 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Semantic Grasping of Real-World Objects: From Simulation to Reality
Sep 04, 2019
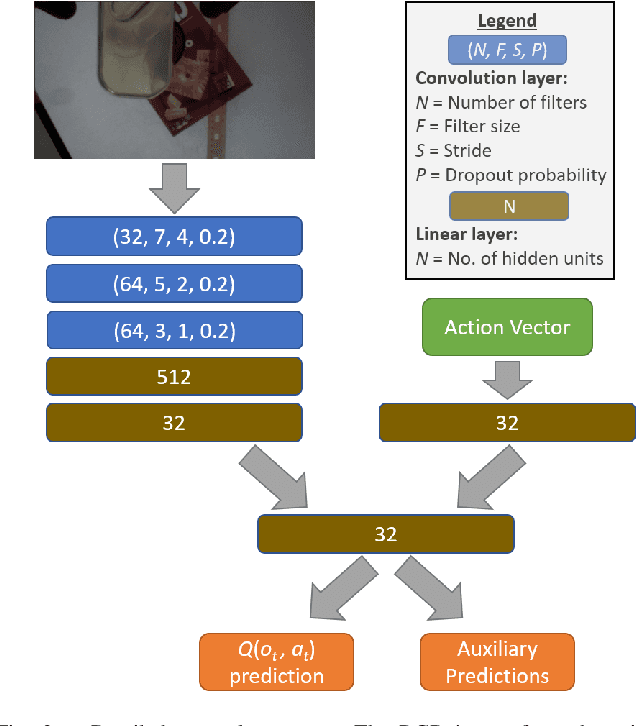


We present a deep reinforcement learning approach to grasp semantically meaningful objects from a particular direction. The system is trained entirely in simulation, with sim-to-real transfer accomplished by using a simulator that models physical contact and produces photorealistic imagery with domain randomized backgrounds. The system is an example of end-to-end (mapping input monocular RGB images to output Cartesian motor commands) grasping of objects from multiple pre-defined object-centric orientations, such as from the side or top. Coupled with a real-time 6-DoF object pose estimator, the eye-in-hand system is capable of grasping objects anywhere within the graspable workspace. Results are shown in both simulation and the real world, demonstrating the effectiveness of the approach.