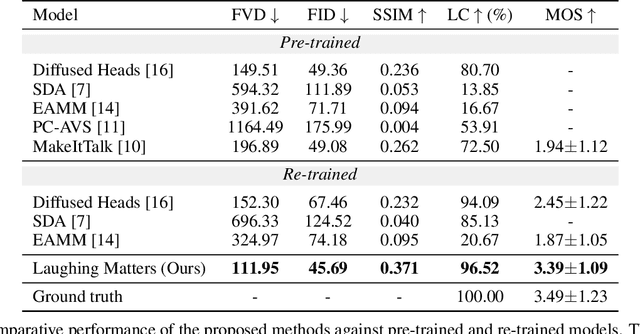
Speech-driven animation has gained significant traction in recent years, with current methods achieving near-photorealistic results. However, the field remains underexplored regarding non-verbal communication despite evidence demonstrating its importance in human interaction. In particular, generating laughter sequences presents a unique challenge due to the intricacy and nuances of this behaviour. This paper aims to bridge this gap by proposing a novel model capable of generating realistic laughter sequences, given a still portrait and an audio clip containing laughter. We highlight the failure cases of traditional facial animation methods and leverage recent advances in diffusion models to produce convincing laughter videos. We train our model on a diverse set of laughter datasets and introduce an evaluation metric specifically designed for laughter. When compared with previous speech-driven approaches, our model achieves state-of-the-art performance across all metrics, even when these are re-trained for laughter generation.