 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Deep-Fake Videos from Appearance and Behavior
Apr 29, 2020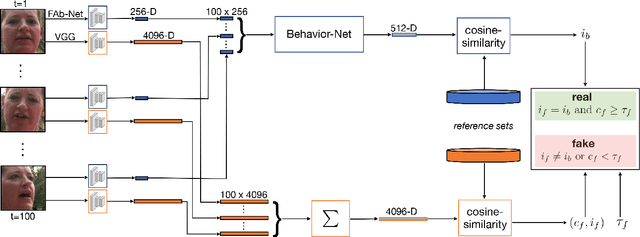



Synthetically-generated audios and videos -- so-called deep fakes -- continue to capture the imagination of the computer-graphics and computer-vision communities. At the same time, the democratization of access to technology that can create sophisticated manipulated video of anybody saying anything continues to be of concern because of its power to disrupt democratic elections, commit small to large-scale fraud, fuel dis-information campaigns, and create non-consensual pornography. We describe a biometric-based forensic technique for detecting face-swap deep fakes. This technique combines a static biometric based on facial recognition with a temporal, behavioral biometric based on facial expressions and head movements, where the behavioral embedding is learned using a CNN with a metric-learning objective function. We show the efficacy of this approach across several large-scale video datasets, as well as in-the-wild deep fakes.
3D Object Recognition with Ensemble Learning --- A Study of Point Cloud-Based Deep Learning Models
May 22, 2019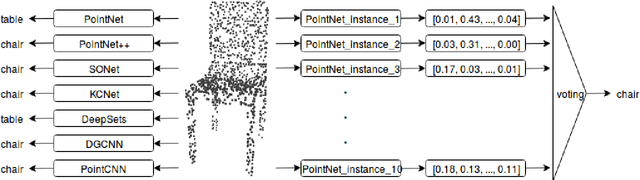

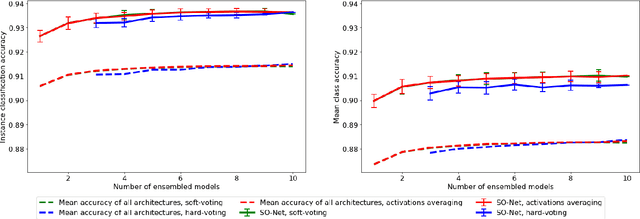
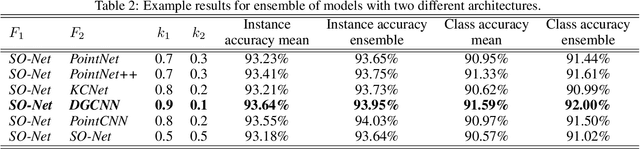
In this study, we present an analysis of model-based ensemble learning for 3D point-cloud object classification and detection. An ensemble of multiple model instances is known to outperform a single model instance, but there is little study of the topic of ensemble learning for 3D point clouds. First, an ensemble of multiple model instances trained on the same part of the $\textit{ModelNet40}$ dataset was tested for seven deep learning, point cloud-based classification algorithms: $\textit{PointNet}$, $\textit{PointNet++}$, $\textit{SO-Net}$, $\textit{KCNet}$, $\textit{DeepSets}$, $\textit{DGCNN}$, and $\textit{PointCNN}$. Second, the ensemble of different architectures was tested. Results of our experiments show that the tested ensemble learning methods improve over state-of-the-art on the $\textit{ModelNet40}$ dataset, from $92.65\%$ to $93.64\%$ for the ensemble of single architecture instances, $94.03\%$ for two different architectures, and $94.15\%$ for five different architectures. We show that the ensemble of two models with different architectures can be as effective as the ensemble of 10 models with the same architecture. Third, a study on classic bagging i.e. with different subsets used for training multiple model instances) was tested and sources of ensemble accuracy growth were investigated for best-performing architecture, i.e. $\textit{SO-Net}$. We also investigate the ensemble learning of $\textit{Frustum PointNet}$ approach in the task of 3D object detection, increasing the average precision of 3D box detection on the $\textit{KITTI}$ dataset from $63.1\%$ to $66.5\%$ using only three model instances. We measure the inference time of all 3D classification architectures on a $\textit{Nvidia Jetson TX2}$, a common embedded computer for mobile robots, to allude to the use of these models in real-life applications.
BinGAN: Learning Compact Binary Descriptors with a Regularized GAN
Nov 06, 2018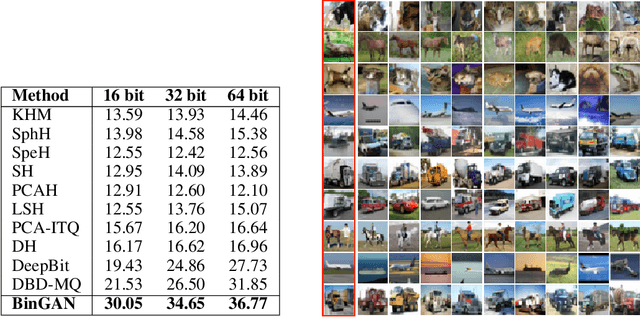
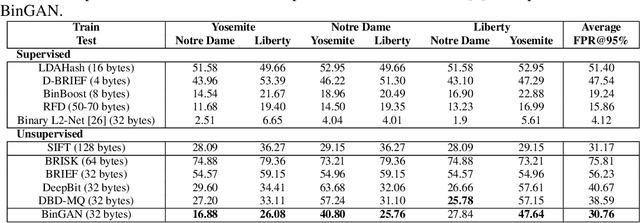


In this paper, we propose a novel regularization method for Generative Adversarial Networks, which allows the model to learn discriminative yet compact binary representations of image patches (image descriptors). We employ the dimensionality reduction that takes place in the intermediate layers of the discriminator network and train binarized low-dimensional representation of the penultimate layer to mimic the distribution of the higher-dimensional preceding layers. To achieve this, we introduce two loss terms that aim at: (i) reducing the correlation between the dimensions of the binarized low-dimensional representation of the penultimate layer i. e. maximizing joint entropy) and (ii) propagating the relations between the dimensions in the high-dimensional space to the low-dimensional space. We evaluate the resulting binary image descriptors on two challenging applications, image matching and retrieval, and achieve state-of-the-art results.
Digging Deep into the layers of CNNs: In Search of How CNNs Achieve View Invariance
Jun 20, 2016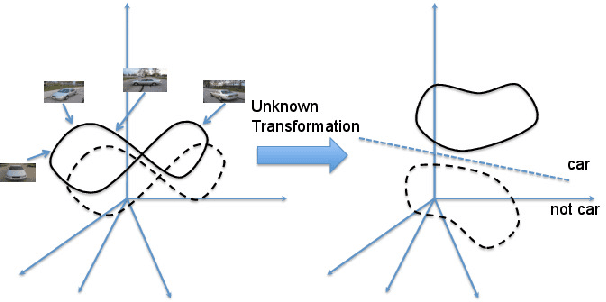
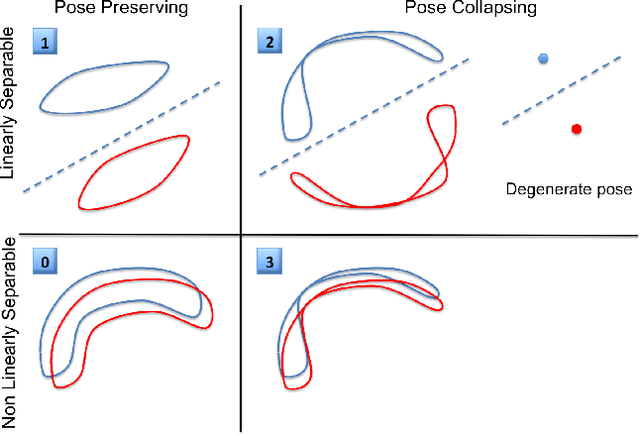

This paper is focused on studying the view-manifold structure in the feature spaces implied by the different layers of Convolutional Neural Networks (CNN). There are several questions that this paper aims to answer: Does the learned CNN representation achieve viewpoint invariance? How does it achieve viewpoint invariance? Is it achieved by collapsing the view manifolds, or separating them while preserving them? At which layer is view invariance achieved? How can the structure of the view manifold at each layer of a deep convolutional neural network be quantified experimentally? How does fine-tuning of a pre-trained CNN on a multi-view dataset affect the representation at each layer of the network? In order to answer these questions we propose a methodology to quantify the deformation and degeneracy of view manifolds in CNN layers. We apply this methodology and report interesting results in this paper that answer the aforementioned questions.
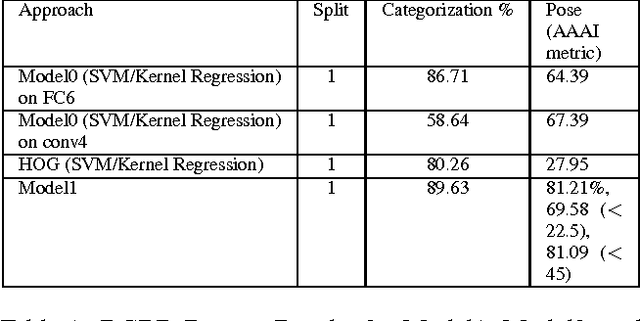
Convolutional Models for Joint Object Categorization and Pose Estimation
Apr 19, 2016
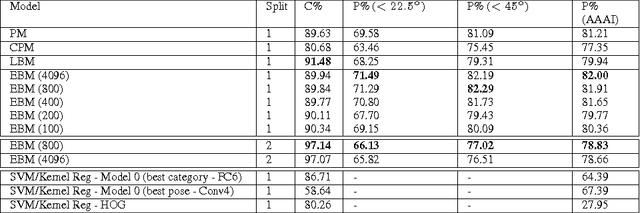
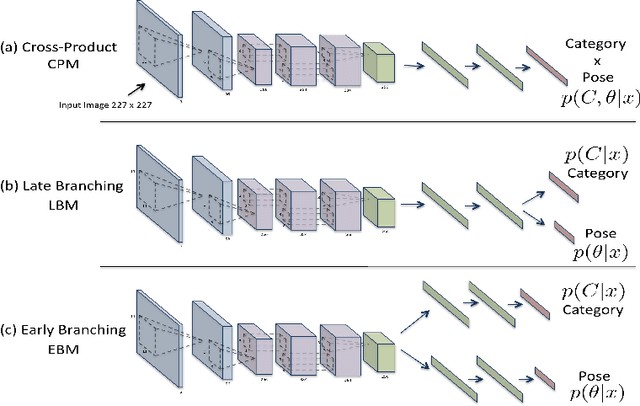

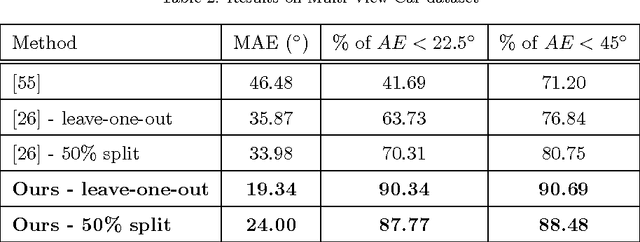
In the task of Object Recognition, there exists a dichotomy between the categorization of objects and estimating object pose, where the former necessitates a view-invariant representation, while the latter requires a representation capable of capturing pose information over different categories of objects. With the rise of deep architectures, the prime focus has been on object category recognition. Deep learning methods have achieved wide success in this task. In contrast, object pose regression using these approaches has received relatively much less attention. In this paper we show how deep architectures, specifically Convolutional Neural Networks (CNN), can be adapted to the task of simultaneous categorization and pose estimation of objects. We investigate and analyze the layers of various CNN models and extensively compare between them with the goal of discovering how the layers of distributed representations of CNNs represent object pose information and how this contradicts with object category representations. We extensively experiment on two recent large and challenging multi-view datasets. Our models achieve better than state-of-the-art performance on both datasets.
Factorization of View-Object Manifolds for Joint Object Recognition and Pose Estimation
Apr 13, 2015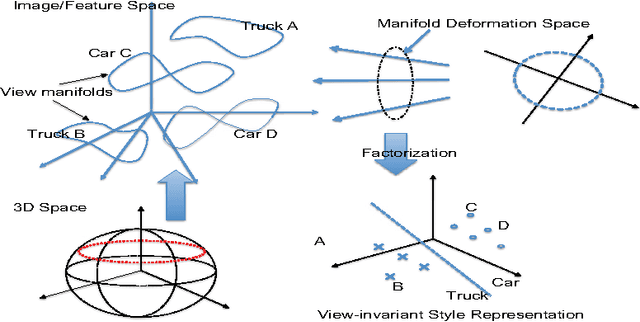
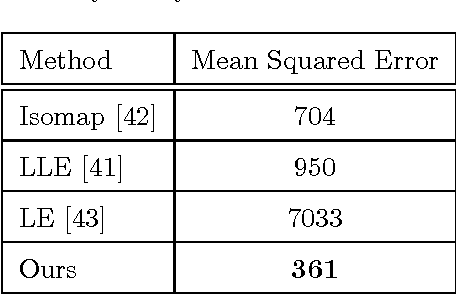

Due to large variations in shape, appearance, and viewing conditions, object recognition is a key precursory challenge in the fields of object manipulation and robotic/AI visual reasoning in general. Recognizing object categories, particular instances of objects and viewpoints/poses of objects are three critical subproblems robots must solve in order to accurately grasp/manipulate objects and reason about their environments. Multi-view images of the same object lie on intrinsic low-dimensional manifolds in descriptor spaces (e.g. visual/depth descriptor spaces). These object manifolds share the same topology despite being geometrically different. Each object manifold can be represented as a deformed version of a unified manifold. The object manifolds can thus be parameterized by its homeomorphic mapping/reconstruction from the unified manifold. In this work, we develop a novel framework to jointly solve the three challenging recognition sub-problems, by explicitly modeling the deformations of object manifolds and factorizing it in a view-invariant space for recognition. We perform extensive experiments on several challenging datasets and achieve state-of-the-art results.
Measuring Atmospheric Scattering from Digital Images of Urban Scenery using Temporal Polarization-Based Vision
Jul 14, 2014
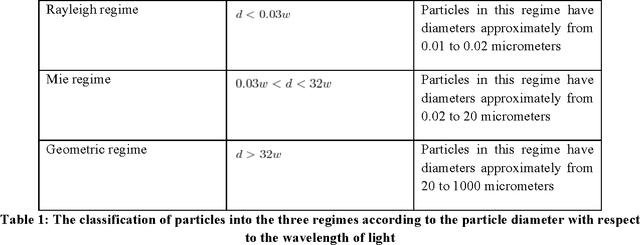
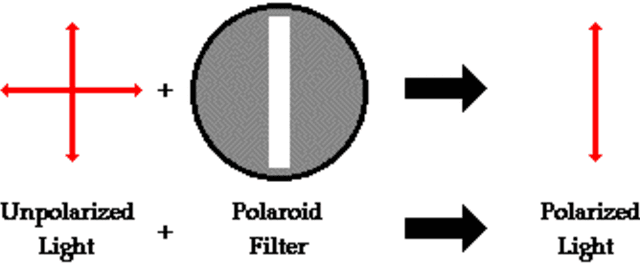
Particulate Matter (PM) is a form of air pollution that visually degrades urban scenery and is hazardous to human health and the environment. Current monitoring devices are limited in measuring average PM over large areas. Quantifying the visual effects of haze in digital images of urban scenery and correlating these effects to PM levels is a vital step in more practically monitoring our environment. Current image haze extraction algorithms remove haze from the scene for the sole purpose of enhancing vision. We present two algorithms which bridge the gap between image haze extraction and environmental monitoring. We provide a means of measuring atmospheric scattering from images of urban scenery by incorporating temporal knowledge. In doing so, we also present a method of recovering an accurate depthmap of the scene and recovering the scene without the visual effects of haze. We compare our algorithm to three known haze removal methods. The algorithms are composed of an optimization over a model of haze formation in images and an optimization using a constraint of constant depth over a sequence of images taken over time. These algorithms not only measure atmospheric scattering, but also recover a more accurate depthmap and dehazed image. The measurements of atmospheric scattering this research produces, can be directly correlated to PM levels and therefore pave the way to monitoring the health of the environment by visual means. Accurate atmospheric sensing from digital images is a challenging and under-researched problem. This work provides an important step towards a more practical and accurate visual means of measuring PM from digital images.