 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-improving Multiplane-to-layer Images for Novel View Synthesis
Oct 04, 2022
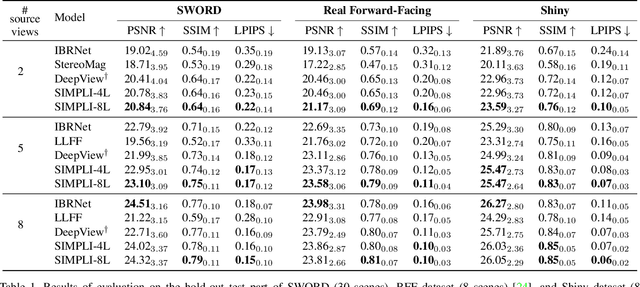
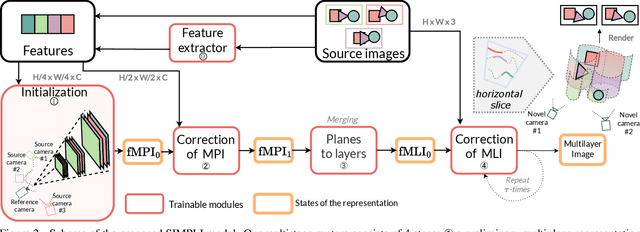
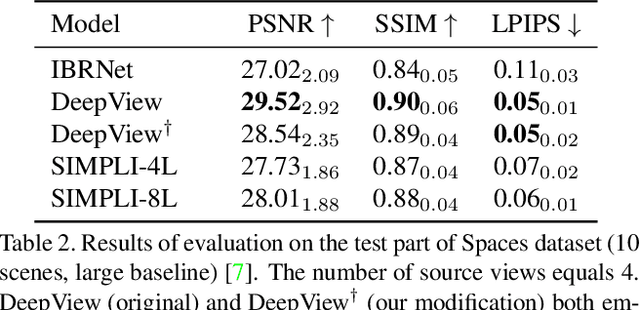
We present a new method for lightweight novel-view synthesis that generalizes to an arbitrary forward-facing scene. Recent approaches are computationally expensive, require per-scene optimization, or produce a memory-expensive representation. We start by representing the scene with a set of fronto-parallel semitransparent planes and afterward convert them to deformable layers in an end-to-end manner. Additionally, we employ a feed-forward refinement procedure that corrects the estimated representation by aggregating information from input views. Our method does not require fine-tuning when a new scene is processed and can handle an arbitrary number of views without restrictions. Experimental results show that our approach surpasses recent models in terms of common metrics and human evaluation, with the noticeable advantage in inference speed and compactness of the inferred layered geometry, see https://samsunglabs.github.io/MLI
Stereo Magnification with Multi-Layer Images
Jan 13, 2022
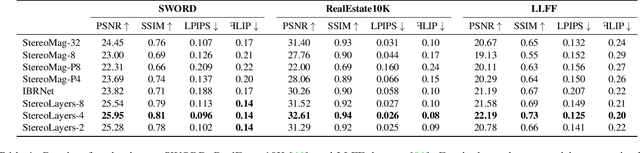

Representing scenes with multiple semi-transparent colored layers has been a popular and successful choice for real-time novel view synthesis. Existing approaches infer colors and transparency values over regularly-spaced layers of planar or spherical shape. In this work, we introduce a new view synthesis approach based on multiple semi-transparent layers with scene-adapted geometry. Our approach infers such representations from stereo pairs in two stages. The first stage infers the geometry of a small number of data-adaptive layers from a given pair of views. The second stage infers the color and the transparency values for these layers producing the final representation for novel view synthesis. Importantly, both stages are connected through a differentiable renderer and are trained in an end-to-end manner. In the experiments, we demonstrate the advantage of the proposed approach over the use of regularly-spaced layers with no adaptation to scene geometry. Despite being orders of magnitude faster during rendering, our approach also outperforms a recently proposed IBRNet system based on implicit geometry representation. See results at https://samsunglabs.github.io/StereoLayers .
High-Resolution Daytime Translation Without Domain Labels
Mar 23, 2020
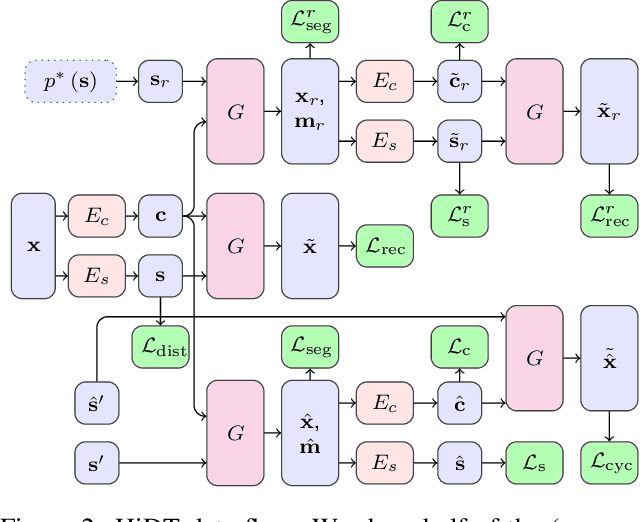
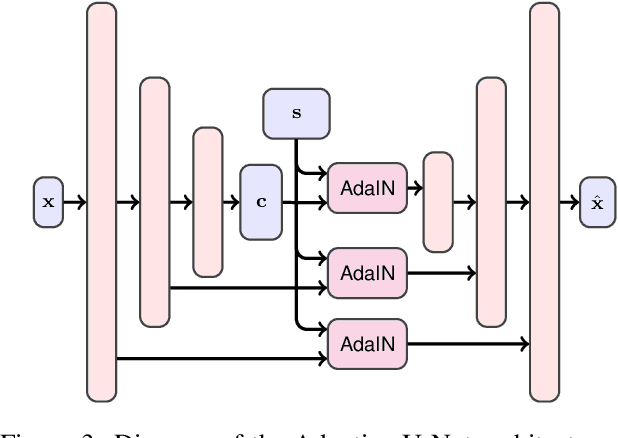
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.
Recognition of Russian traffic signs in winter conditions. Solutions of the "Ice Vision" competition winners
Sep 16, 2019

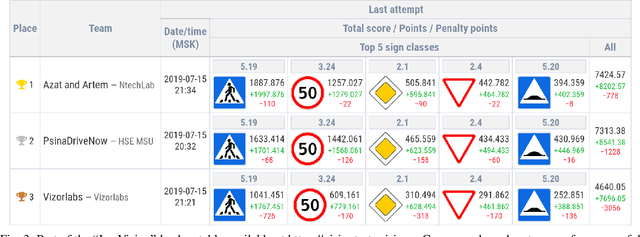
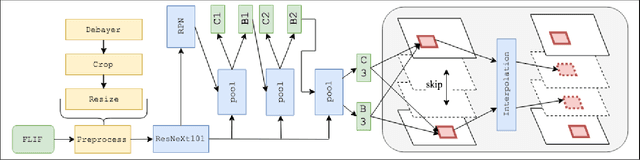
With the advancements of various autonomous car projects aiming to achieve SAE Level 5, real-time detection of traffic signs in real-life scenarios has become a highly relevant problem for the industry. Even though a great progress has been achieved in this field, there is still no clear consensus on what the state-of-the-art in this field is. Moreover, it is important to develop and test systems in various regions and conditions. This is why the "Ice Vision" competition has focused on the detection of Russian traffic signs in winter conditions. The IceVisionSet dataset used for this competition features real-world collection of lossless frame sequences with traffic sign annotations. The sequences were collected in varying conditions, including: different weather, camera exposure, illumination and moving speeds. In this work we describe the competition and present the solutions of the 3 top teams.
Learning State Representations in Complex Systems with Multimodal Data
Nov 30, 2018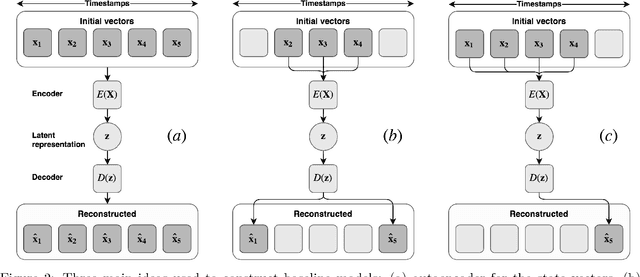

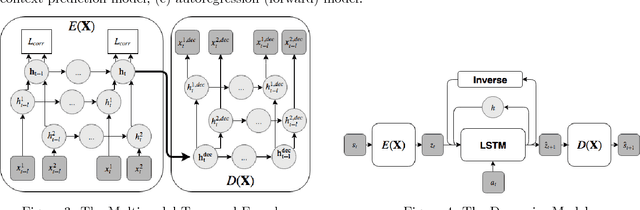
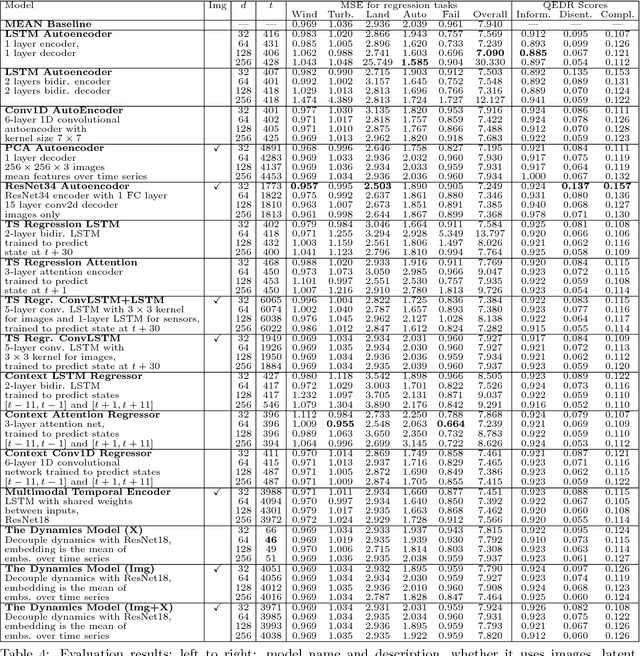
Representation learning becomes especially important for complex systems with multimodal data sources such as cameras or sensors. Recent advances in reinforcement learning and optimal control make it possible to design control algorithms on these latent representations, but the field still lacks a large-scale standard dataset for unified comparison. In this work, we present a large-scale dataset and evaluation framework for representation learning for the complex task of landing an airplane. We implement and compare several approaches to representation learning on this dataset in terms of the quality of simple supervised learning tasks and disentanglement scores. The resulting representations can be used for further tasks such as anomaly detection, optimal control, model-based reinforcement learning, and other applications.