 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022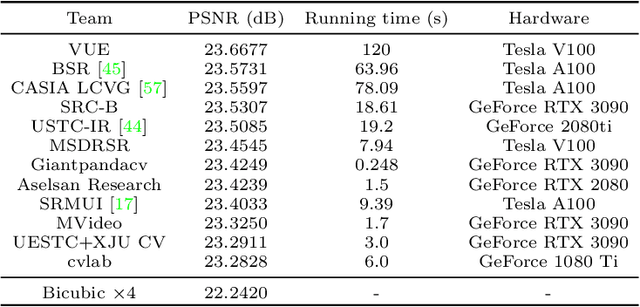
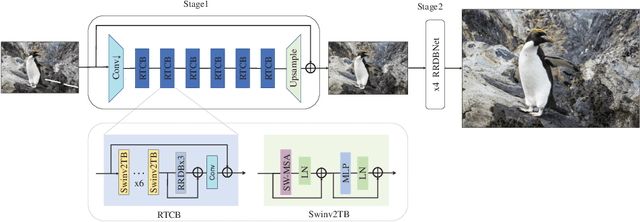

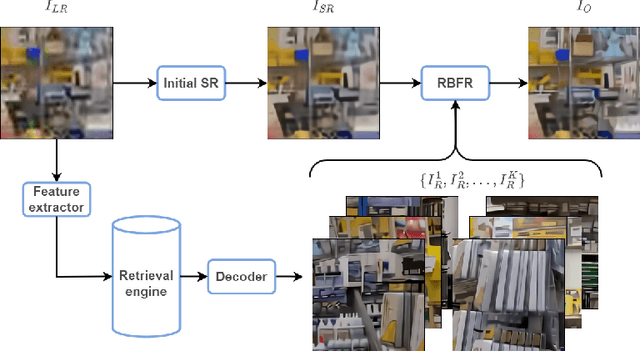
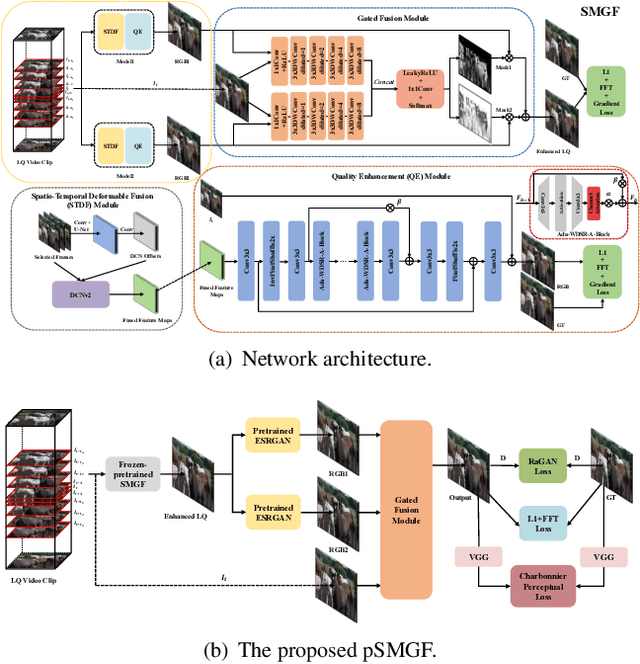
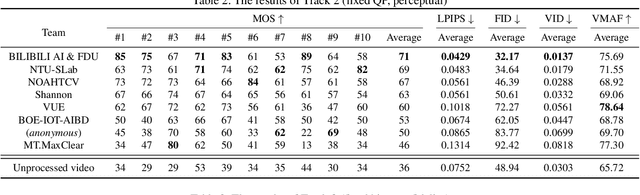
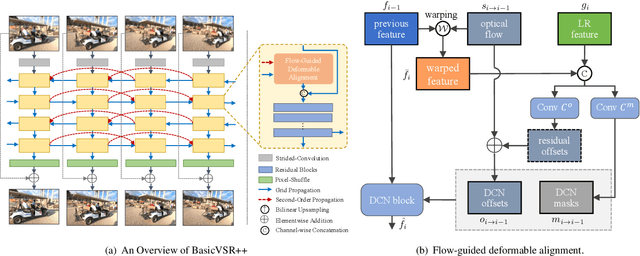
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022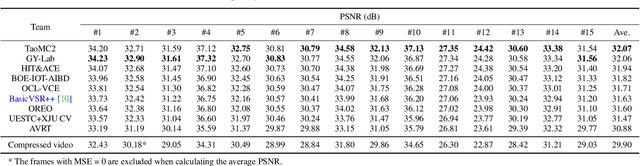
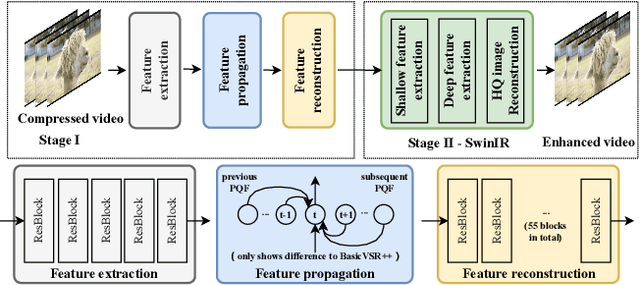
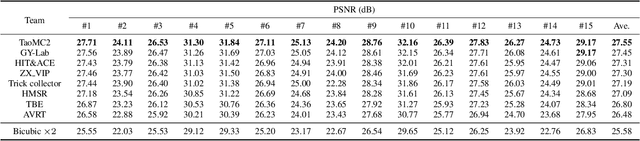

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021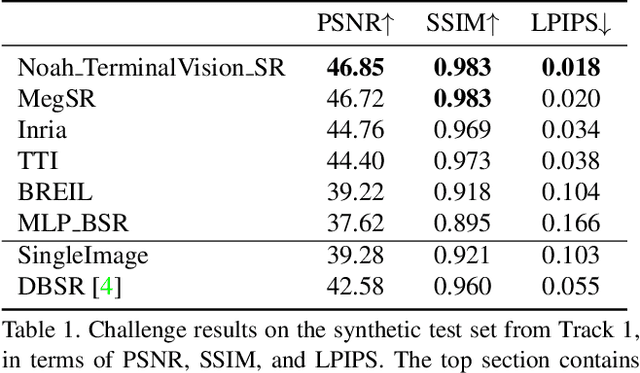

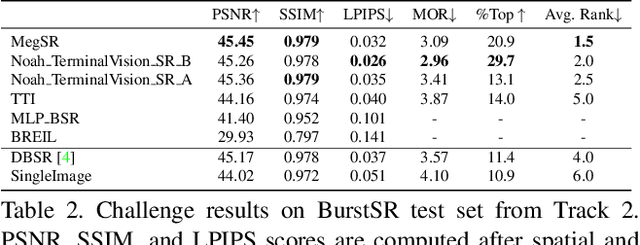

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021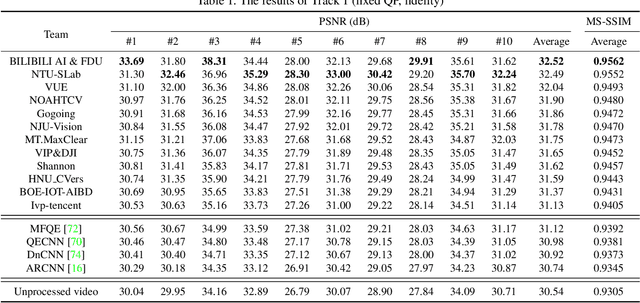
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Recognition of Russian traffic signs in winter conditions. Solutions of the "Ice Vision" competition winners
Sep 16, 2019

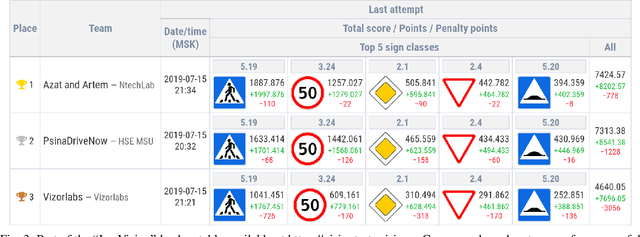
With the advancements of various autonomous car projects aiming to achieve SAE Level 5, real-time detection of traffic signs in real-life scenarios has become a highly relevant problem for the industry. Even though a great progress has been achieved in this field, there is still no clear consensus on what the state-of-the-art in this field is. Moreover, it is important to develop and test systems in various regions and conditions. This is why the "Ice Vision" competition has focused on the detection of Russian traffic signs in winter conditions. The IceVisionSet dataset used for this competition features real-world collection of lossless frame sequences with traffic sign annotations. The sequences were collected in varying conditions, including: different weather, camera exposure, illumination and moving speeds. In this work we describe the competition and present the solutions of the 3 top teams.
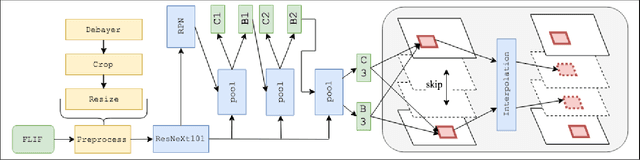
Adapting Convolutional Neural Networks for Geographical Domain Shift
Jan 18, 2019

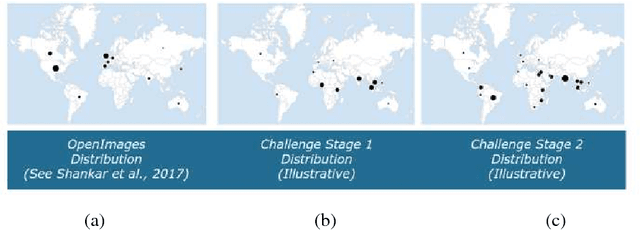
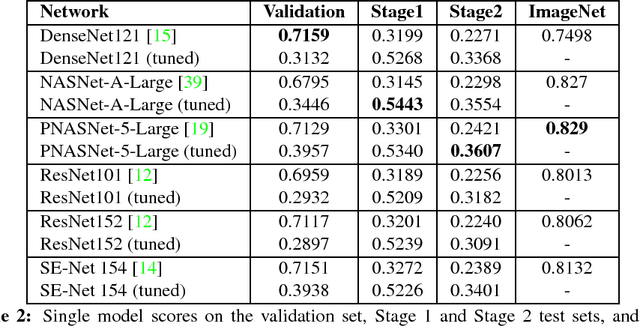
We present the winning solution for the Inclusive Images Competition organized as part of the Conference on Neural Information Processing Systems (NeurIPS 2018) Competition Track. The competition was organized to study ways to cope with domain shift in image processing, specifically geographical shift: the training and two test sets in the competition had different geographical distributions. Our solution has proven to be relatively straightforward and simple: it is an ensemble of several CNNs where only the last layer is fine-tuned with the help of a small labeled set of tuning labels made available by the organizers. We believe that while domain shift remains a formidable problem, our approach opens up new possibilities for alleviating this problem in practice, where small labeled datasets from the target domain are usually either available or can be obtained and labeled cheaply.
Learning State Representations in Complex Systems with Multimodal Data
Nov 30, 2018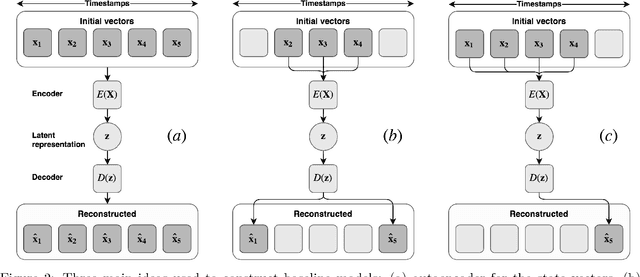

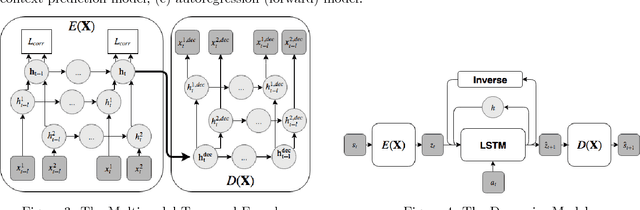
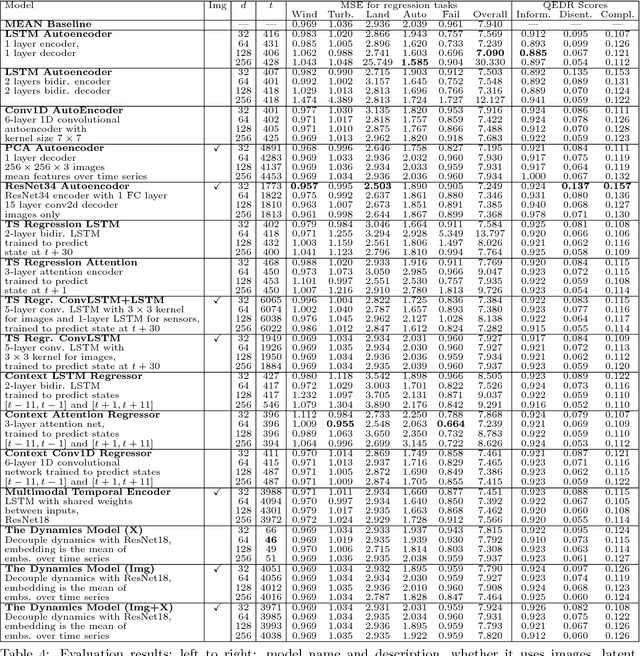
Representation learning becomes especially important for complex systems with multimodal data sources such as cameras or sensors. Recent advances in reinforcement learning and optimal control make it possible to design control algorithms on these latent representations, but the field still lacks a large-scale standard dataset for unified comparison. In this work, we present a large-scale dataset and evaluation framework for representation learning for the complex task of landing an airplane. We implement and compare several approaches to representation learning on this dataset in terms of the quality of simple supervised learning tasks and disentanglement scores. The resulting representations can be used for further tasks such as anomaly detection, optimal control, model-based reinforcement learning, and other applications.
SEIGAN: Towards Compositional Image Generation by Simultaneously Learning to Segment, Enhance, and Inpaint
Nov 19, 2018



We present a novel approach to image manipulation and understanding by simultaneously learning to segment object masks, paste objects to another background image, and remove them from original images. For this purpose, we develop a novel generative model for compositional image generation, SEIGAN (Segment-Enhance-Inpaint Generative Adversarial Network), which learns these three operations together in an adversarial architecture with additional cycle consistency losses. To train, SEIGAN needs only bounding box supervision and does not require pairing or ground truth masks. SEIGAN produces better generated images (evaluated by human assessors) than other approaches and produces high-quality segmentation masks, improving over other adversarially trained approaches and getting closer to the results of fully supervised training.
Label Denoising with Large Ensembles of Heterogeneous Neural Networks
Sep 12, 2018
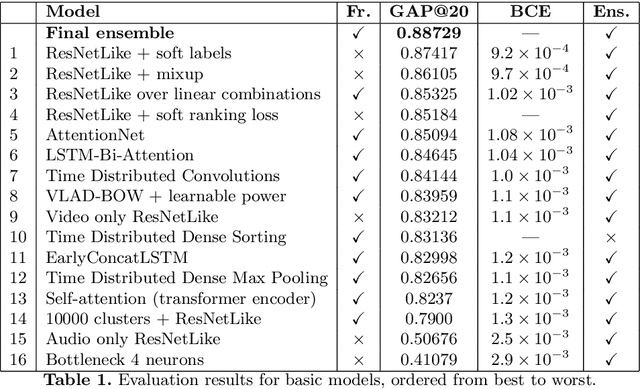
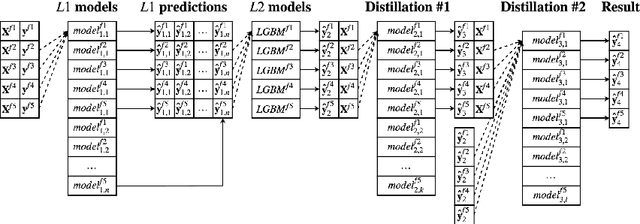
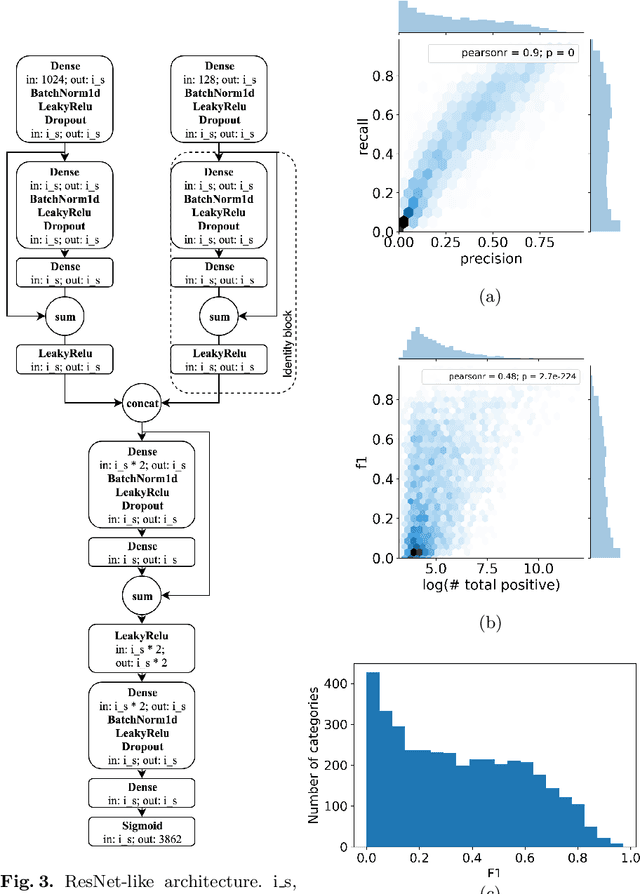
Despite recent advances in computer vision based on various convolutional architectures, video understanding remains an important challenge. In this work, we present and discuss a top solution for the large-scale video classification (labeling) problem introduced as a Kaggle competition based on the YouTube-8M dataset. We show and compare different approaches to preprocessing, data augmentation, model architectures, and model combination. Our final model is based on a large ensemble of video- and frame-level models but fits into rather limiting hardware constraints. We apply an approach based on knowledge distillation to deal with noisy labels in the original dataset and the recently developed mixup technique to improve the basic models.