 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneFactor: Factored Latent 3D Diffusion for Controllable 3D Scene Generation
Dec 03, 2024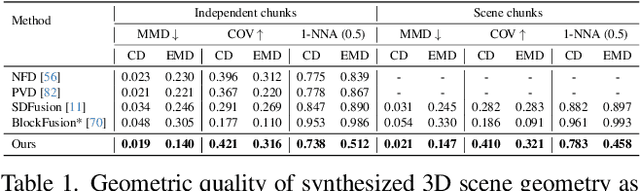
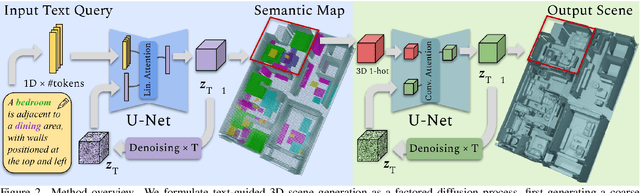
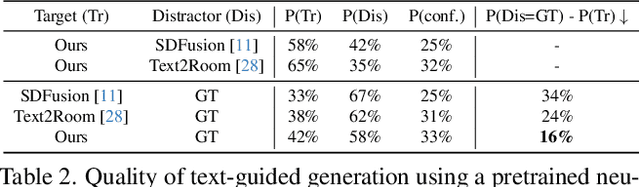
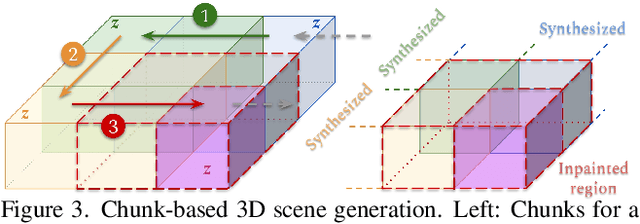
We present SceneFactor, a diffusion-based approach for large-scale 3D scene generation that enables controllable generation and effortless editing. SceneFactor enables text-guided 3D scene synthesis through our factored diffusion formulation, leveraging latent semantic and geometric manifolds for generation of arbitrary-sized 3D scenes. While text input enables easy, controllable generation, text guidance remains imprecise for intuitive, localized editing and manipulation of the generated 3D scenes. Our factored semantic diffusion generates a proxy semantic space composed of semantic 3D boxes that enables controllable editing of generated scenes by adding, removing, changing the size of the semantic 3D proxy boxes that guides high-fidelity, consistent 3D geometric editing. Extensive experiments demonstrate that our approach enables high-fidelity 3D scene synthesis with effective controllable editing through our factored diffusion approach.
Mesh2Tex: Generating Mesh Textures from Image Queries
Apr 12, 2023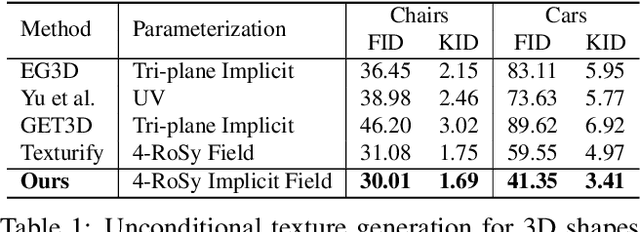
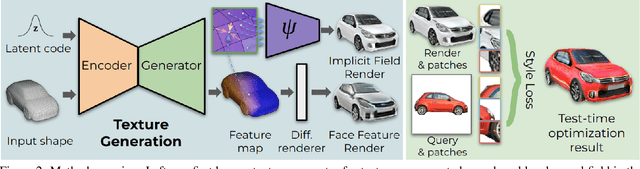
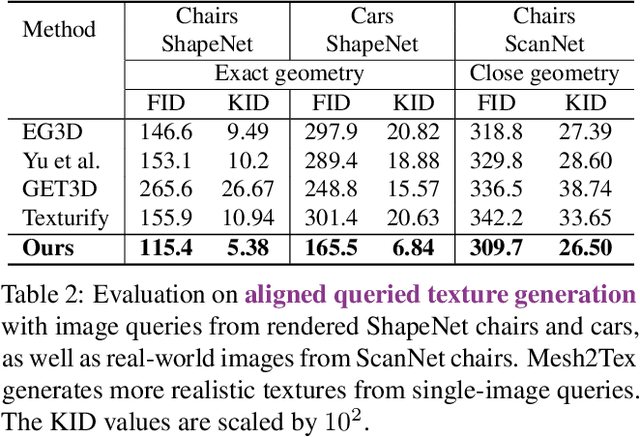
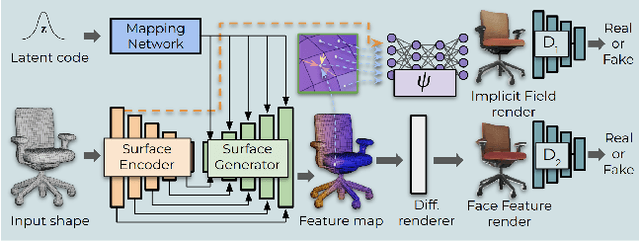
Remarkable advances have been achieved recently in learning neural representations that characterize object geometry, while generating textured objects suitable for downstream applications and 3D rendering remains at an early stage. In particular, reconstructing textured geometry from images of real objects is a significant challenge -- reconstructed geometry is often inexact, making realistic texturing a significant challenge. We present Mesh2Tex, which learns a realistic object texture manifold from uncorrelated collections of 3D object geometry and photorealistic RGB images, by leveraging a hybrid mesh-neural-field texture representation. Our texture representation enables compact encoding of high-resolution textures as a neural field in the barycentric coordinate system of the mesh faces. The learned texture manifold enables effective navigation to generate an object texture for a given 3D object geometry that matches to an input RGB image, which maintains robustness even under challenging real-world scenarios where the mesh geometry approximates an inexact match to the underlying geometry in the RGB image. Mesh2Tex can effectively generate realistic object textures for an object mesh to match real images observations towards digitization of real environments, significantly improving over previous state of the art.
Neural Part Priors: Learning to Optimize Part-Based Object Completion in RGB-D Scans
Mar 17, 2022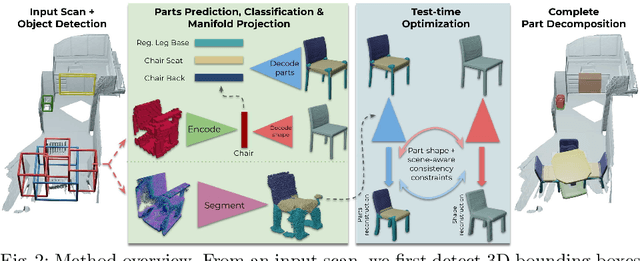
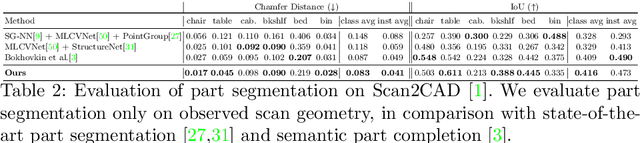
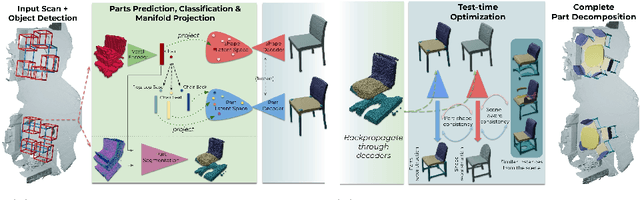
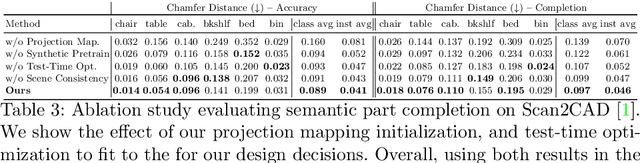
3D object recognition has seen significant advances in recent years, showing impressive performance on real-world 3D scan benchmarks, but lacking in object part reasoning, which is fundamental to higher-level scene understanding such as inter-object similarities or object functionality. Thus, we propose to leverage large-scale synthetic datasets of 3D shapes annotated with part information to learn Neural Part Priors (NPPs), optimizable spaces characterizing geometric part priors. Crucially, we can optimize over the learned part priors in order to fit to real-world scanned 3D scenes at test time, enabling robust part decomposition of the real objects in these scenes that also estimates the complete geometry of the object while fitting accurately to the observed real geometry. Moreover, this enables global optimization over geometrically similar detected objects in a scene, which often share strong geometric commonalities, enabling scene-consistent part decompositions. Experiments on the ScanNet dataset demonstrate that NPPs significantly outperforms state of the art in part decomposition and object completion in real-world scenes.
Towards Part-Based Understanding of RGB-D Scans
Dec 03, 2020
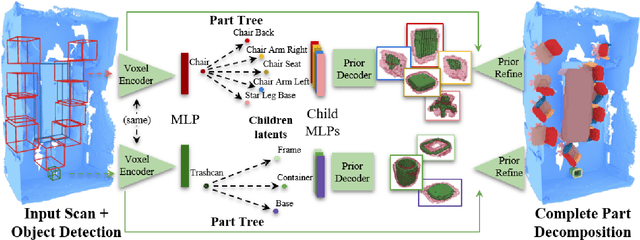

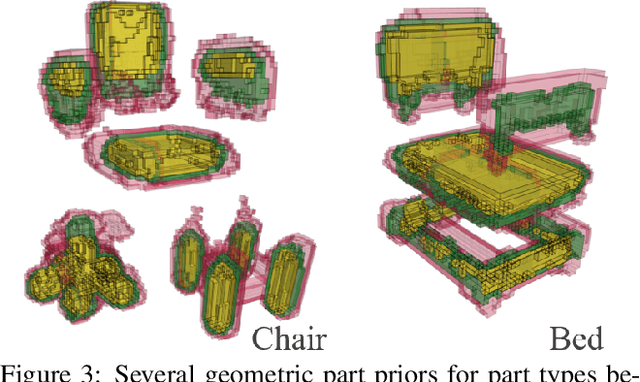
Recent advances in 3D semantic scene understanding have shown impressive progress in 3D instance segmentation, enabling object-level reasoning about 3D scenes; however, a finer-grained understanding is required to enable interactions with objects and their functional understanding. Thus, we propose the task of part-based scene understanding of real-world 3D environments: from an RGB-D scan of a scene, we detect objects, and for each object predict its decomposition into geometric part masks, which composed together form the complete geometry of the observed object. We leverage an intermediary part graph representation to enable robust completion as well as building of part priors, which we use to construct the final part mask predictions. Our experiments demonstrate that guiding part understanding through part graph to part prior-based predictions significantly outperforms alternative approaches to the task of semantic part completion.
CAD-Deform: Deformable Fitting of CAD Models to 3D Scans
Jul 23, 2020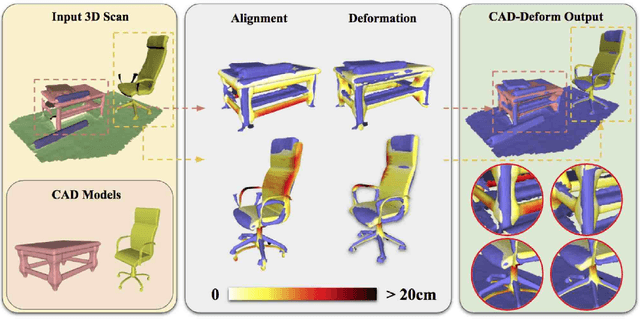
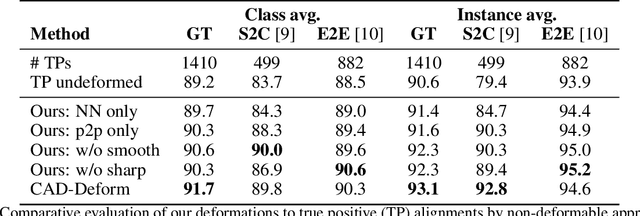
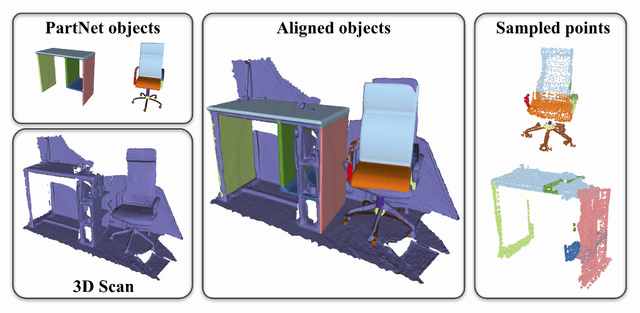

Shape retrieval and alignment are a promising avenue towards turning 3D scans into lightweight CAD representations that can be used for content creation such as mobile or AR/VR gaming scenarios. Unfortunately, CAD model retrieval is limited by the availability of models in standard 3D shape collections (e.g., ShapeNet). In this work, we address this shortcoming by introducing CAD-Deform, a method which obtains more accurate CAD-to-scan fits by non-rigidly deforming retrieved CAD models. Our key contribution is a new non-rigid deformation model incorporating smooth transformations and preservation of sharp features, that simultaneously achieves very tight fits from CAD models to the 3D scan and maintains the clean, high-quality surface properties of hand-modeled CAD objects. A series of thorough experiments demonstrate that our method achieves significantly tighter scan-to-CAD fits, allowing a more accurate digital replica of the scanned real-world environment while preserving important geometric features present in synthetic CAD environments.
Boundary Loss for Remote Sensing Imagery Semantic Segmentation
May 20, 2019
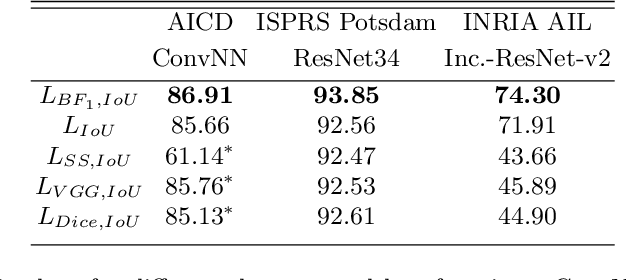

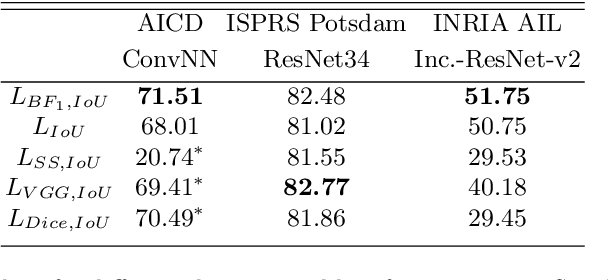
In response to the growing importance of geospatial data, its analysis including semantic segmentation becomes an increasingly popular task in computer vision today. Convolutional neural networks are powerful visual models that yield hierarchies of features and practitioners widely use them to process remote sensing data. When performing remote sensing image segmentation, multiple instances of one class with precisely defined boundaries are often the case, and it is crucial to extract those boundaries accurately. The accuracy of segments boundaries delineation influences the quality of the whole segmented areas explicitly. However, widely-used segmentation loss functions such as BCE, IoU loss or Dice loss do not penalize misalignment of boundaries sufficiently. In this paper, we propose a novel loss function, namely a differentiable surrogate of a metric accounting accuracy of boundary detection. We can use the loss function with any neural network for binary segmentation. We performed validation of our loss function with various modifications of UNet on a synthetic dataset, as well as using real-world data (ISPRS Potsdam, INRIA AIL). Trained with the proposed loss function, models outperform baseline methods in terms of IoU score.
* 14 pages, 10 figures