 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling the Knowledge from Normalizing Flows
Paper and Code
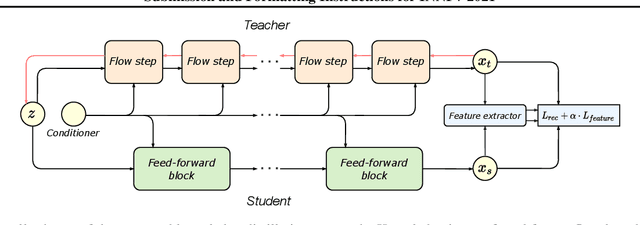
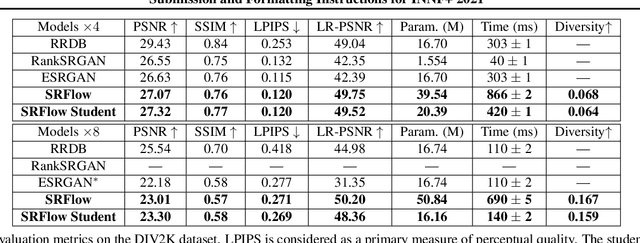
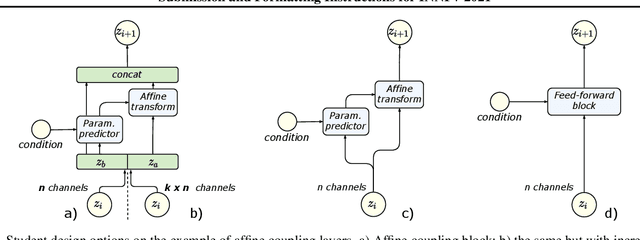

Normalizing flows are a powerful class of generative models demonstrating strong performance in several speech and vision problems. In contrast to other generative models, normalizing flows are latent variable models with tractable likelihoods and allow for stable training. However, they have to be carefully designed to represent invertible functions with efficient Jacobian determinant calculation. In practice, these requirements lead to overparameterized and sophisticated architectures that are inferior to alternative feed-forward models in terms of inference time and memory consumption. In this work, we investigate whether one can distill flow-based models into more efficient alternatives. We provide a positive answer to this question by proposing a simple distillation approach and demonstrating its effectiveness on state-of-the-art conditional flow-based models for image super-resolution and speech synthesis.