 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Models for Joint Object Categorization and Pose Estimation
Paper and Code
Apr 19, 2016
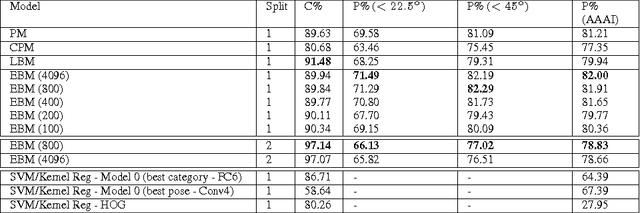
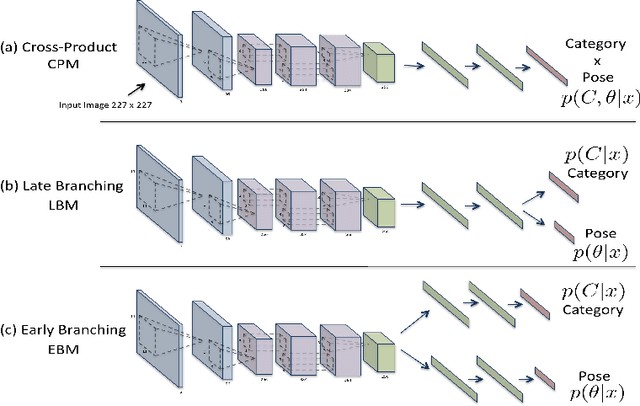

In the task of Object Recognition, there exists a dichotomy between the categorization of objects and estimating object pose, where the former necessitates a view-invariant representation, while the latter requires a representation capable of capturing pose information over different categories of objects. With the rise of deep architectures, the prime focus has been on object category recognition. Deep learning methods have achieved wide success in this task. In contrast, object pose regression using these approaches has received relatively much less attention. In this paper we show how deep architectures, specifically Convolutional Neural Networks (CNN), can be adapted to the task of simultaneous categorization and pose estimation of objects. We investigate and analyze the layers of various CNN models and extensively compare between them with the goal of discovering how the layers of distributed representations of CNNs represent object pose information and how this contradicts with object category representations. We extensively experiment on two recent large and challenging multi-view datasets. Our models achieve better than state-of-the-art performance on both datasets.