 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
Mar 11, 2022
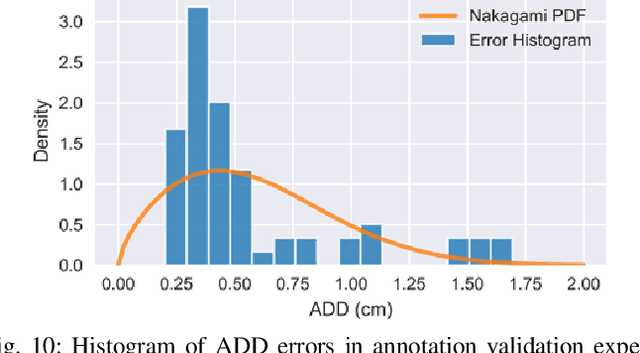
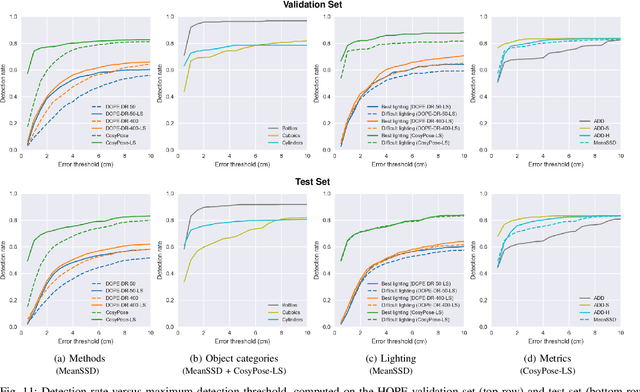
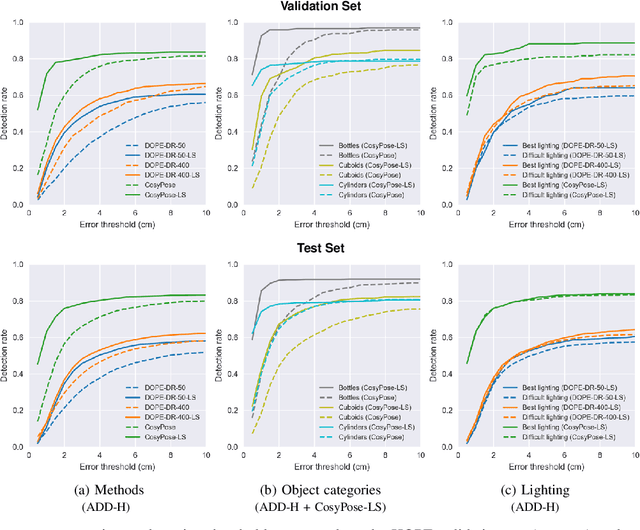
We present a new dataset for 6-DoF pose estimation of known objects, with a focus on robotic manipulation research. We propose a set of toy grocery objects, whose physical instantiations are readily available for purchase and are appropriately sized for robotic grasping and manipulation. We provide 3D scanned textured models of these objects, suitable for generating synthetic training data, as well as RGBD images of the objects in challenging, cluttered scenes exhibiting partial occlusion, extreme lighting variations, multiple instances per image, and a large variety of poses. Using semi-automated RGBD-to-model texture correspondences, the images are annotated with ground truth poses that were verified empirically to be accurate to within a few millimeters. We also propose a new pose evaluation metric called {ADD-H} based upon the Hungarian assignment algorithm that is robust to symmetries in object geometry without requiring their explicit enumeration. We share pre-trained pose estimators for all the toy grocery objects, along with their baseline performance on both validation and test sets. We offer this dataset to the community to help connect the efforts of computer vision researchers with the needs of roboticists.
Camera-to-Robot Pose Estimation from a Single Image
Dec 05, 2019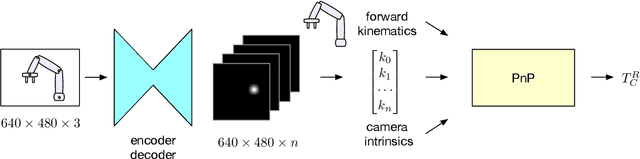

We present an approach for estimating the pose of a camera with respect to a robot from a single image. Our method uses a deep neural network to process an RGB image from the camera to detect 2D keypoints on the robot. The network is trained entirely on simulated data using domain randomization. Perspective-$n$-point (P$n$P) is then used to recover the camera extrinsics, assuming that the joint configuration of the robot manipulator is known. Unlike classic hand-eye calibration systems, our method does not require an off-line calibration step but rather is capable of computing the camera extrinsics from a single frame, thus opening the possibility of on-line calibration. We show experimental results for three different camera sensors, demonstrating that our approach is able to achieve accuracy with a single frame that is better than that of classic off-line hand-eye calibration using multiple frames. With additional frames, accuracy improves even further. Code, datasets, and pretrained models for three widely-used robot manipulators will be made available.
Directional Semantic Grasping of Real-World Objects: From Simulation to Reality
Sep 04, 2019


We present a deep reinforcement learning approach to grasp semantically meaningful objects from a particular direction. The system is trained entirely in simulation, with sim-to-real transfer accomplished by using a simulator that models physical contact and produces photorealistic imagery with domain randomized backgrounds. The system is an example of end-to-end (mapping input monocular RGB images to output Cartesian motor commands) grasping of objects from multiple pre-defined object-centric orientations, such as from the side or top. Coupled with a real-time 6-DoF object pose estimator, the eye-in-hand system is capable of grasping objects anywhere within the graspable workspace. Results are shown in both simulation and the real world, demonstrating the effectiveness of the approach.
Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects
Sep 27, 2018

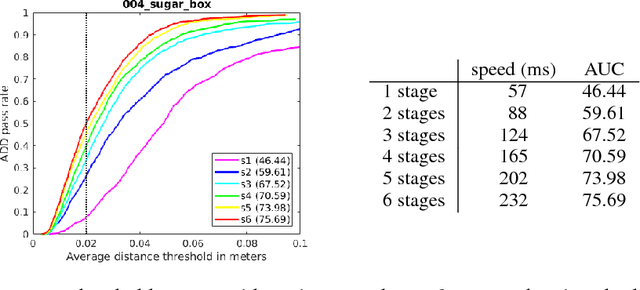
Using synthetic data for training deep neural networks for robotic manipulation holds the promise of an almost unlimited amount of pre-labeled training data, generated safely out of harm's way. One of the key challenges of synthetic data, to date, has been to bridge the so-called reality gap, so that networks trained on synthetic data operate correctly when exposed to real-world data. We explore the reality gap in the context of 6-DoF pose estimation of known objects from a single RGB image. We show that for this problem the reality gap can be successfully spanned by a simple combination of domain randomized and photorealistic data. Using synthetic data generated in this manner, we introduce a one-shot deep neural network that is able to perform competitively against a state-of-the-art network trained on a combination of real and synthetic data. To our knowledge, this is the first deep network trained only on synthetic data that is able to achieve state-of-the-art performance on 6-DoF object pose estimation. Our network also generalizes better to novel environments including extreme lighting conditions, for which we show qualitative results. Using this network we demonstrate a real-time system estimating object poses with sufficient accuracy for real-world semantic grasping of known household objects in clutter by a real robot.
Falling Things: A Synthetic Dataset for 3D Object Detection and Pose Estimation
Jul 10, 2018
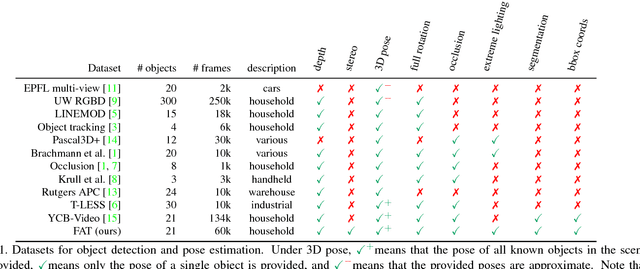
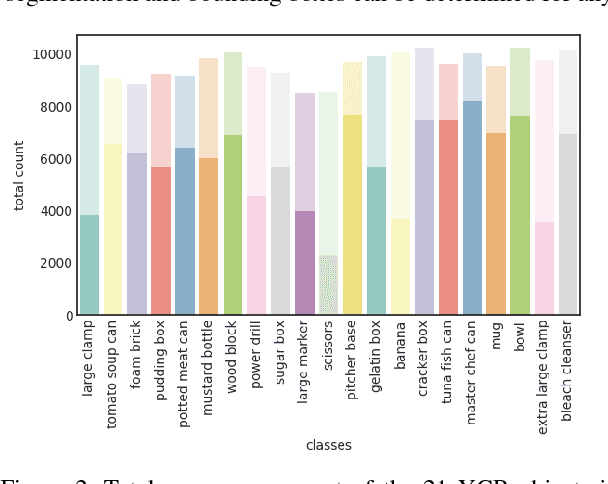
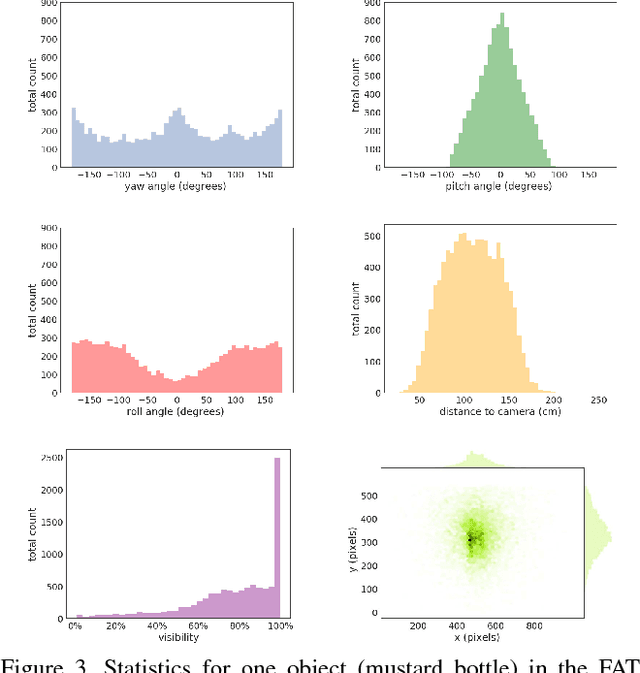
We present a new dataset, called Falling Things (FAT), for advancing the state-of-the-art in object detection and 3D pose estimation in the context of robotics. By synthetically combining object models and backgrounds of complex composition and high graphical quality, we are able to generate photorealistic images with accurate 3D pose annotations for all objects in all images. Our dataset contains 60k annotated photos of 21 household objects taken from the YCB dataset. For each image, we provide the 3D poses, per-pixel class segmentation, and 2D/3D bounding box coordinates for all objects. To facilitate testing different input modalities, we provide mono and stereo RGB images, along with registered dense depth images. We describe in detail the generation process and statistical analysis of the data.
Synthetically Trained Neural Networks for Learning Human-Readable Plans from Real-World Demonstrations
Jul 10, 2018

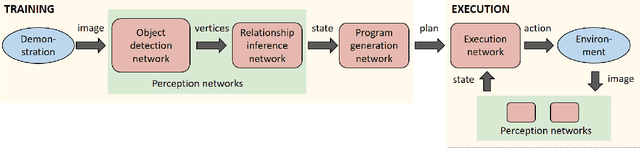
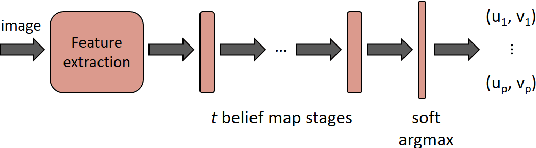
We present a system to infer and execute a human-readable program from a real-world demonstration. The system consists of a series of neural networks to perform perception, program generation, and program execution. Leveraging convolutional pose machines, the perception network reliably detects the bounding cuboids of objects in real images even when severely occluded, after training only on synthetic images using domain randomization. To increase the applicability of the perception network to new scenarios, the network is formulated to predict in image space rather than in world space. Additional networks detect relationships between objects, generate plans, and determine actions to reproduce a real-world demonstration. The networks are trained entirely in simulation, and the system is tested in the real world on the pick-and-place problem of stacking colored cubes using a Baxter robot.
Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization
Apr 23, 2018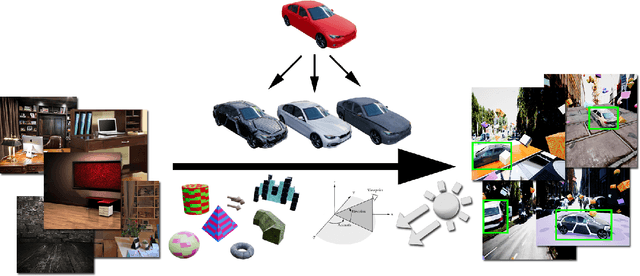



We present a system for training deep neural networks for object detection using synthetic images. To handle the variability in real-world data, the system relies upon the technique of domain randomization, in which the parameters of the simulator$-$such as lighting, pose, object textures, etc.$-$are randomized in non-realistic ways to force the neural network to learn the essential features of the object of interest. We explore the importance of these parameters, showing that it is possible to produce a network with compelling performance using only non-artistically-generated synthetic data. With additional fine-tuning on real data, the network yields better performance than using real data alone. This result opens up the possibility of using inexpensive synthetic data for training neural networks while avoiding the need to collect large amounts of hand-annotated real-world data or to generate high-fidelity synthetic worlds$-$both of which remain bottlenecks for many applications. The approach is evaluated on bounding box detection of cars on the KITTI dataset.