 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisplacement-Invariant Cost Computation for Efficient Stereo Matching
Paper and Code
Dec 01, 2020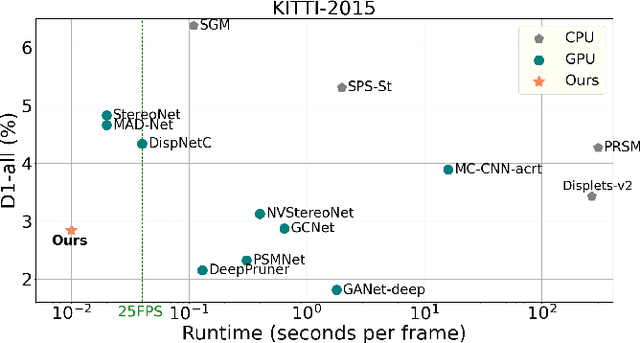

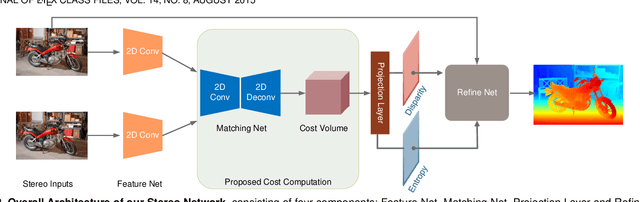
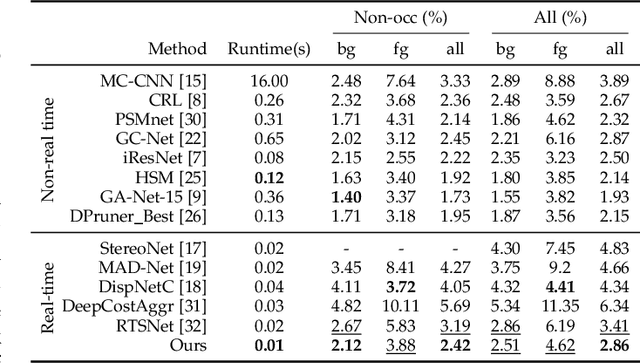
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.