 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic Transfer to Kyrgyz Using the Treebank Translation Method
Dec 17, 2024

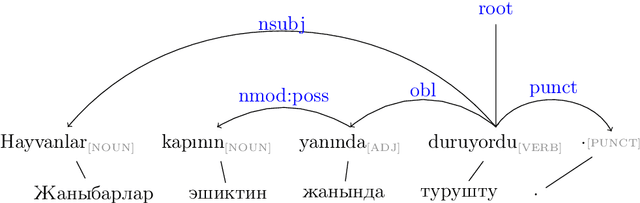
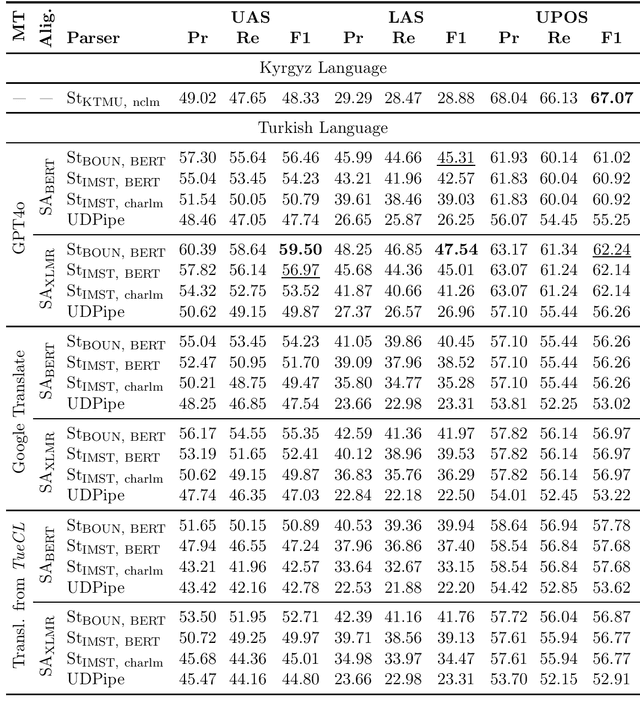
The Kyrgyz language, as a low-resource language, requires significant effort to create high-quality syntactic corpora. This study proposes an approach to simplify the development process of a syntactic corpus for Kyrgyz. We present a tool for transferring syntactic annotations from Turkish to Kyrgyz based on a treebank translation method. The effectiveness of the proposed tool was evaluated using the TueCL treebank. The results demonstrate that this approach achieves higher syntactic annotation accuracy compared to a monolingual model trained on the Kyrgyz KTMU treebank. Additionally, the study introduces a method for assessing the complexity of manual annotation for the resulting syntactic trees, contributing to further optimization of the annotation process.
Benchmarking Multilabel Topic Classification in the Kyrgyz Language
Aug 30, 2023Kyrgyz is a very underrepresented language in terms of modern natural language processing resources. In this work, we present a new public benchmark for topic classification in Kyrgyz, introducing a dataset based on collected and annotated data from the news site 24.KG and presenting several baseline models for news classification in the multilabel setting. We train and evaluate both classical statistical and neural models, reporting the scores, discussing the results, and proposing directions for future work.
RecVAE: a New Variational Autoencoder for Top-N Recommendations with Implicit Feedback
Dec 24, 2019



Recent research has shown the advantages of using autoencoders based on deep neural networks for collaborative filtering. In particular, the recently proposed Mult-VAE model, which used the multinomial likelihood variational autoencoders, has shown excellent results for top-N recommendations. In this work, we propose the Recommender VAE (RecVAE) model that originates from our research on regularization techniques for variational autoencoders. RecVAE introduces several novel ideas to improve Mult-VAE, including a novel composite prior distribution for the latent codes, a new approach to setting the $\beta$ hyperparameter for the $\beta$-VAE framework, and a new approach to training based on alternating updates. In experimental evaluation, we show that RecVAE significantly outperforms previously proposed autoencoder-based models, including Mult-VAE and RaCT, across classical collaborative filtering datasets, and present a detailed ablation study to assess our new developments. Code and models are available at https://github.com/ilya-shenbin/RecVAE.
Synthetic Data for Deep Learning
Sep 25, 2019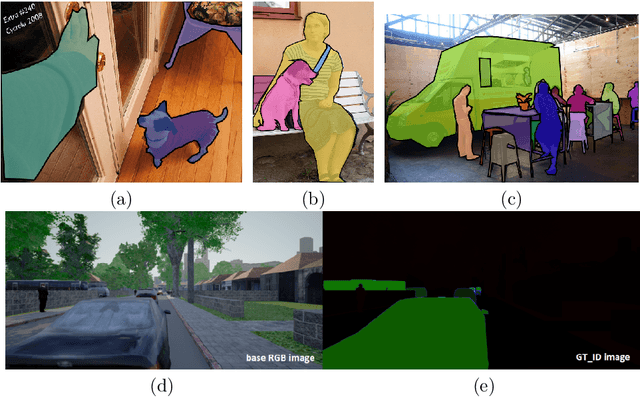
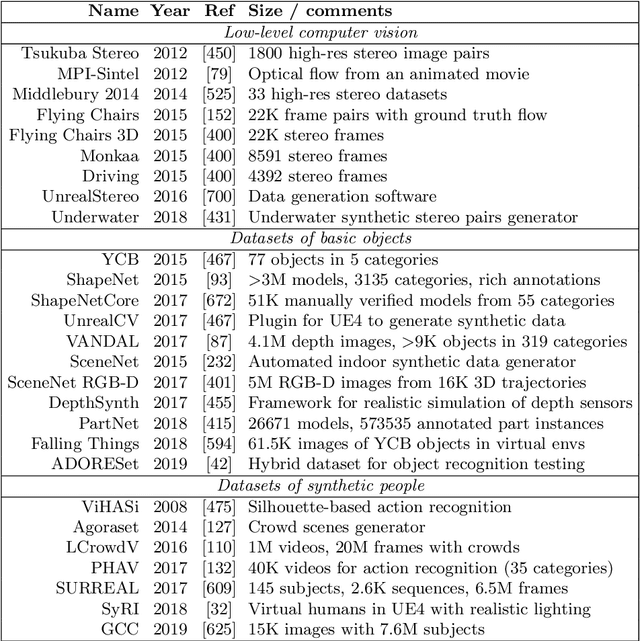

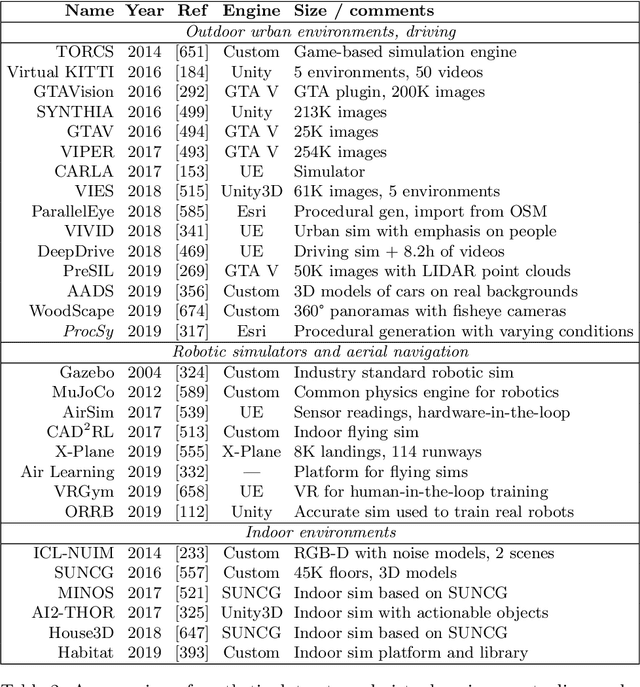
Synthetic data is an increasingly popular tool for training deep learning models, especially in computer vision but also in other areas. In this work, we attempt to provide a comprehensive survey of the various directions in the development and application of synthetic data. First, we discuss synthetic datasets for basic computer vision problems, both low-level (e.g., optical flow estimation) and high-level (e.g., semantic segmentation), synthetic environments and datasets for outdoor and urban scenes (autonomous driving), indoor scenes (indoor navigation), aerial navigation, simulation environments for robotics, applications of synthetic data outside computer vision (in neural programming, bioinformatics, NLP, and more); we also survey the work on improving synthetic data development and alternative ways to produce it such as GANs. Second, we discuss in detail the synthetic-to-real domain adaptation problem that inevitably arises in applications of synthetic data, including synthetic-to-real refinement with GAN-based models and domain adaptation at the feature/model level without explicit data transformations. Third, we turn to privacy-related applications of synthetic data and review the work on generating synthetic datasets with differential privacy guarantees. We conclude by highlighting the most promising directions for further work in synthetic data studies.
AspeRa: Aspect-based Rating Prediction Model
Jan 23, 2019
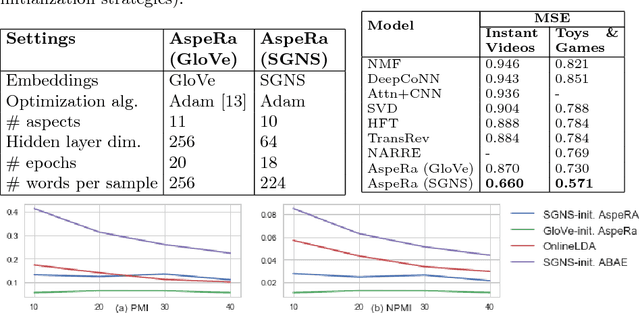
We propose a novel end-to-end Aspect-based Rating Prediction model (AspeRa) that estimates user rating based on review texts for the items and at the same time discovers coherent aspects of reviews that can be used to explain predictions or profile users. The AspeRa model uses max-margin losses for joint item and user embedding learning and a dual-headed architecture; it significantly outperforms recently proposed state-of-the-art models such as DeepCoNN, HFT, NARRE, and TransRev on two real world data sets of user reviews. With qualitative examination of the aspects and quantitative evaluation of rating prediction models based on these aspects, we show how aspect embeddings can be used in a recommender system.
Adapting Convolutional Neural Networks for Geographical Domain Shift
Jan 18, 2019

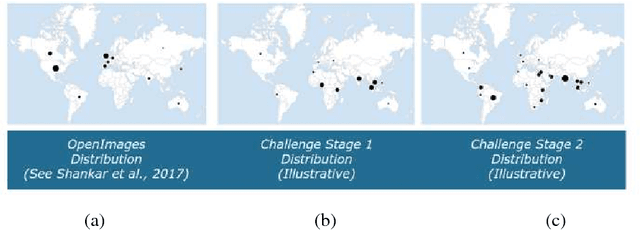
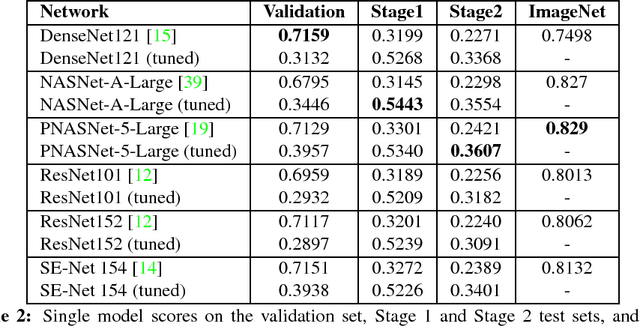
We present the winning solution for the Inclusive Images Competition organized as part of the Conference on Neural Information Processing Systems (NeurIPS 2018) Competition Track. The competition was organized to study ways to cope with domain shift in image processing, specifically geographical shift: the training and two test sets in the competition had different geographical distributions. Our solution has proven to be relatively straightforward and simple: it is an ensemble of several CNNs where only the last layer is fine-tuned with the help of a small labeled set of tuning labels made available by the organizers. We believe that while domain shift remains a formidable problem, our approach opens up new possibilities for alleviating this problem in practice, where small labeled datasets from the target domain are usually either available or can be obtained and labeled cheaply.
Learning State Representations in Complex Systems with Multimodal Data
Nov 30, 2018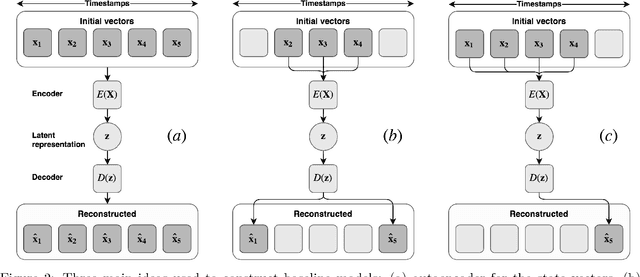

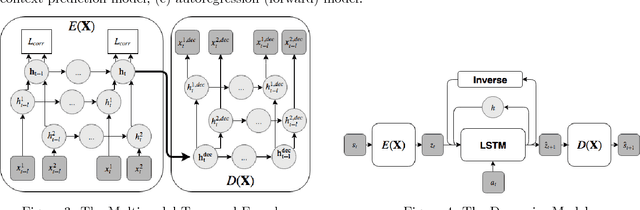
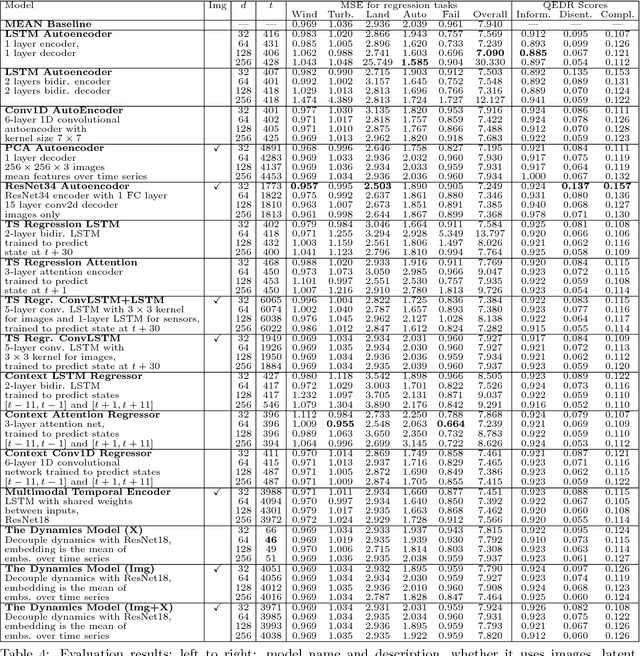
Representation learning becomes especially important for complex systems with multimodal data sources such as cameras or sensors. Recent advances in reinforcement learning and optimal control make it possible to design control algorithms on these latent representations, but the field still lacks a large-scale standard dataset for unified comparison. In this work, we present a large-scale dataset and evaluation framework for representation learning for the complex task of landing an airplane. We implement and compare several approaches to representation learning on this dataset in terms of the quality of simple supervised learning tasks and disentanglement scores. The resulting representations can be used for further tasks such as anomaly detection, optimal control, model-based reinforcement learning, and other applications.
SEIGAN: Towards Compositional Image Generation by Simultaneously Learning to Segment, Enhance, and Inpaint
Nov 19, 2018



We present a novel approach to image manipulation and understanding by simultaneously learning to segment object masks, paste objects to another background image, and remove them from original images. For this purpose, we develop a novel generative model for compositional image generation, SEIGAN (Segment-Enhance-Inpaint Generative Adversarial Network), which learns these three operations together in an adversarial architecture with additional cycle consistency losses. To train, SEIGAN needs only bounding box supervision and does not require pairing or ground truth masks. SEIGAN produces better generated images (evaluated by human assessors) than other approaches and produces high-quality segmentation masks, improving over other adversarially trained approaches and getting closer to the results of fully supervised training.
Label Denoising with Large Ensembles of Heterogeneous Neural Networks
Sep 12, 2018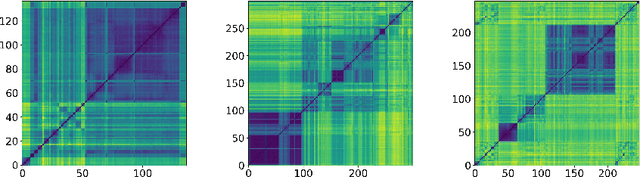
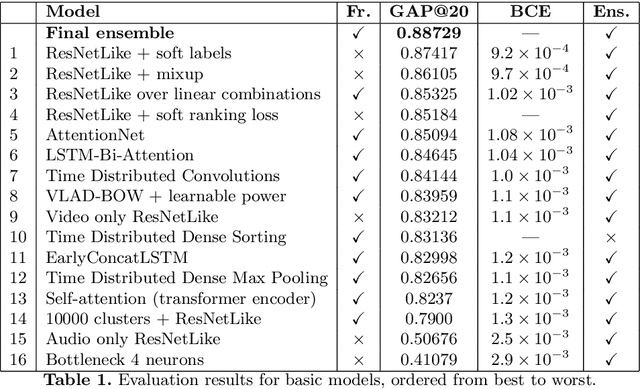
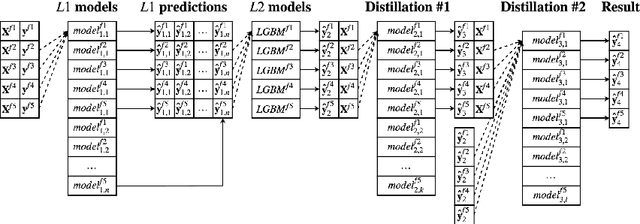
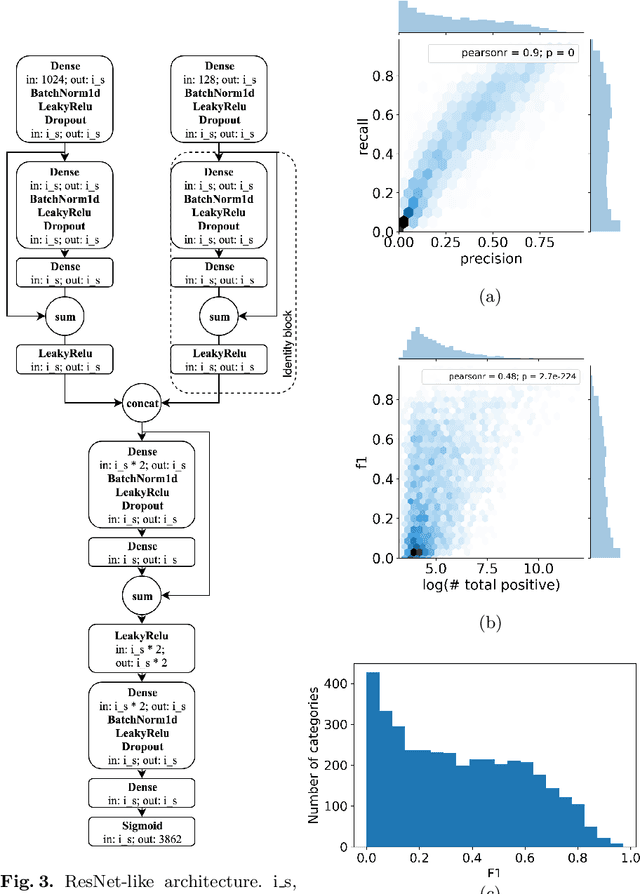
Despite recent advances in computer vision based on various convolutional architectures, video understanding remains an important challenge. In this work, we present and discuss a top solution for the large-scale video classification (labeling) problem introduced as a Kaggle competition based on the YouTube-8M dataset. We show and compare different approaches to preprocessing, data augmentation, model architectures, and model combination. Our final model is based on a large ensemble of video- and frame-level models but fits into rather limiting hardware constraints. We apply an approach based on knowledge distillation to deal with noisy labels in the original dataset and the recently developed mixup technique to improve the basic models.