 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion
May 11, 2023
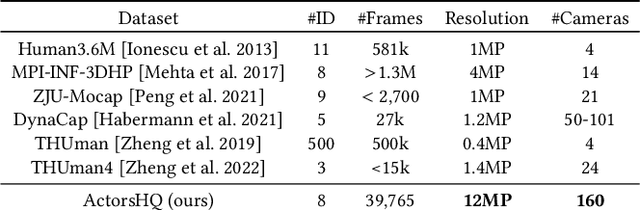

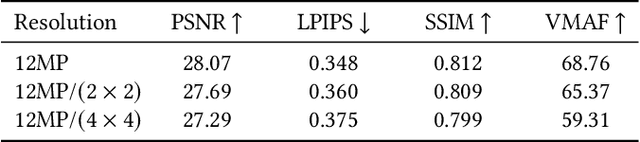
Representing human performance at high-fidelity is an essential building block in diverse applications, such as film production, computer games or videoconferencing. To close the gap to production-level quality, we introduce HumanRF, a 4D dynamic neural scene representation that captures full-body appearance in motion from multi-view video input, and enables playback from novel, unseen viewpoints. Our novel representation acts as a dynamic video encoding that captures fine details at high compression rates by factorizing space-time into a temporal matrix-vector decomposition. This allows us to obtain temporally coherent reconstructions of human actors for long sequences, while representing high-resolution details even in the context of challenging motion. While most research focuses on synthesizing at resolutions of 4MP or lower, we address the challenge of operating at 12MP. To this end, we introduce ActorsHQ, a novel multi-view dataset that provides 12MP footage from 160 cameras for 16 sequences with high-fidelity, per-frame mesh reconstructions. We demonstrate challenges that emerge from using such high-resolution data and show that our newly introduced HumanRF effectively leverages this data, making a significant step towards production-level quality novel view synthesis.
Self-improving Multiplane-to-layer Images for Novel View Synthesis
Oct 04, 2022
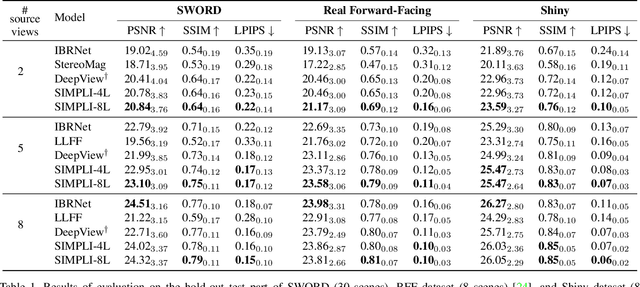
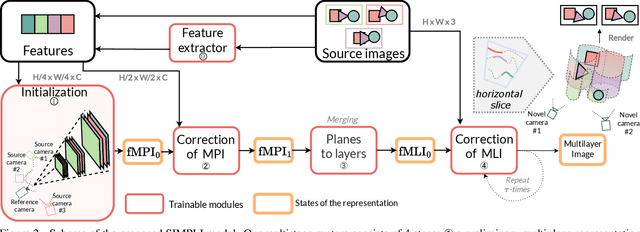
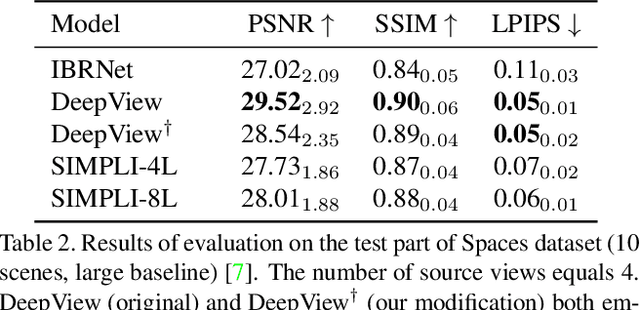
We present a new method for lightweight novel-view synthesis that generalizes to an arbitrary forward-facing scene. Recent approaches are computationally expensive, require per-scene optimization, or produce a memory-expensive representation. We start by representing the scene with a set of fronto-parallel semitransparent planes and afterward convert them to deformable layers in an end-to-end manner. Additionally, we employ a feed-forward refinement procedure that corrects the estimated representation by aggregating information from input views. Our method does not require fine-tuning when a new scene is processed and can handle an arbitrary number of views without restrictions. Experimental results show that our approach surpasses recent models in terms of common metrics and human evaluation, with the noticeable advantage in inference speed and compactness of the inferred layered geometry, see https://samsunglabs.github.io/MLI
MegaPortraits: One-shot Megapixel Neural Head Avatars
Jul 15, 2022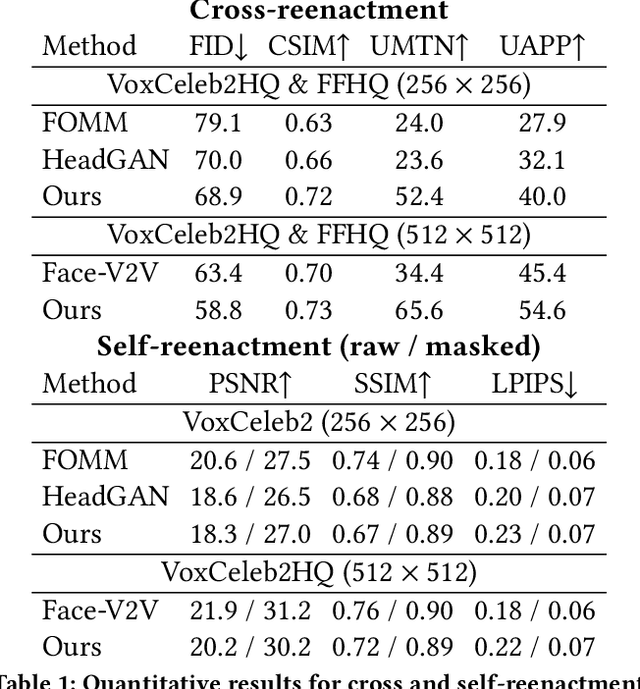
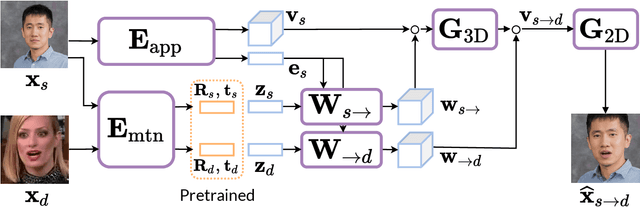
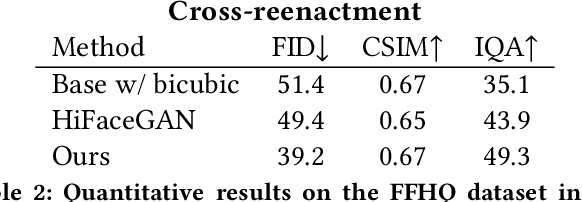

In this work, we advance the neural head avatar technology to the megapixel resolution while focusing on the particularly challenging task of cross-driving synthesis, i.e., when the appearance of the driving image is substantially different from the animated source image. We propose a set of new neural architectures and training methods that can leverage both medium-resolution video data and high-resolution image data to achieve the desired levels of rendered image quality and generalization to novel views and motion. We demonstrate that suggested architectures and methods produce convincing high-resolution neural avatars, outperforming the competitors in the cross-driving scenario. Lastly, we show how a trained high-resolution neural avatar model can be distilled into a lightweight student model which runs in real-time and locks the identities of neural avatars to several dozens of pre-defined source images. Real-time operation and identity lock are essential for many practical applications head avatar systems.
Realistic One-shot Mesh-based Head Avatars
Jun 16, 2022
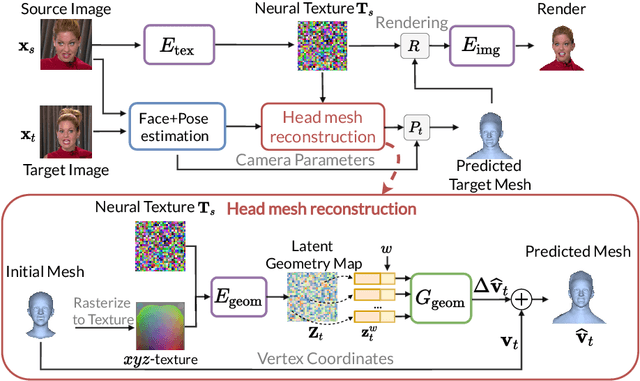
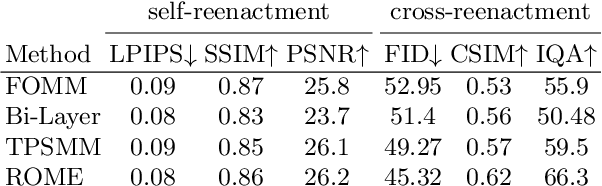
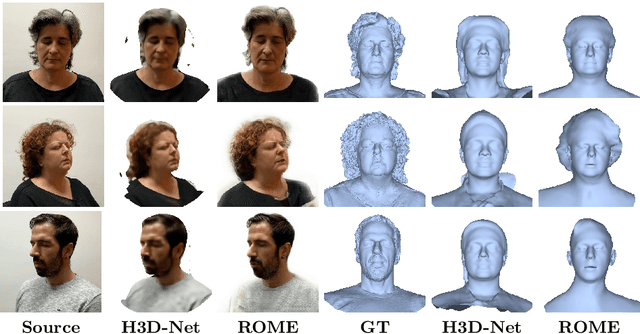
We present a system for realistic one-shot mesh-based human head avatars creation, ROME for short. Using a single photograph, our model estimates a person-specific head mesh and the associated neural texture, which encodes both local photometric and geometric details. The resulting avatars are rigged and can be rendered using a neural network, which is trained alongside the mesh and texture estimators on a dataset of in-the-wild videos. In the experiments, we observe that our system performs competitively both in terms of head geometry recovery and the quality of renders, especially for the cross-person reenactment. See results https://samsunglabs.github.io/rome/
Stereo Magnification with Multi-Layer Images
Jan 13, 2022
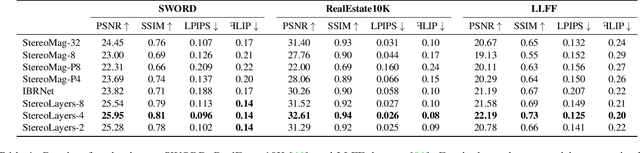

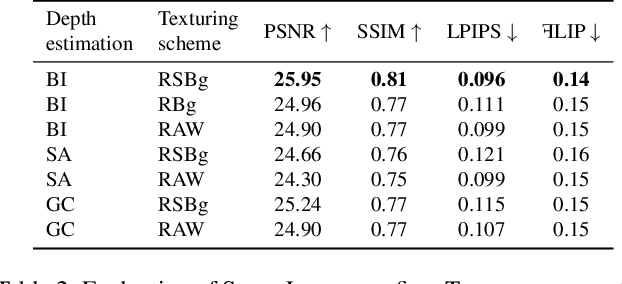
Representing scenes with multiple semi-transparent colored layers has been a popular and successful choice for real-time novel view synthesis. Existing approaches infer colors and transparency values over regularly-spaced layers of planar or spherical shape. In this work, we introduce a new view synthesis approach based on multiple semi-transparent layers with scene-adapted geometry. Our approach infers such representations from stereo pairs in two stages. The first stage infers the geometry of a small number of data-adaptive layers from a given pair of views. The second stage infers the color and the transparency values for these layers producing the final representation for novel view synthesis. Importantly, both stages are connected through a differentiable renderer and are trained in an end-to-end manner. In the experiments, we demonstrate the advantage of the proposed approach over the use of regularly-spaced layers with no adaptation to scene geometry. Despite being orders of magnitude faster during rendering, our approach also outperforms a recently proposed IBRNet system based on implicit geometry representation. See results at https://samsunglabs.github.io/StereoLayers .
Image Generators with Conditionally-Independent Pixel Synthesis
Nov 27, 2020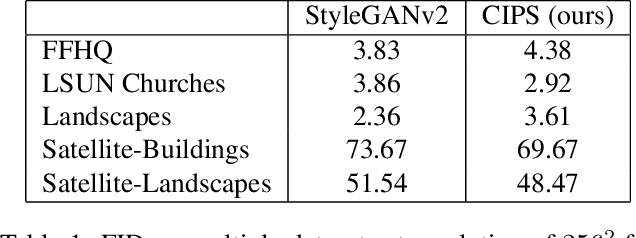
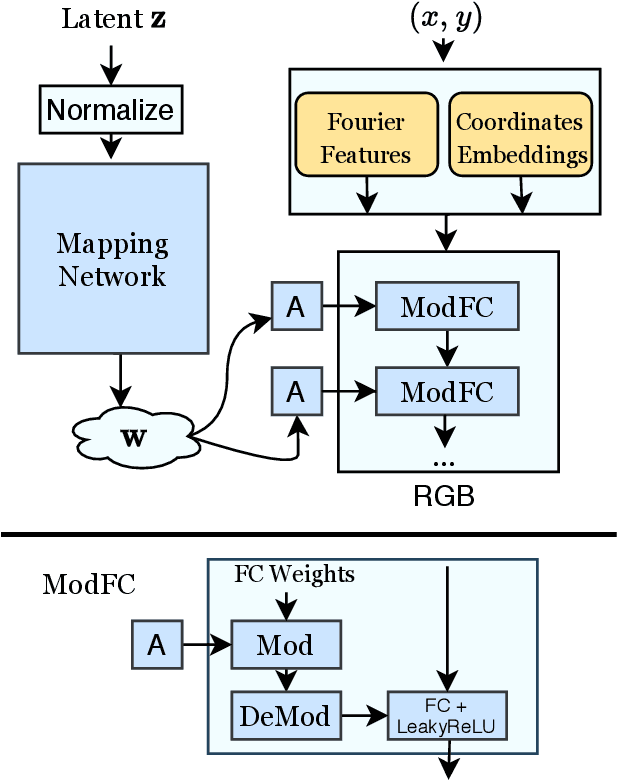
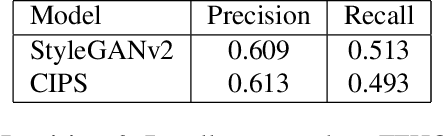
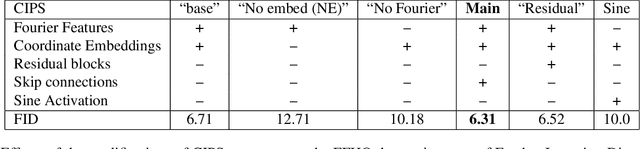
Existing image generator networks rely heavily on spatial convolutions and, optionally, self-attention blocks in order to gradually synthesize images in a coarse-to-fine manner. Here, we present a new architecture for image generators, where the color value at each pixel is computed independently given the value of a random latent vector and the coordinate of that pixel. No spatial convolutions or similar operations that propagate information across pixels are involved during the synthesis. We analyze the modeling capabilities of such generators when trained in an adversarial fashion, and observe the new generators to achieve similar generation quality to state-of-the-art convolutional generators. We also investigate several interesting properties unique to the new architecture.
High-Resolution Daytime Translation Without Domain Labels
Mar 23, 2020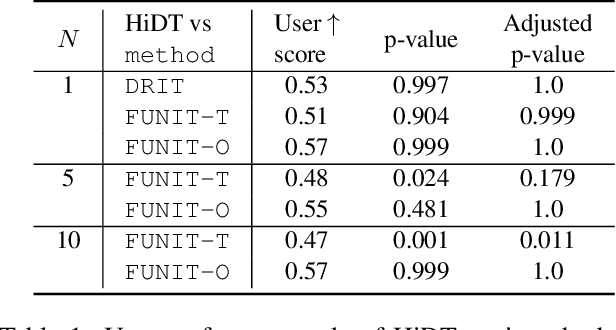
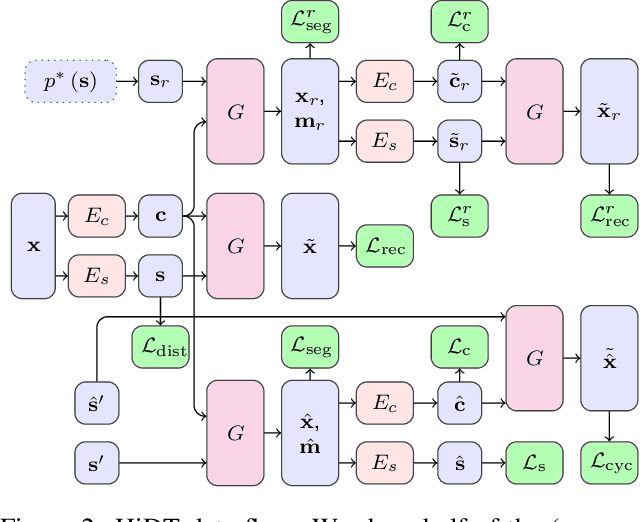
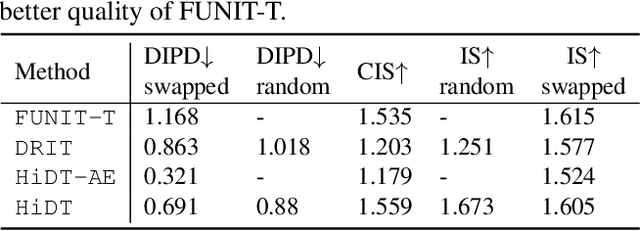
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.
Graph Convolutional Policy for Solving Tree Decomposition via Reinforcement Learning Heuristics
Oct 18, 2019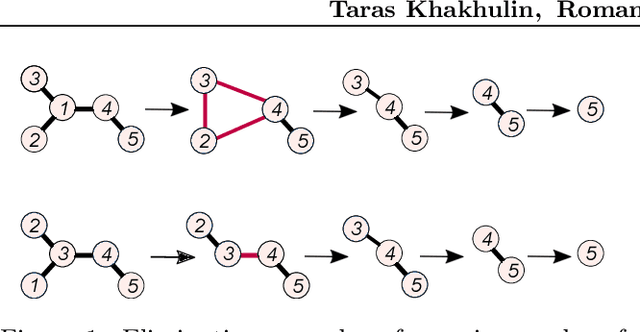
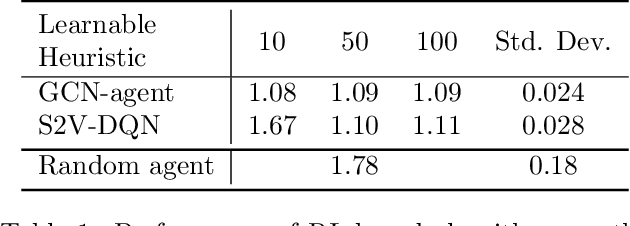
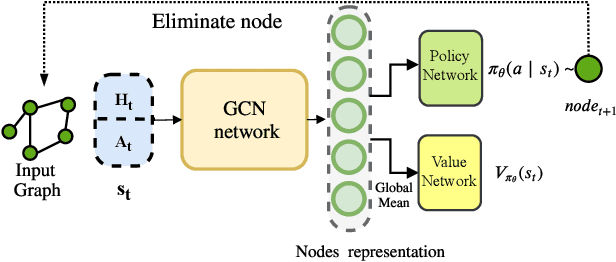
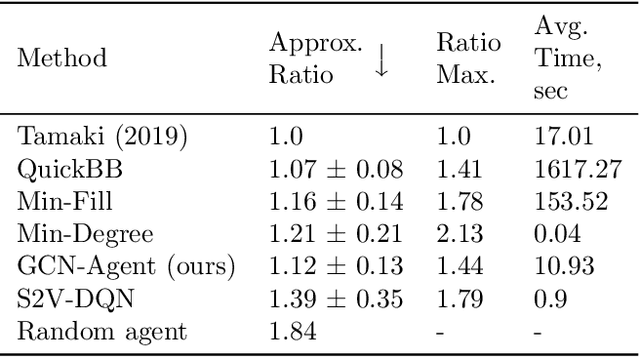
We propose a Reinforcement Learning based approach to approximately solve the Tree Decomposition (TD)problem. TD is a combinatorial problem, which is central to the analysis of graph minor structure and computational complexity, as well as in the algorithms of probabilistic inference, register allocation, and other practical tasks. Recently, it has been shown that combinatorial problems can be successively solved by learned heuristics. However, the majority of existing works do not address the question of the generalization of learning-based solutions. Our model is based on the graph convolution neural network (GCN) for learning graph representations. We show that the agent builton GCN and trained on a single graph using an Actor-Critic method can efficiently generalize to real-world TD problem instances. We establish that our method successfully generalizes from small graphs, where TD can be found by exact algorithms, to large instances of practical interest, while still having very low time-to-solution. On the other hand, the agent-based approach surpasses all greedy heuristics by the quality of the solution.