 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigging Deep into the layers of CNNs: In Search of How CNNs Achieve View Invariance
Jun 20, 2016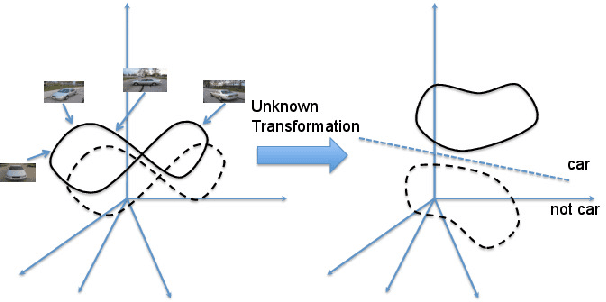
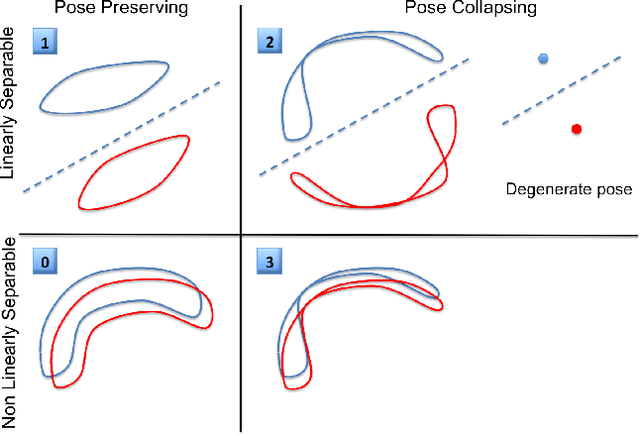

This paper is focused on studying the view-manifold structure in the feature spaces implied by the different layers of Convolutional Neural Networks (CNN). There are several questions that this paper aims to answer: Does the learned CNN representation achieve viewpoint invariance? How does it achieve viewpoint invariance? Is it achieved by collapsing the view manifolds, or separating them while preserving them? At which layer is view invariance achieved? How can the structure of the view manifold at each layer of a deep convolutional neural network be quantified experimentally? How does fine-tuning of a pre-trained CNN on a multi-view dataset affect the representation at each layer of the network? In order to answer these questions we propose a methodology to quantify the deformation and degeneracy of view manifolds in CNN layers. We apply this methodology and report interesting results in this paper that answer the aforementioned questions.
Convolutional Models for Joint Object Categorization and Pose Estimation
Apr 19, 2016
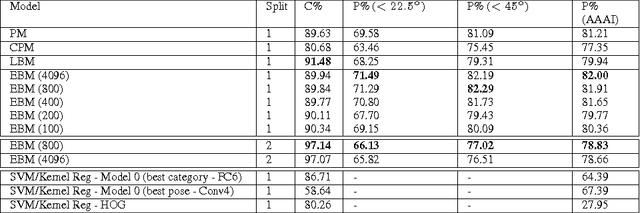
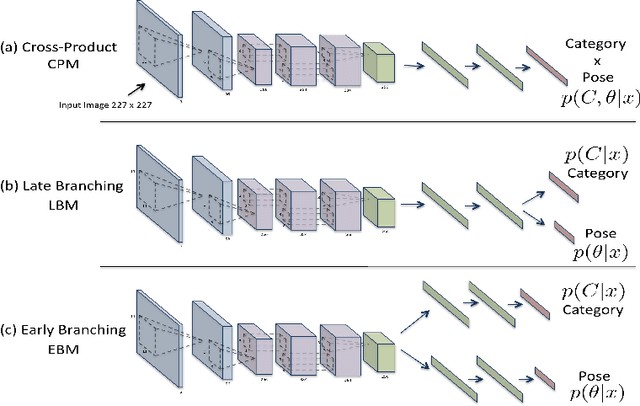

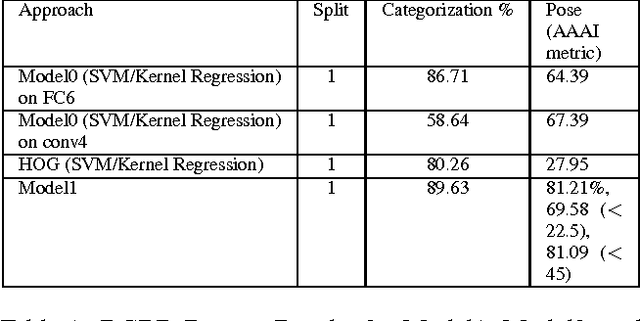
In the task of Object Recognition, there exists a dichotomy between the categorization of objects and estimating object pose, where the former necessitates a view-invariant representation, while the latter requires a representation capable of capturing pose information over different categories of objects. With the rise of deep architectures, the prime focus has been on object category recognition. Deep learning methods have achieved wide success in this task. In contrast, object pose regression using these approaches has received relatively much less attention. In this paper we show how deep architectures, specifically Convolutional Neural Networks (CNN), can be adapted to the task of simultaneous categorization and pose estimation of objects. We investigate and analyze the layers of various CNN models and extensively compare between them with the goal of discovering how the layers of distributed representations of CNNs represent object pose information and how this contradicts with object category representations. We extensively experiment on two recent large and challenging multi-view datasets. Our models achieve better than state-of-the-art performance on both datasets.
Manifold-Kernels Comparison in MKPLS for Visual Speech Recognition
Jan 22, 2016
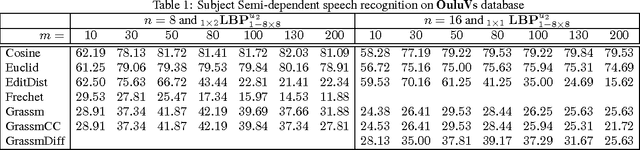
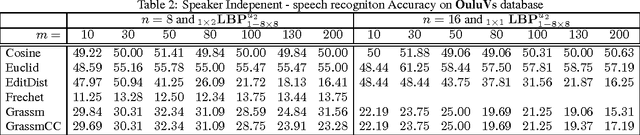

Speech recognition is a challenging problem. Due to the acoustic limitations, using visual information is essential for improving the recognition accuracy in real-life unconstraint situations. One common approach is to model the visual recognition as nonlinear optimization problem. Measuring the distances between visual units is essential for solving this problem. Embedding the visual units on a manifold and using manifold kernels is one way to measure these distances. This work is intended to evaluate the performance of several manifold kernels for solving the problem of visual speech recognition. We show the theory behind each kernel. We apply manifold kernel partial least squares framework to OuluVs and AvLetters databases, and show empirical comparison between all kernels. This framework provides convenient way to explore different kernels.