 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of the BraTS 2023 Intracranial Meningioma Segmentation Challenge
May 16, 2024



We describe the design and results from the BraTS 2023 Intracranial Meningioma Segmentation Challenge. The BraTS Meningioma Challenge differed from prior BraTS Glioma challenges in that it focused on meningiomas, which are typically benign extra-axial tumors with diverse radiologic and anatomical presentation and a propensity for multiplicity. Nine participating teams each developed deep-learning automated segmentation models using image data from the largest multi-institutional systematically expert annotated multilabel multi-sequence meningioma MRI dataset to date, which included 1000 training set cases, 141 validation set cases, and 283 hidden test set cases. Each case included T2, T2/FLAIR, T1, and T1Gd brain MRI sequences with associated tumor compartment labels delineating enhancing tumor, non-enhancing tumor, and surrounding non-enhancing T2/FLAIR hyperintensity. Participant automated segmentation models were evaluated and ranked based on a scoring system evaluating lesion-wise metrics including dice similarity coefficient (DSC) and 95% Hausdorff Distance. The top ranked team had a lesion-wise median dice similarity coefficient (DSC) of 0.976, 0.976, and 0.964 for enhancing tumor, tumor core, and whole tumor, respectively and a corresponding average DSC of 0.899, 0.904, and 0.871, respectively. These results serve as state-of-the-art benchmarks for future pre-operative meningioma automated segmentation algorithms. Additionally, we found that 1286 of 1424 cases (90.3%) had at least 1 compartment voxel abutting the edge of the skull-stripped image edge, which requires further investigation into optimal pre-processing face anonymization steps.
M&M: Tackling False Positives in Mammography with a Multi-view and Multi-instance Learning Sparse Detector
Aug 11, 2023Deep-learning-based object detection methods show promise for improving screening mammography, but high rates of false positives can hinder their effectiveness in clinical practice. To reduce false positives, we identify three challenges: (1) unlike natural images, a malignant mammogram typically contains only one malignant finding; (2) mammography exams contain two views of each breast, and both views ought to be considered to make a correct assessment; (3) most mammograms are negative and do not contain any findings. In this work, we tackle the three aforementioned challenges by: (1) leveraging Sparse R-CNN and showing that sparse detectors are more appropriate than dense detectors for mammography; (2) including a multi-view cross-attention module to synthesize information from different views; (3) incorporating multi-instance learning (MIL) to train with unannotated images and perform breast-level classification. The resulting model, M&M, is a Multi-view and Multi-instance learning system that can both localize malignant findings and provide breast-level predictions. We validate M&M's detection and classification performance using five mammography datasets. In addition, we demonstrate the effectiveness of each proposed component through comprehensive ablation studies.
Problems and shortcuts in deep learning for screening mammography
Mar 29, 2023This work reveals undiscovered challenges in the performance and generalizability of deep learning models. We (1) identify spurious shortcuts and evaluation issues that can inflate performance and (2) propose training and analysis methods to address them. We trained an AI model to classify cancer on a retrospective dataset of 120,112 US exams (3,467 cancers) acquired from 2008 to 2017 and 16,693 UK exams (5,655 cancers) acquired from 2011 to 2015. We evaluated on a screening mammography test set of 11,593 US exams (102 cancers; 7,594 women; age 57.1 \pm 11.0) and 1,880 UK exams (590 cancers; 1,745 women; age 63.3 \pm 7.2). A model trained on images of only view markers (no breast) achieved a 0.691 AUC. The original model trained on both datasets achieved a 0.945 AUC on the combined US+UK dataset but paradoxically only 0.838 and 0.892 on the US and UK datasets, respectively. Sampling cancers equally from both datasets during training mitigated this shortcut. A similar AUC paradox (0.903) occurred when evaluating diagnostic exams vs screening exams (0.862 vs 0.861, respectively). Removing diagnostic exams during training alleviated this bias. Finally, the model did not exhibit the AUC paradox over scanner models but still exhibited a bias toward Selenia Dimension (SD) over Hologic Selenia (HS) exams. Analysis showed that this AUC paradox occurred when a dataset attribute had values with a higher cancer prevalence (dataset bias) and the model consequently assigned a higher probability to these attribute values (model bias). Stratification and balancing cancer prevalence can mitigate shortcuts during evaluation. Dataset and model bias can introduce shortcuts and the AUC paradox, potentially pervasive issues within the healthcare AI space. Our methods can verify and mitigate shortcuts while providing a clear understanding of performance.
Deep is a Luxury We Don't Have
Aug 11, 2022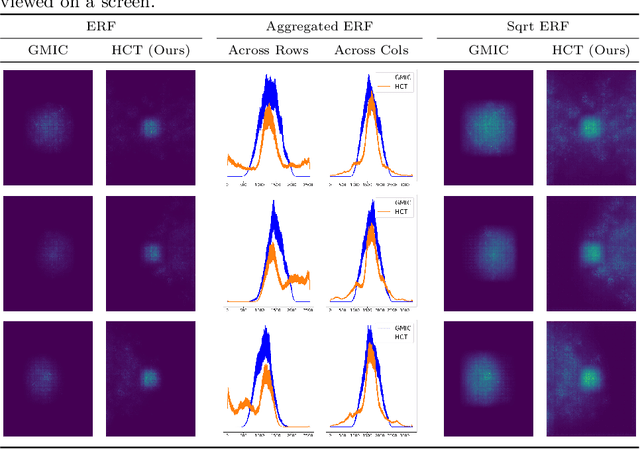
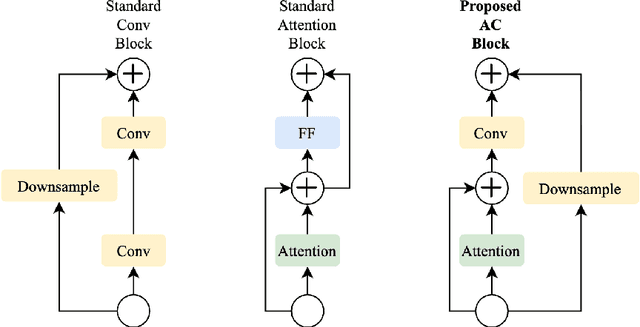
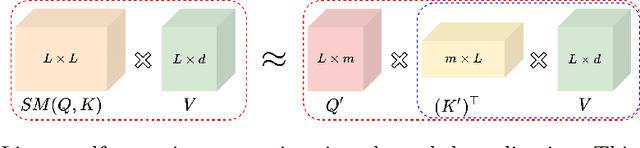

Medical images come in high resolutions. A high resolution is vital for finding malignant tissues at an early stage. Yet, this resolution presents a challenge in terms of modeling long range dependencies. Shallow transformers eliminate this problem, but they suffer from quadratic complexity. In this paper, we tackle this complexity by leveraging a linear self-attention approximation. Through this approximation, we propose an efficient vision model called HCT that stands for High resolution Convolutional Transformer. HCT brings transformers' merits to high resolution images at a significantly lower cost. We evaluate HCT using a high resolution mammography dataset. HCT is significantly superior to its CNN counterpart. Furthermore, we demonstrate HCT's fitness for medical images by evaluating its effective receptive field.Code available at https://bit.ly/3ykBhhf
Knowledge Evolution in Neural Networks
Mar 09, 2021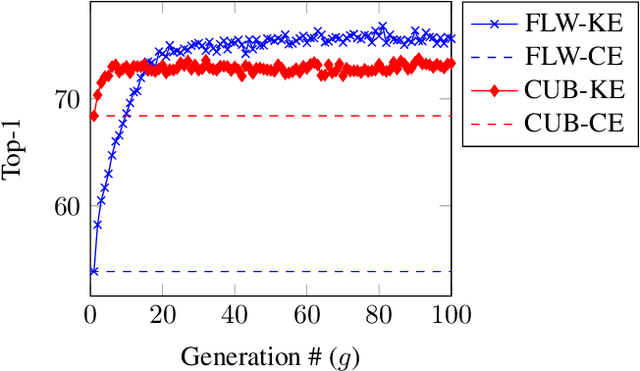
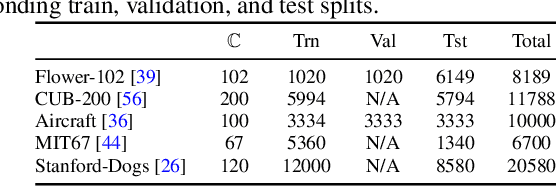
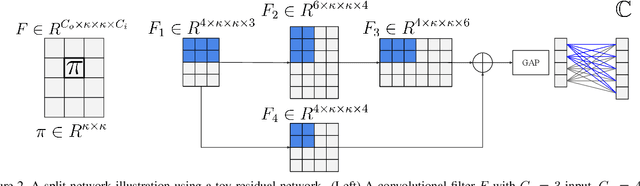
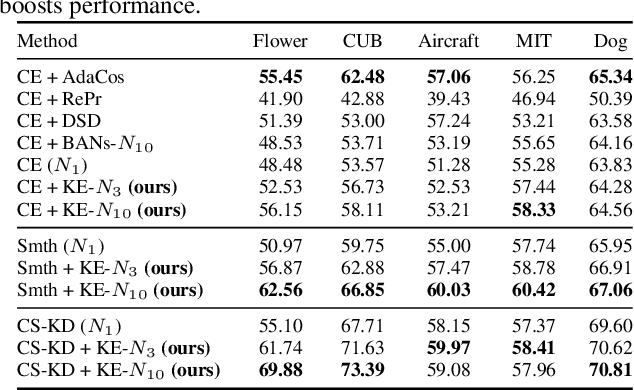
Deep learning relies on the availability of a large corpus of data (labeled or unlabeled). Thus, one challenging unsettled question is: how to train a deep network on a relatively small dataset? To tackle this question, we propose an evolution-inspired training approach to boost performance on relatively small datasets. The knowledge evolution (KE) approach splits a deep network into two hypotheses: the fit-hypothesis and the reset-hypothesis. We iteratively evolve the knowledge inside the fit-hypothesis by perturbing the reset-hypothesis for multiple generations. This approach not only boosts performance, but also learns a slim network with a smaller inference cost. KE integrates seamlessly with both vanilla and residual convolutional networks. KE reduces both overfitting and the burden for data collection. We evaluate KE on various network architectures and loss functions. We evaluate KE using relatively small datasets (e.g., CUB-200) and randomly initialized deep networks. KE achieves an absolute 21% improvement margin on a state-of-the-art baseline. This performance improvement is accompanied by a relative 73% reduction in inference cost. KE achieves state-of-the-art results on classification and metric learning benchmarks. Code available at http://bit.ly/3uLgwYb
SVMax: A Feature Embedding Regularizer
Mar 04, 2021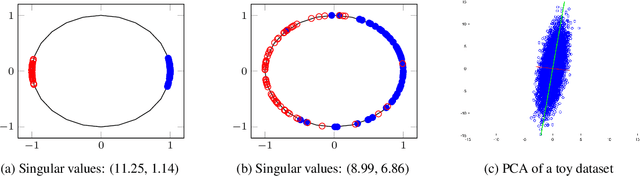
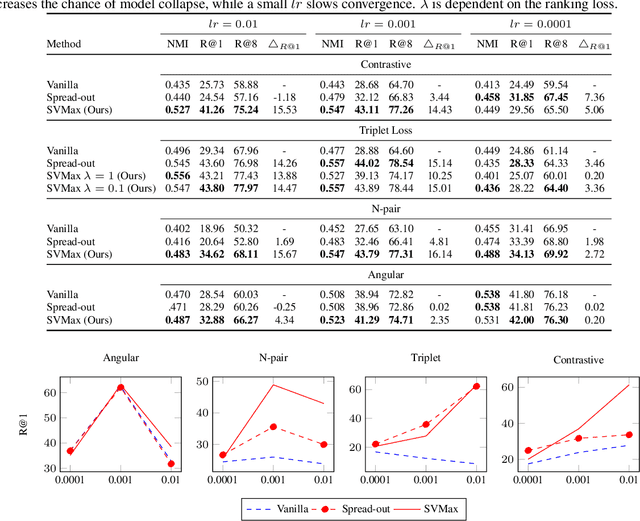
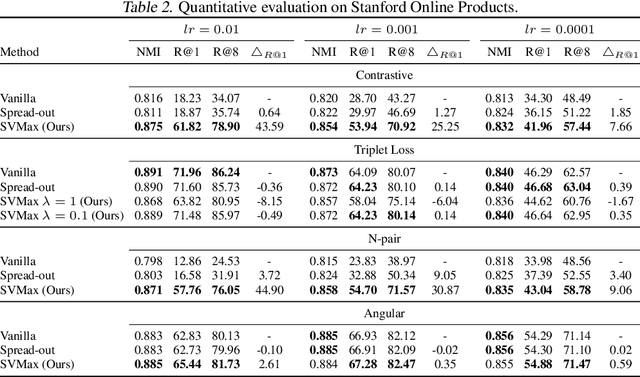
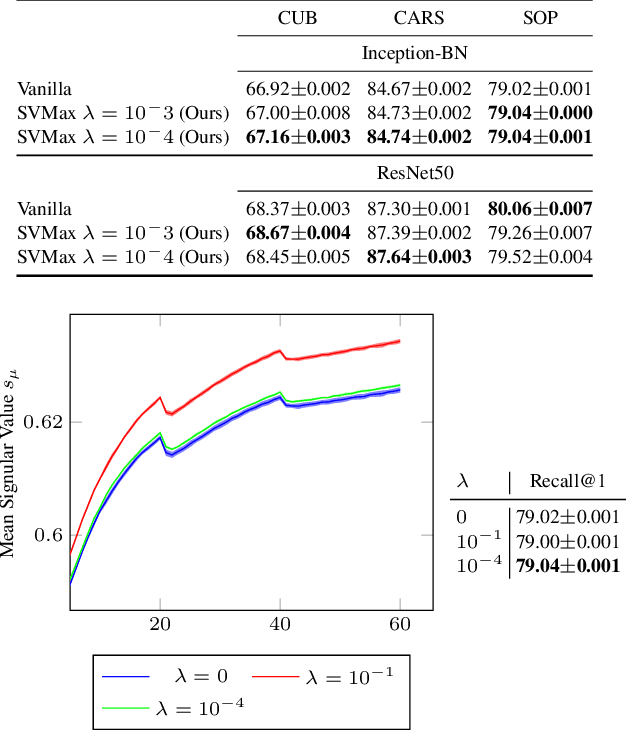
A neural network regularizer (e.g., weight decay) boosts performance by explicitly penalizing the complexity of a network. In this paper, we penalize inferior network activations -- feature embeddings -- which in turn regularize the network's weights implicitly. We propose singular value maximization (SVMax) to learn a more uniform feature embedding. The SVMax regularizer supports both supervised and unsupervised learning. Our formulation mitigates model collapse and enables larger learning rates. We evaluate the SVMax regularizer using both retrieval and generative adversarial networks. We leverage a synthetic mixture of Gaussians dataset to evaluate SVMax in an unsupervised setting. For retrieval networks, SVMax achieves significant improvement margins across various ranking losses. Code available at https://bit.ly/3jNkgDt
A Generic Visualization Approach for Convolutional Neural Networks
Jul 19, 2020
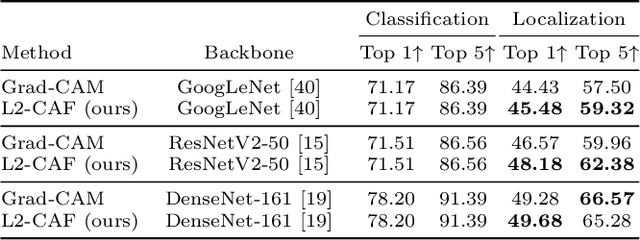

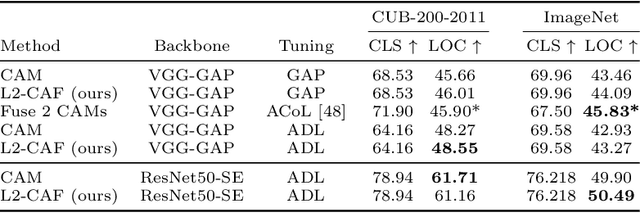
Retrieval networks are essential for searching and indexing. Compared to classification networks, attention visualization for retrieval networks is hardly studied. We formulate attention visualization as a constrained optimization problem. We leverage the unit L2-Norm constraint as an attention filter (L2-CAF) to localize attention in both classification and retrieval networks. Unlike recent literature, our approach requires neither architectural changes nor fine-tuning. Thus, a pre-trained network's performance is never undermined L2-CAF is quantitatively evaluated using weakly supervised object localization. State-of-the-art results are achieved on classification networks. For retrieval networks, significant improvement margins are achieved over a Grad-CAM baseline. Qualitative evaluation demonstrates how the L2-CAF visualizes attention per frame for a recurrent retrieval network. Further ablation studies highlight the computational cost of our approach and compare L2-CAF with other feasible alternatives. Code available at https://bit.ly/3iDBLFv
Unsupervised Data Uncertainty Learning in Visual Retrieval Systems
Feb 07, 2019
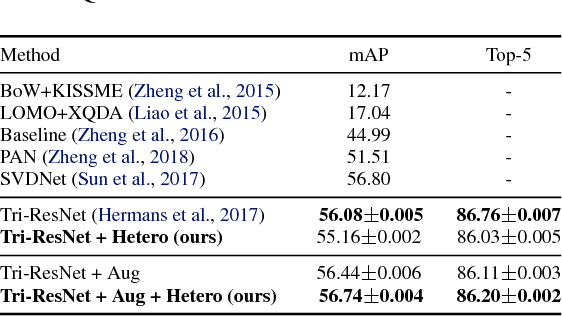

We introduce an unsupervised formulation to estimate heteroscedastic uncertainty in retrieval systems. We propose an extension to triplet loss that models data uncertainty for each input. Besides improving performance, our formulation models local noise in the embedding space. It quantifies input uncertainty and thus enhances interpretability of the system. This helps identify noisy observations in query and search databases. Evaluation on both image and video retrieval applications highlight the utility of our approach. We highlight our efficiency in modeling local noise using two real-world datasets: Clothing1M and Honda Driving datasets. Qualitative results illustrate our ability in identifying confusing scenarios in various domains. Uncertainty learning also enables data cleaning by detecting noisy training labels.
In Defense of the Triplet Loss for Visual Recognition
Jan 24, 2019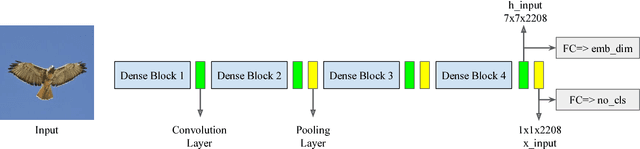

We employ triplet loss as a space embedding regularizer to boost classification performance. Standard architectures, like ResNet and DesneNet, are extended to support both losses with minimal hyper-parameter tuning. This promotes generality while fine-tuning pretrained networks. Triplet loss is a powerful surrogate for recently proposed embedding regularizers. Yet, it is avoided for large batch-size requirement and high computational cost. Through our experiments, we re-assess these assumptions. During inference, our network supports both classification and embedding tasks without any computational overhead. Quantitative evaluation highlights how our approach compares favorably to the existing state of the art on multiple fine-grained recognition datasets. Further evaluation on an imbalanced video dataset achieves significant improvement (>7%). Beyond boosting efficiency, triplet loss brings retrieval and interpretability to classification models.
Exploring Uncertainty in Conditional Multi-Modal Retrieval Systems
Jan 23, 2019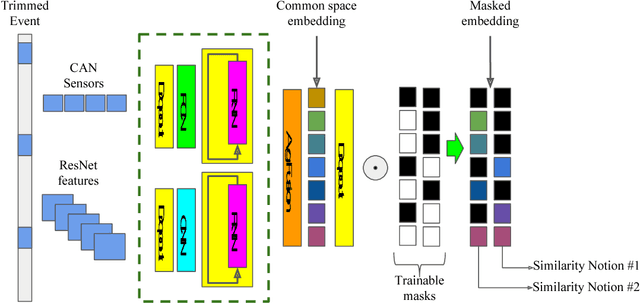
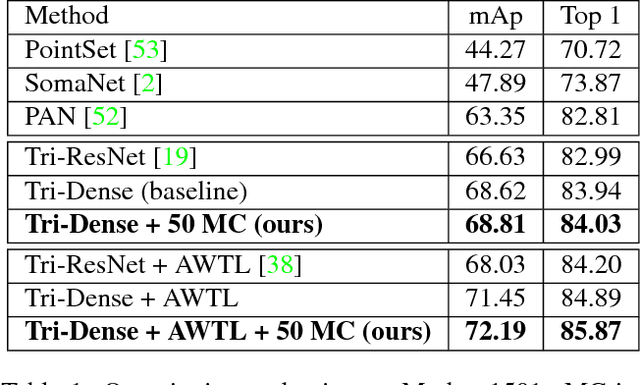
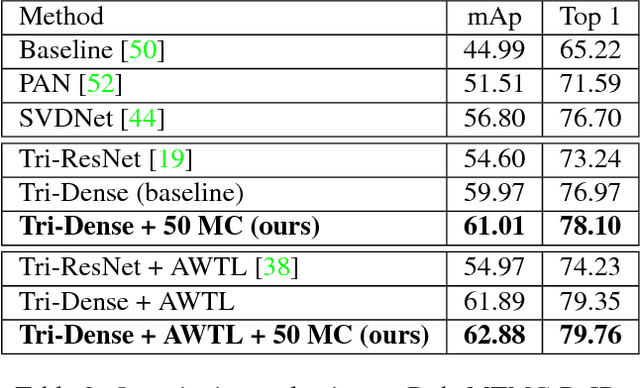
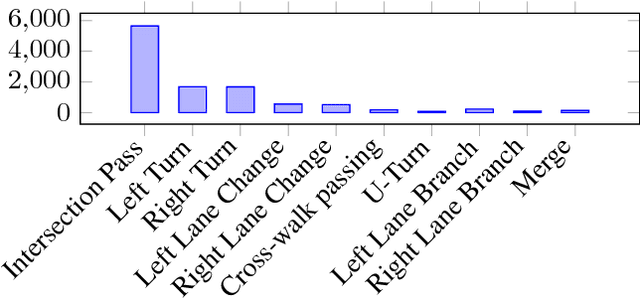
We cast visual retrieval as a regression problem by posing triplet loss as a regression loss. This enables epistemic uncertainty estimation using dropout as a Bayesian approximation framework in retrieval. Accordingly, Monte Carlo (MC) sampling is leveraged to boost retrieval performance. Our approach is evaluated on two applications: person re-identification and autonomous car driving. Comparable state-of-the-art results are achieved on multiple datasets for the former application. We leverage the Honda driving dataset (HDD) for autonomous car driving application. It provides multiple modalities and similarity notions for ego-motion action understanding. Hence, we present a multi-modal conditional retrieval network. It disentangles embeddings into separate representations to encode different similarities. This form of joint learning eliminates the need to train multiple independent networks without any performance degradation. Quantitative evaluation highlights our approach competence, achieving 6% improvement in a highly uncertain environment.