 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
Mar 11, 2022
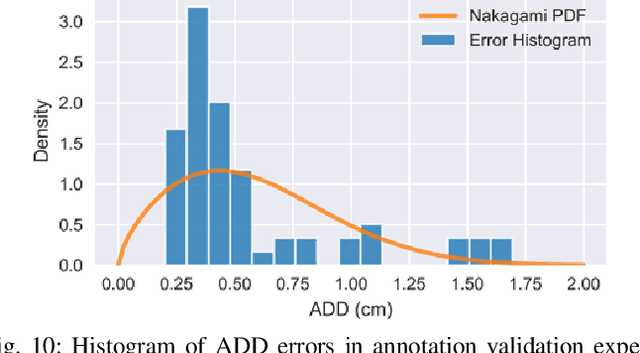
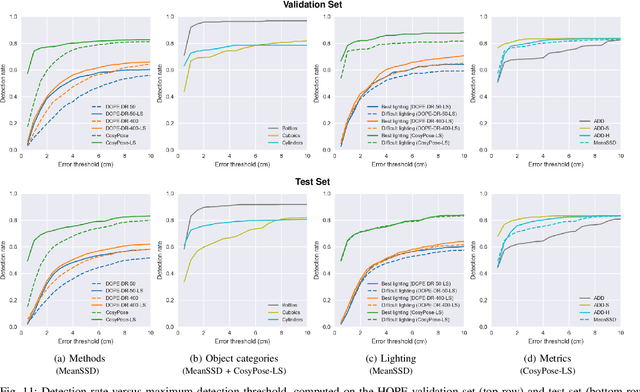
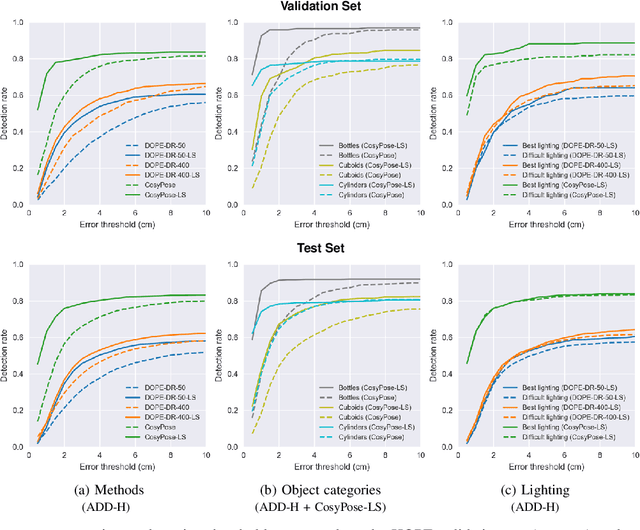
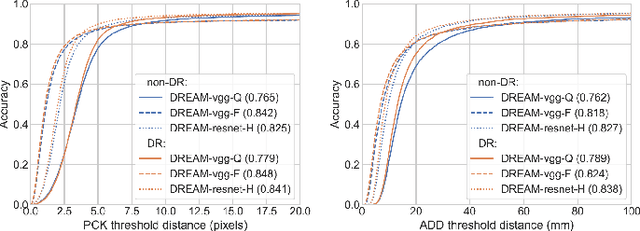
We present a new dataset for 6-DoF pose estimation of known objects, with a focus on robotic manipulation research. We propose a set of toy grocery objects, whose physical instantiations are readily available for purchase and are appropriately sized for robotic grasping and manipulation. We provide 3D scanned textured models of these objects, suitable for generating synthetic training data, as well as RGBD images of the objects in challenging, cluttered scenes exhibiting partial occlusion, extreme lighting variations, multiple instances per image, and a large variety of poses. Using semi-automated RGBD-to-model texture correspondences, the images are annotated with ground truth poses that were verified empirically to be accurate to within a few millimeters. We also propose a new pose evaluation metric called {ADD-H} based upon the Hungarian assignment algorithm that is robust to symmetries in object geometry without requiring their explicit enumeration. We share pre-trained pose estimators for all the toy grocery objects, along with their baseline performance on both validation and test sets. We offer this dataset to the community to help connect the efforts of computer vision researchers with the needs of roboticists.
Indirect Object-to-Robot Pose Estimation from an External Monocular RGB Camera
Aug 26, 2020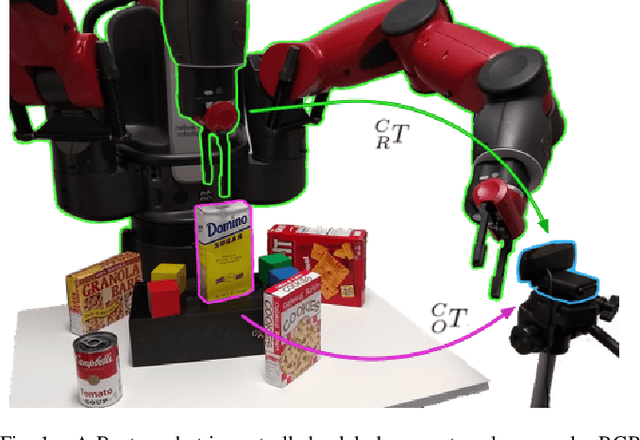


We present a robotic grasping system that uses a single external monocular RGB camera as input. The object-to-robot pose is computed indirectly by combining the output of two neural networks: one that estimates the object-to-camera pose, and another that estimates the robot-to-camera pose. Both networks are trained entirely on synthetic data, relying on domain randomization to bridge the sim-to-real gap. Because the latter network performs online camera calibration, the camera can be moved freely during execution without affecting the quality of the grasp. Experimental results analyze the effect of camera placement, image resolution, and pose refinement in the context of grasping several household objects. We also present results on a new set of 28 textured household toy grocery objects, which have been selected to be accessible to other researchers. To aid reproducibility of the research, we offer 3D scanned textured models, along with pre-trained weights for pose estimation.
Camera-to-Robot Pose Estimation from a Single Image
Dec 05, 2019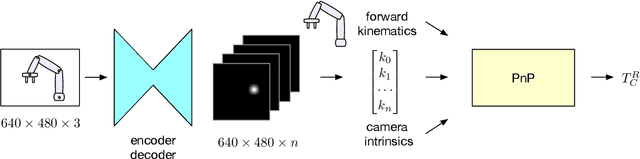

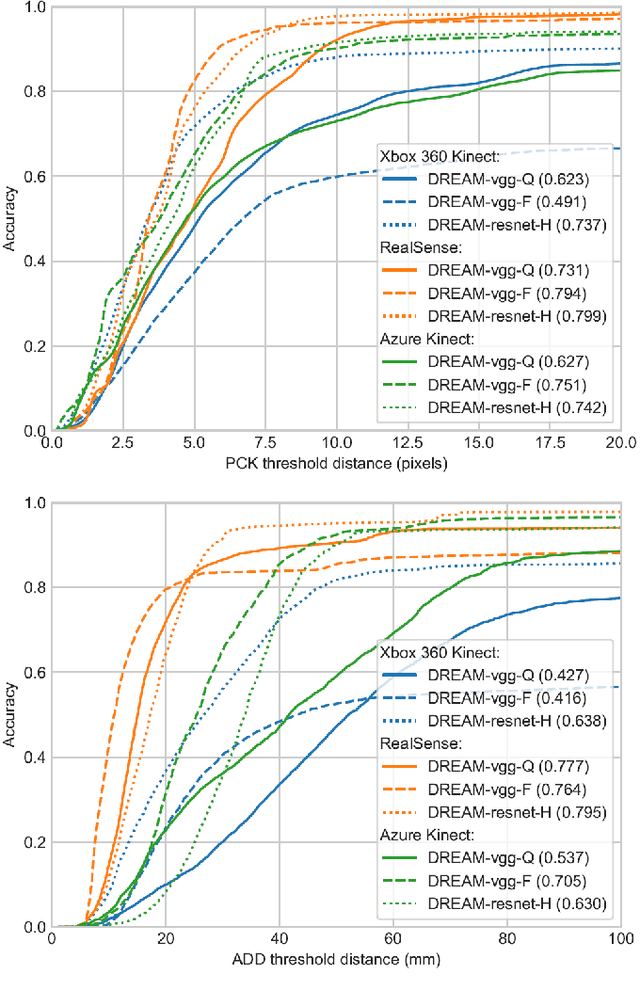
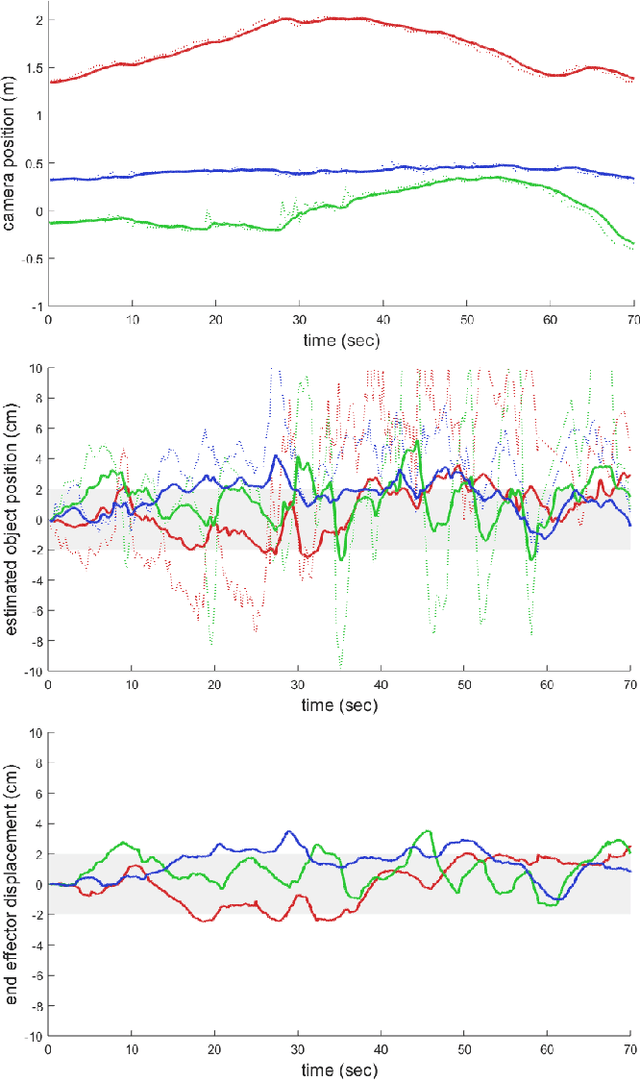
We present an approach for estimating the pose of a camera with respect to a robot from a single image. Our method uses a deep neural network to process an RGB image from the camera to detect 2D keypoints on the robot. The network is trained entirely on simulated data using domain randomization. Perspective-$n$-point (P$n$P) is then used to recover the camera extrinsics, assuming that the joint configuration of the robot manipulator is known. Unlike classic hand-eye calibration systems, our method does not require an off-line calibration step but rather is capable of computing the camera extrinsics from a single frame, thus opening the possibility of on-line calibration. We show experimental results for three different camera sensors, demonstrating that our approach is able to achieve accuracy with a single frame that is better than that of classic off-line hand-eye calibration using multiple frames. With additional frames, accuracy improves even further. Code, datasets, and pretrained models for three widely-used robot manipulators will be made available.