 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data for Deep Learning
Paper and Code
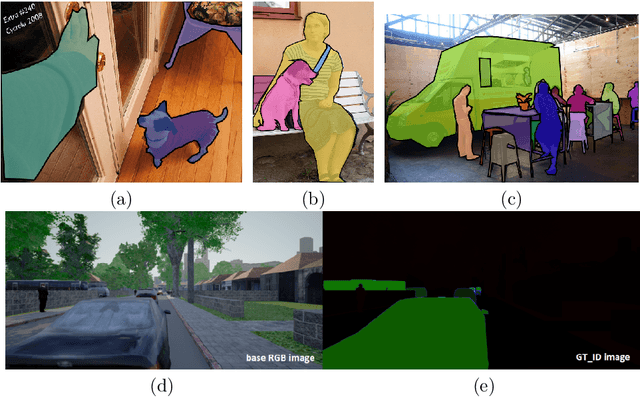
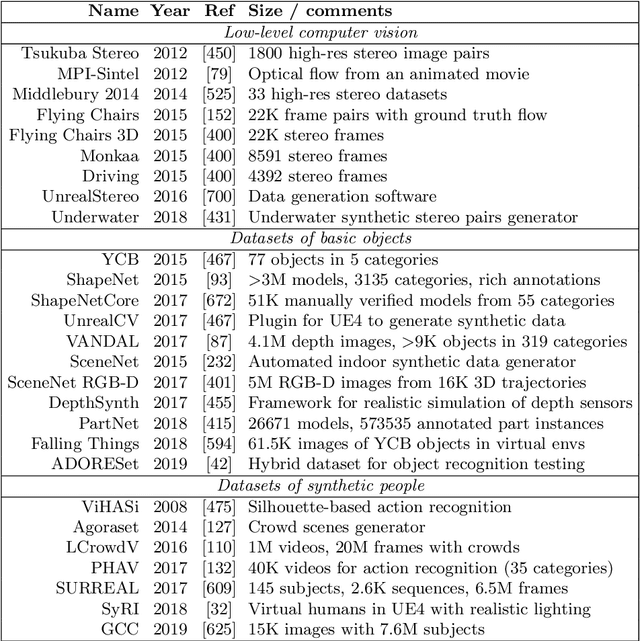

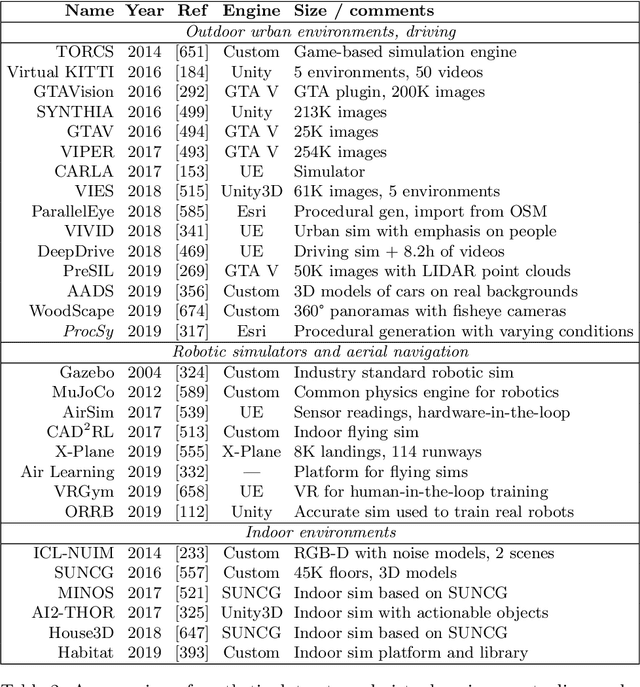
Synthetic data is an increasingly popular tool for training deep learning models, especially in computer vision but also in other areas. In this work, we attempt to provide a comprehensive survey of the various directions in the development and application of synthetic data. First, we discuss synthetic datasets for basic computer vision problems, both low-level (e.g., optical flow estimation) and high-level (e.g., semantic segmentation), synthetic environments and datasets for outdoor and urban scenes (autonomous driving), indoor scenes (indoor navigation), aerial navigation, simulation environments for robotics, applications of synthetic data outside computer vision (in neural programming, bioinformatics, NLP, and more); we also survey the work on improving synthetic data development and alternative ways to produce it such as GANs. Second, we discuss in detail the synthetic-to-real domain adaptation problem that inevitably arises in applications of synthetic data, including synthetic-to-real refinement with GAN-based models and domain adaptation at the feature/model level without explicit data transformations. Third, we turn to privacy-related applications of synthetic data and review the work on generating synthetic datasets with differential privacy guarantees. We conclude by highlighting the most promising directions for further work in synthetic data studies.