 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-headed eye-segmentation approach for biometric identification
Paper and Code
Sep 30, 2022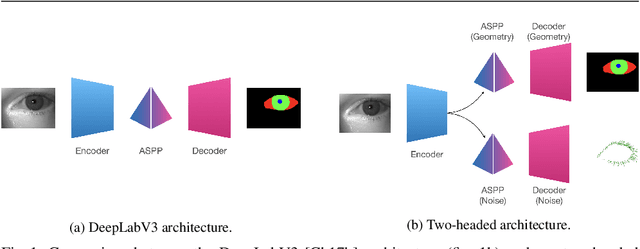
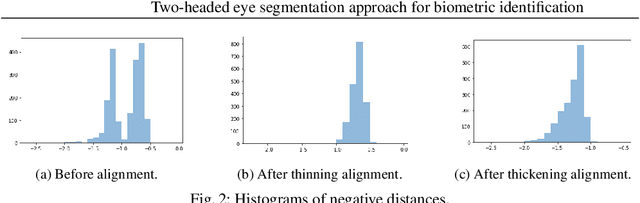
Iris-based identification systems are among the most popular approaches for person identification. Such systems require good-quality segmentation modules that ideally identify the regions for different eye components. This paper introduces the new two-headed architecture, where the eye components and eyelashes are segmented using two separate decoding modules. Moreover, we investigate various training scenarios by adopting different training losses. Thanks to the two-headed approach, we were also able to examine the quality of the model with the convex prior, which enforces the convexity of the segmented shapes. We conducted an extensive evaluation of various learning scenarios on real-life conditions high-resolution near-infrared iris images.