 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling the Knowledge from Normalizing Flows
Jun 25, 2021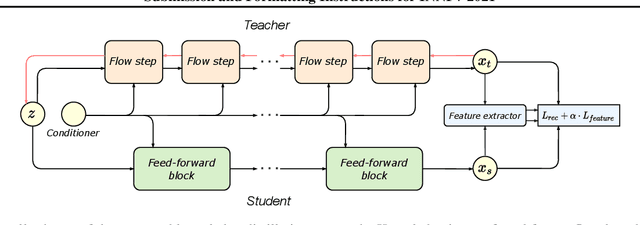
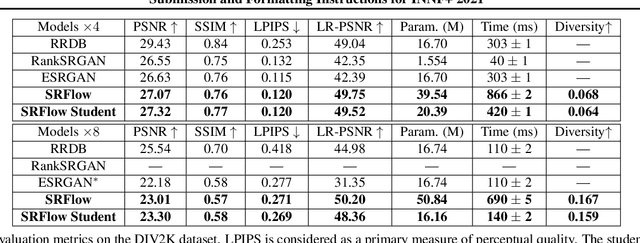
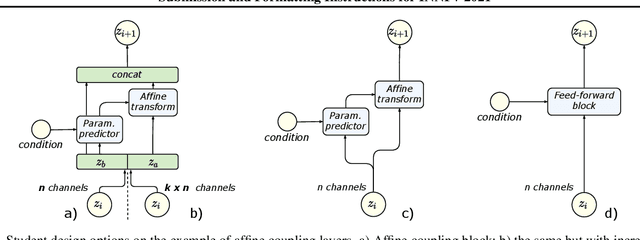

Normalizing flows are a powerful class of generative models demonstrating strong performance in several speech and vision problems. In contrast to other generative models, normalizing flows are latent variable models with tractable likelihoods and allow for stable training. However, they have to be carefully designed to represent invertible functions with efficient Jacobian determinant calculation. In practice, these requirements lead to overparameterized and sophisticated architectures that are inferior to alternative feed-forward models in terms of inference time and memory consumption. In this work, we investigate whether one can distill flow-based models into more efficient alternatives. We provide a positive answer to this question by proposing a simple distillation approach and demonstrating its effectiveness on state-of-the-art conditional flow-based models for image super-resolution and speech synthesis.
Free-Lunch Saliency via Attention in Atari Agents
Aug 07, 2019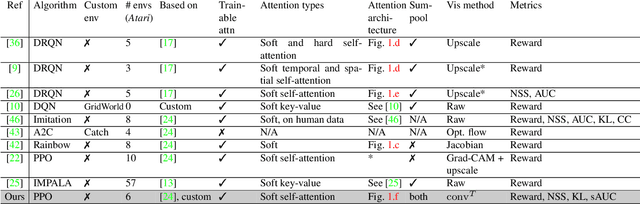
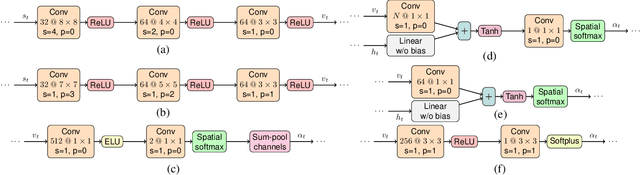
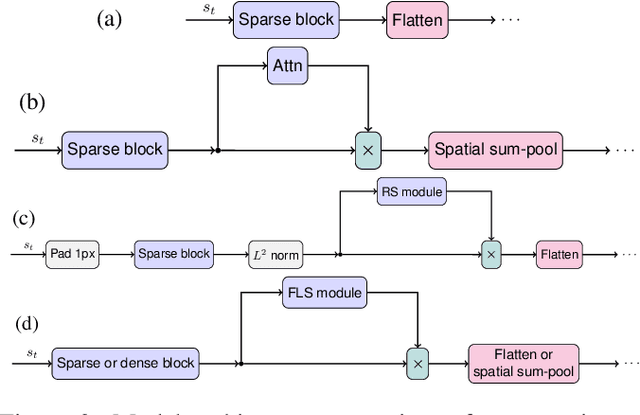
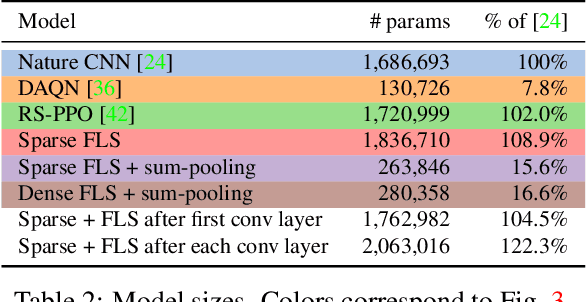
We propose a new approach to visualize saliency maps for deep neural network models and apply it to deep reinforcement learning agents trained on Atari environments. Our method adds an attention module that we call FLS (Free Lunch Saliency) to the feature extractor from an established baseline (Mnih et al., 2015). This addition results in a trainable model that can produce saliency maps, i.e., visualizations of the importance of different parts of the input for the agent's current decision making. We show experimentally that a network with an FLS module exhibits performance similar to the baseline (i.e., it is "free", with no performance cost) and can be used as a drop-in replacement for reinforcement learning agents. We also design another feature extractor that scores slightly lower but provides higher-fidelity visualizations. In addition to attained scores, we report saliency metrics evaluated on the Atari-HEAD dataset of human gameplay.
Learning State Representations in Complex Systems with Multimodal Data
Nov 30, 2018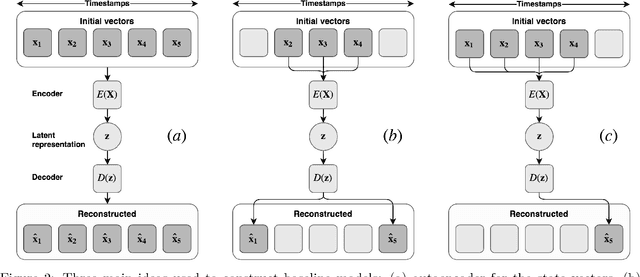

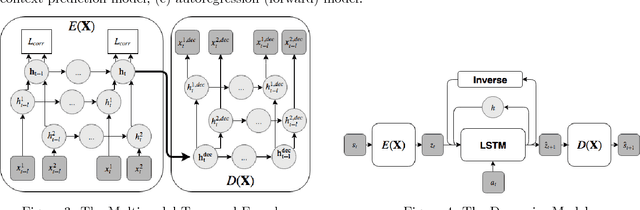
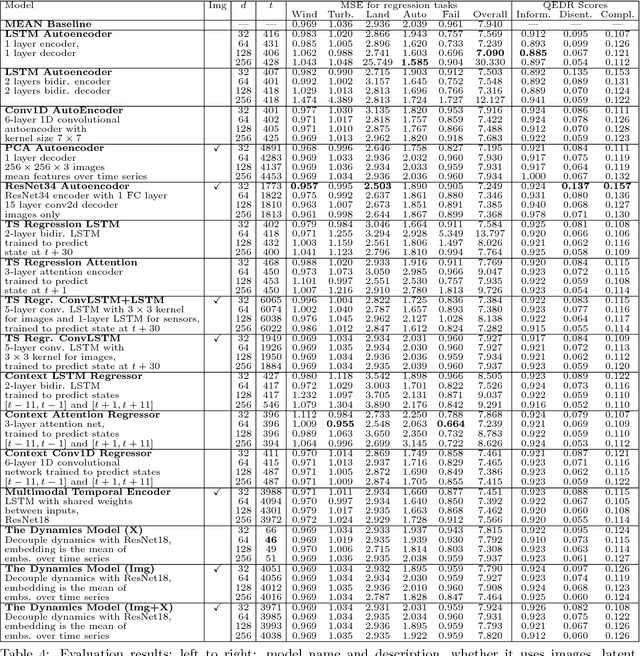
Representation learning becomes especially important for complex systems with multimodal data sources such as cameras or sensors. Recent advances in reinforcement learning and optimal control make it possible to design control algorithms on these latent representations, but the field still lacks a large-scale standard dataset for unified comparison. In this work, we present a large-scale dataset and evaluation framework for representation learning for the complex task of landing an airplane. We implement and compare several approaches to representation learning on this dataset in terms of the quality of simple supervised learning tasks and disentanglement scores. The resulting representations can be used for further tasks such as anomaly detection, optimal control, model-based reinforcement learning, and other applications.
Label Denoising with Large Ensembles of Heterogeneous Neural Networks
Sep 12, 2018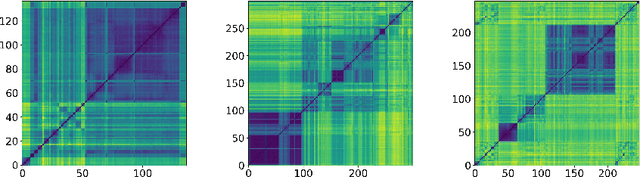
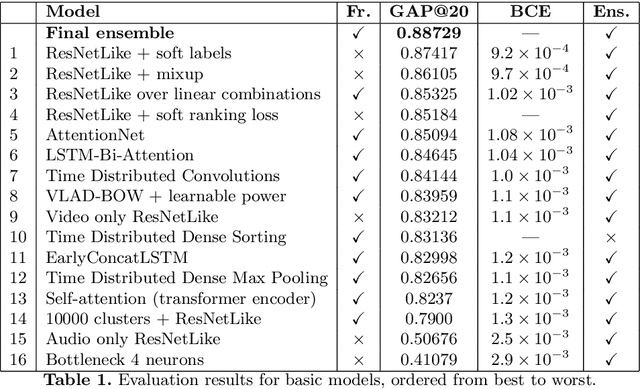
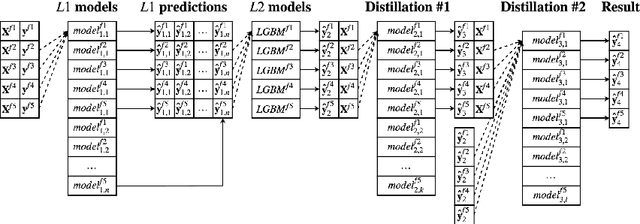
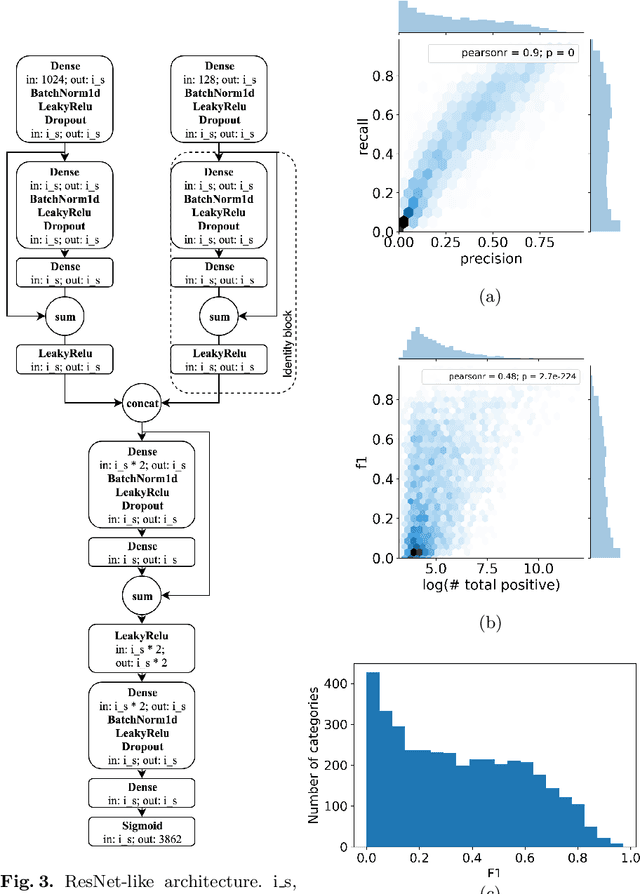
Despite recent advances in computer vision based on various convolutional architectures, video understanding remains an important challenge. In this work, we present and discuss a top solution for the large-scale video classification (labeling) problem introduced as a Kaggle competition based on the YouTube-8M dataset. We show and compare different approaches to preprocessing, data augmentation, model architectures, and model combination. Our final model is based on a large ensemble of video- and frame-level models but fits into rather limiting hardware constraints. We apply an approach based on knowledge distillation to deal with noisy labels in the original dataset and the recently developed mixup technique to improve the basic models.