 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorization of View-Object Manifolds for Joint Object Recognition and Pose Estimation
Paper and Code
Apr 13, 2015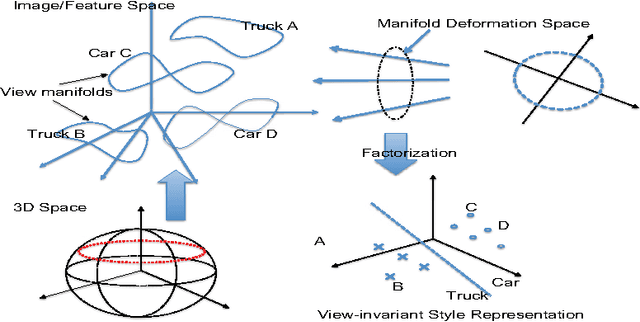

Due to large variations in shape, appearance, and viewing conditions, object recognition is a key precursory challenge in the fields of object manipulation and robotic/AI visual reasoning in general. Recognizing object categories, particular instances of objects and viewpoints/poses of objects are three critical subproblems robots must solve in order to accurately grasp/manipulate objects and reason about their environments. Multi-view images of the same object lie on intrinsic low-dimensional manifolds in descriptor spaces (e.g. visual/depth descriptor spaces). These object manifolds share the same topology despite being geometrically different. Each object manifold can be represented as a deformed version of a unified manifold. The object manifolds can thus be parameterized by its homeomorphic mapping/reconstruction from the unified manifold. In this work, we develop a novel framework to jointly solve the three challenging recognition sub-problems, by explicitly modeling the deformations of object manifolds and factorizing it in a view-invariant space for recognition. We perform extensive experiments on several challenging datasets and achieve state-of-the-art results.