 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deeper look at depth pruning of LLMs
Jul 23, 2024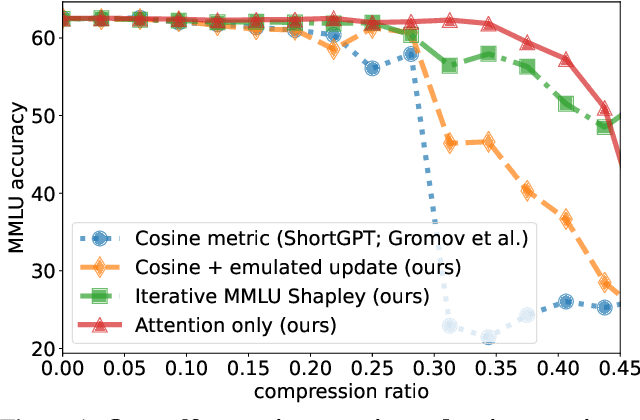
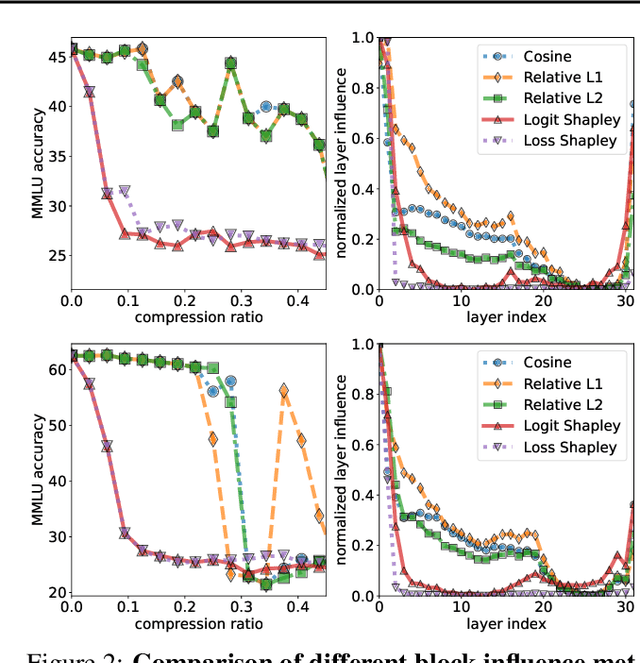
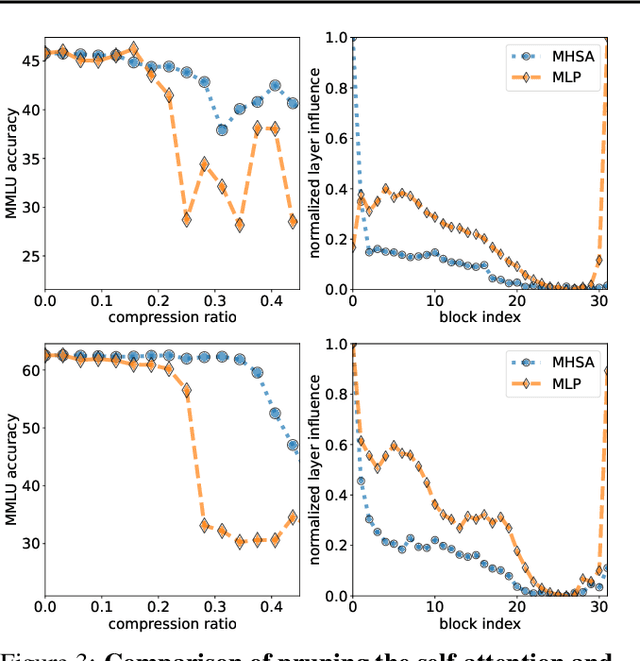

Large Language Models (LLMs) are not only resource-intensive to train but even more costly to deploy in production. Therefore, recent work has attempted to prune blocks of LLMs based on cheap proxies for estimating block importance, effectively removing 10% of blocks in well-trained LLaMa-2 and Mistral 7b models without any significant degradation of downstream metrics. In this paper, we explore different block importance metrics by considering adaptive metrics such as Shapley value in addition to static ones explored in prior work. We show that adaptive metrics exhibit a trade-off in performance between tasks i.e., improvement on one task may degrade performance on the other due to differences in the computed block influences. Furthermore, we extend this analysis from a complete block to individual self-attention and feed-forward layers, highlighting the propensity of the self-attention layers to be more amendable to pruning, even allowing removal of upto 33% of the self-attention layers without incurring any performance degradation on MMLU for Mistral 7b (significant reduction in costly maintenance of KV-cache). Finally, we look at simple performance recovery techniques to emulate the pruned layers by training lightweight additive bias or low-rank linear adapters. Performance recovery using emulated updates avoids performance degradation for the initial blocks (up to 5% absolute improvement on MMLU), which is either competitive or superior to the learning-based technique.
Investigating the Nature of 3D Generalization in Deep Neural Networks
Apr 19, 2023



Visual object recognition systems need to generalize from a set of 2D training views to novel views. The question of how the human visual system can generalize to novel views has been studied and modeled in psychology, computer vision, and neuroscience. Modern deep learning architectures for object recognition generalize well to novel views, but the mechanisms are not well understood. In this paper, we characterize the ability of common deep learning architectures to generalize to novel views. We formulate this as a supervised classification task where labels correspond to unique 3D objects and examples correspond to 2D views of the objects at different 3D orientations. We consider three common models of generalization to novel views: (i) full 3D generalization, (ii) pure 2D matching, and (iii) matching based on a linear combination of views. We find that deep models generalize well to novel views, but they do so in a way that differs from all these existing models. Extrapolation to views beyond the range covered by views in the training set is limited, and extrapolation to novel rotation axes is even more limited, implying that the networks do not infer full 3D structure, nor use linear interpolation. Yet, generalization is far superior to pure 2D matching. These findings help with designing datasets with 2D views required to achieve 3D generalization. Code to reproduce our experiments is publicly available: https://github.com/shoaibahmed/investigating_3d_generalization.git
GroupViT: Semantic Segmentation Emerges from Text Supervision
Feb 22, 2022
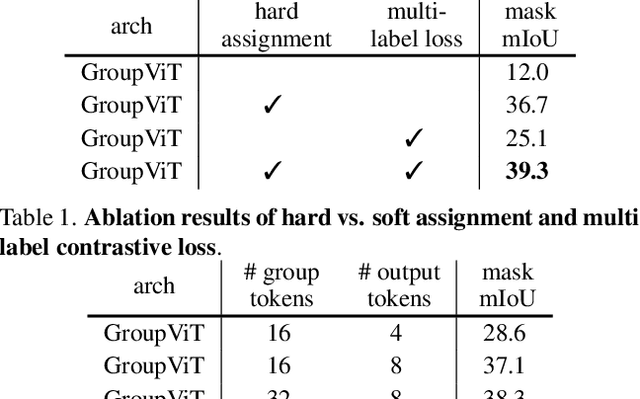

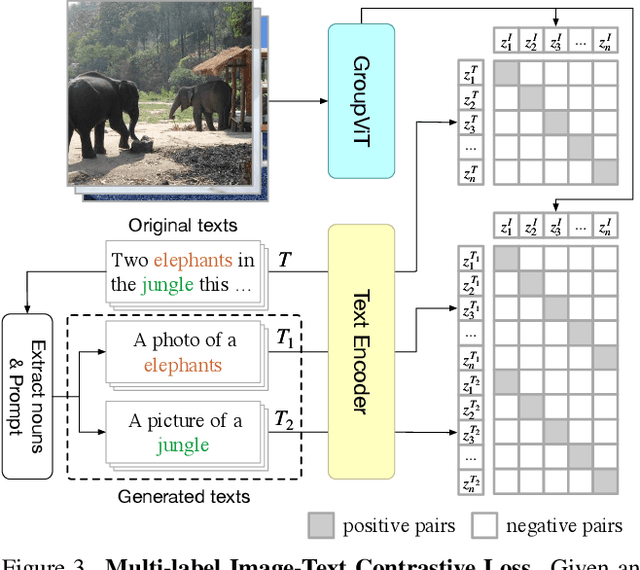
Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 51.2% mIoU on the PASCAL VOC 2012 and 22.3% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision. Project page is available at https://jerryxu.net/GroupViT.
Identifying Layers Susceptible to Adversarial Attacks
Jul 10, 2021
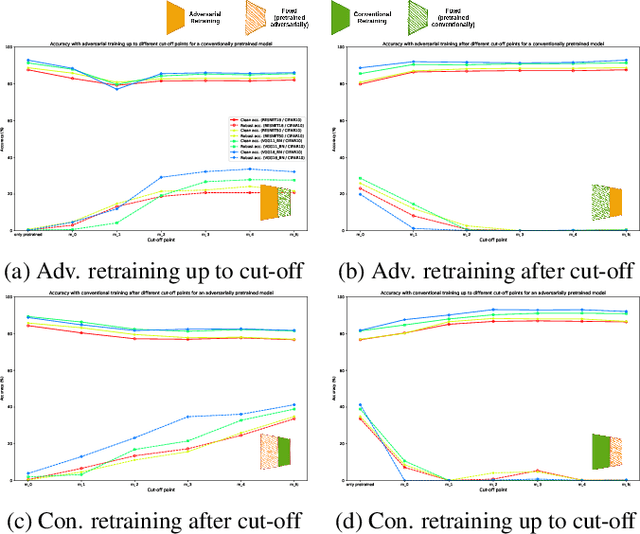


Common neural network architectures are susceptible to attack by adversarial samples. Neural network architectures are commonly thought of as divided into low-level feature extraction layers and high-level classification layers; susceptibility of networks to adversarial samples is often thought of as a problem related to classification rather than feature extraction. We test this idea by selectively retraining different portions of VGG and ResNet architectures on CIFAR-10, Imagenette and ImageNet using non-adversarial and adversarial data. Our experimental results show that susceptibility to adversarial samples is associated with low-level feature extraction layers. Therefore, retraining high-level layers is insufficient for achieving robustness. This phenomenon could have two explanations: either, adversarial attacks yield outputs from early layers that are indistinguishable from features found in the attack classes, or adversarial attacks yield outputs from early layers that differ statistically from features for non-adversarial samples and do not permit consistent classification by subsequent layers. We test this question by large-scale non-linear dimensionality reduction and density modeling on distributions of feature vectors in hidden layers and find that the feature distributions between non-adversarial and adversarial samples differ substantially. Our results provide new insights into the statistical origins of adversarial samples and possible defenses.
Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
Jan 26, 2021


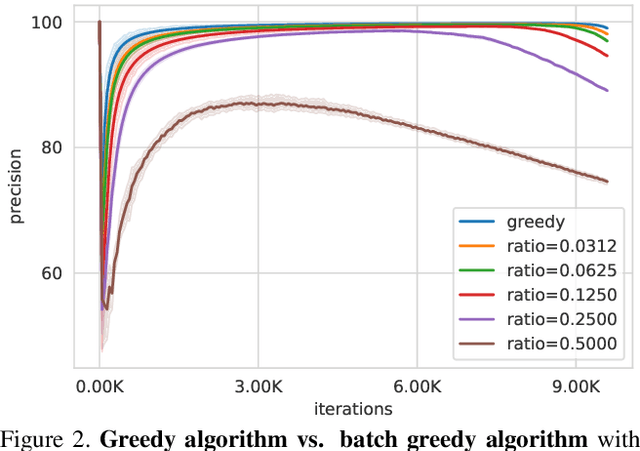
Large-scale datasets are the cornerstone of self-supervised representation learning. Existing algorithms extract learning signals by making certain assumptions about the data, e.g., spatio-temporal continuity and multimodal correspondence. Unfortunately, finding a large amount of data that satisfies such assumptions is sometimes not straightforward. This restricts the community to rely on datasets that require laborious annotation and/or manual filtering processes. In this paper, we describe a subset optimization approach for automatic dataset curation. Focusing on the scenario of audio-visual representation learning, we pose the problem as finding a subset that maximizes the mutual information between audio and visual channels in videos. We demonstrate that our approach finds videos with high audio-visual correspondence and show that self-supervised models trained on our data, despite being automatically constructed, achieve similar downstream performances to existing video datasets with similar scales. The most significant benefit of our approach is scalability. We release the largest video dataset for audio-visual research collected automatically using our approach.
Parameter Efficient Multimodal Transformers for Video Representation Learning
Dec 08, 2020


The recent success of Transformers in the language domain has motivated adapting it to a multimodal setting, where a new visual model is trained in tandem with an already pretrained language model. However, due to the excessive memory requirements from Transformers, existing work typically fixes the language model and train only the vision module, which limits its ability to learn cross-modal information in an end-to-end manner. In this work, we focus on reducing the parameters of multimodal Transformers in the context of audio-visual video representation learning. We alleviate the high memory requirement by sharing the weights of Transformers across layers and modalities; we decompose the Transformer into modality-specific and modality-shared parts so that the model learns the dynamics of each modality both individually and together, and propose a novel parameter sharing scheme based on low-rank approximation. We show that our approach reduces parameters up to 80$\%$, allowing us to train our model end-to-end from scratch. We also propose a negative sampling approach based on an instance similarity measured on the CNN embedding space that our model learns with the Transformers. To demonstrate our approach, we pretrain our model on 30-second clips from Kinetics-700 and transfer it to audio-visual classification tasks.
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020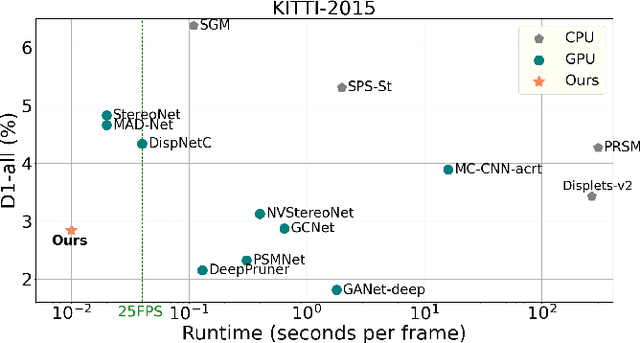

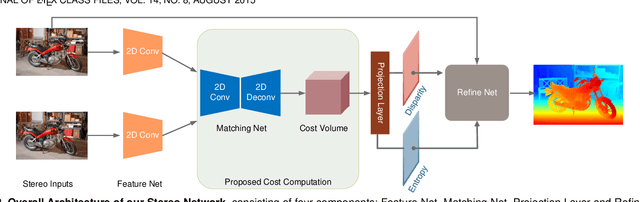
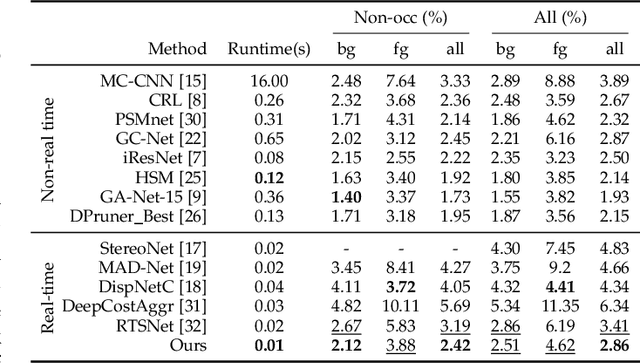
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
Discovering Nonlinear Relations with Minimum Predictive Information Regularization
Jan 07, 2020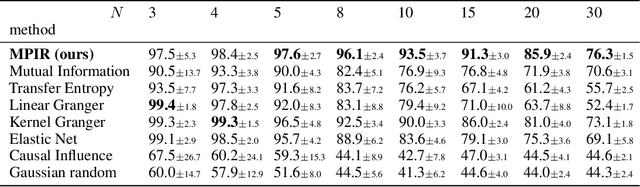
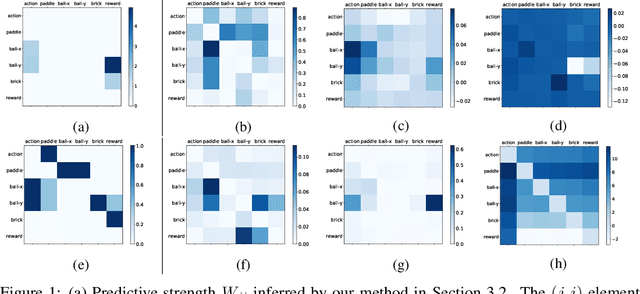
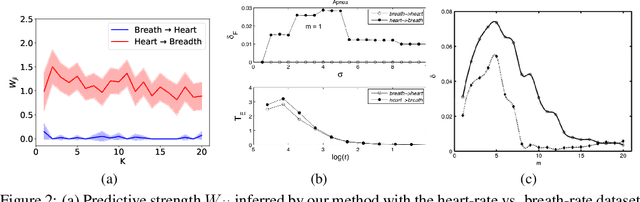
Identifying the underlying directional relations from observational time series with nonlinear interactions and complex relational structures is key to a wide range of applications, yet remains a hard problem. In this work, we introduce a novel minimum predictive information regularization method to infer directional relations from time series, allowing deep learning models to discover nonlinear relations. Our method substantially outperforms other methods for learning nonlinear relations in synthetic datasets, and discovers the directional relations in a video game environment and a heart-rate vs. breath-rate dataset.
Unsupervised Image-to-Image Translation Networks
Jul 23, 2018



Unsupervised image-to-image translation aims at learning a joint distribution of images in different domains by using images from the marginal distributions in individual domains. Since there exists an infinite set of joint distributions that can arrive the given marginal distributions, one could infer nothing about the joint distribution from the marginal distributions without additional assumptions. To address the problem, we make a shared-latent space assumption and propose an unsupervised image-to-image translation framework based on Coupled GANs. We compare the proposed framework with competing approaches and present high quality image translation results on various challenging unsupervised image translation tasks, including street scene image translation, animal image translation, and face image translation. We also apply the proposed framework to domain adaptation and achieve state-of-the-art performance on benchmark datasets. Code and additional results are available in https://github.com/mingyuliutw/unit .
IamNN: Iterative and Adaptive Mobile Neural Network for Efficient Image Classification
Apr 26, 2018


Deep residual networks (ResNets) made a recent breakthrough in deep learning. The core idea of ResNets is to have shortcut connections between layers that allow the network to be much deeper while still being easy to optimize avoiding vanishing gradients. These shortcut connections have interesting side-effects that make ResNets behave differently from other typical network architectures. In this work we use these properties to design a network based on a ResNet but with parameter sharing and with adaptive computation time. The resulting network is much smaller than the original network and can adapt the computational cost to the complexity of the input image.