 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom 2D to 3D Without Extra Baggage: Data-Efficient Cancer Detection in Digital Breast Tomosynthesis
Nov 13, 2025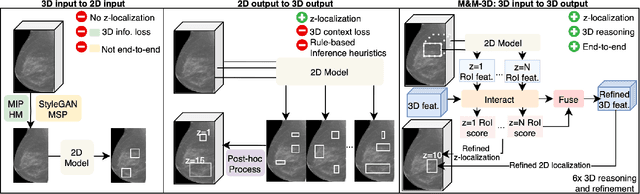
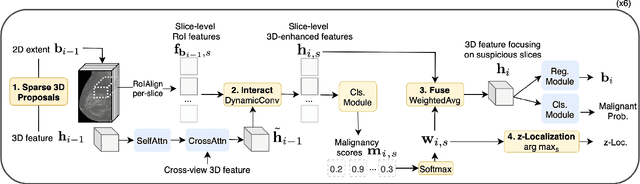
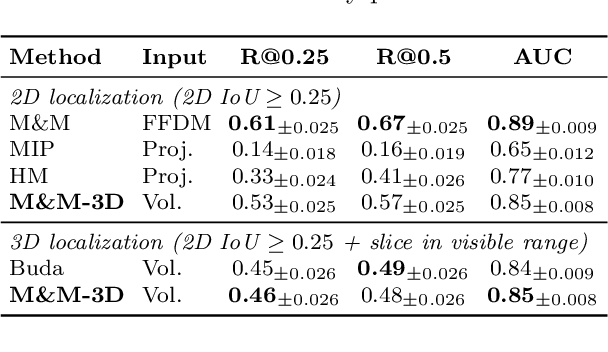
Digital Breast Tomosynthesis (DBT) enhances finding visibility for breast cancer detection by providing volumetric information that reduces the impact of overlapping tissues; however, limited annotated data has constrained the development of deep learning models for DBT. To address data scarcity, existing methods attempt to reuse 2D full-field digital mammography (FFDM) models by either flattening DBT volumes or processing slices individually, thus discarding volumetric information. Alternatively, 3D reasoning approaches introduce complex architectures that require more DBT training data. Tackling these drawbacks, we propose M&M-3D, an architecture that enables learnable 3D reasoning while remaining parameter-free relative to its FFDM counterpart, M&M. M&M-3D constructs malignancy-guided 3D features, and 3D reasoning is learned through repeatedly mixing these 3D features with slice-level information. This is achieved by modifying operations in M&M without adding parameters, thus enabling direct weight transfer from FFDM. Extensive experiments show that M&M-3D surpasses 2D projection and 3D slice-based methods by 11-54% for localization and 3-10% for classification. Additionally, M&M-3D outperforms complex 3D reasoning variants by 20-47% for localization and 2-10% for classification in the low-data regime, while matching their performance in high-data regime. On the popular BCS-DBT benchmark, M&M-3D outperforms previous top baseline by 4% for classification and 10% for localization.
M&M: Tackling False Positives in Mammography with a Multi-view and Multi-instance Learning Sparse Detector
Aug 11, 2023Deep-learning-based object detection methods show promise for improving screening mammography, but high rates of false positives can hinder their effectiveness in clinical practice. To reduce false positives, we identify three challenges: (1) unlike natural images, a malignant mammogram typically contains only one malignant finding; (2) mammography exams contain two views of each breast, and both views ought to be considered to make a correct assessment; (3) most mammograms are negative and do not contain any findings. In this work, we tackle the three aforementioned challenges by: (1) leveraging Sparse R-CNN and showing that sparse detectors are more appropriate than dense detectors for mammography; (2) including a multi-view cross-attention module to synthesize information from different views; (3) incorporating multi-instance learning (MIL) to train with unannotated images and perform breast-level classification. The resulting model, M&M, is a Multi-view and Multi-instance learning system that can both localize malignant findings and provide breast-level predictions. We validate M&M's detection and classification performance using five mammography datasets. In addition, we demonstrate the effectiveness of each proposed component through comprehensive ablation studies.
Problems and shortcuts in deep learning for screening mammography
Mar 29, 2023This work reveals undiscovered challenges in the performance and generalizability of deep learning models. We (1) identify spurious shortcuts and evaluation issues that can inflate performance and (2) propose training and analysis methods to address them. We trained an AI model to classify cancer on a retrospective dataset of 120,112 US exams (3,467 cancers) acquired from 2008 to 2017 and 16,693 UK exams (5,655 cancers) acquired from 2011 to 2015. We evaluated on a screening mammography test set of 11,593 US exams (102 cancers; 7,594 women; age 57.1 \pm 11.0) and 1,880 UK exams (590 cancers; 1,745 women; age 63.3 \pm 7.2). A model trained on images of only view markers (no breast) achieved a 0.691 AUC. The original model trained on both datasets achieved a 0.945 AUC on the combined US+UK dataset but paradoxically only 0.838 and 0.892 on the US and UK datasets, respectively. Sampling cancers equally from both datasets during training mitigated this shortcut. A similar AUC paradox (0.903) occurred when evaluating diagnostic exams vs screening exams (0.862 vs 0.861, respectively). Removing diagnostic exams during training alleviated this bias. Finally, the model did not exhibit the AUC paradox over scanner models but still exhibited a bias toward Selenia Dimension (SD) over Hologic Selenia (HS) exams. Analysis showed that this AUC paradox occurred when a dataset attribute had values with a higher cancer prevalence (dataset bias) and the model consequently assigned a higher probability to these attribute values (model bias). Stratification and balancing cancer prevalence can mitigate shortcuts during evaluation. Dataset and model bias can introduce shortcuts and the AUC paradox, potentially pervasive issues within the healthcare AI space. Our methods can verify and mitigate shortcuts while providing a clear understanding of performance.
Deep is a Luxury We Don't Have
Aug 11, 2022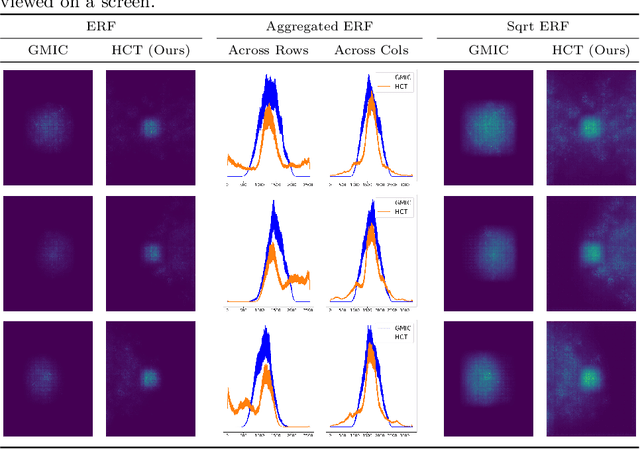
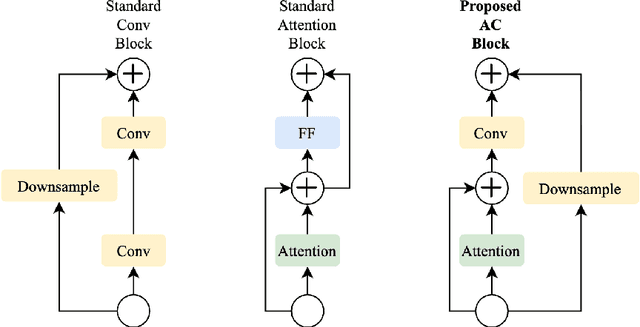
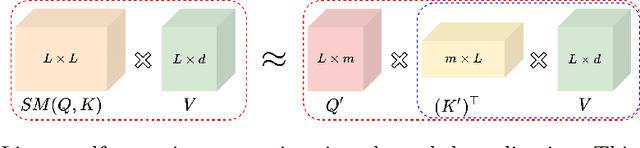

Medical images come in high resolutions. A high resolution is vital for finding malignant tissues at an early stage. Yet, this resolution presents a challenge in terms of modeling long range dependencies. Shallow transformers eliminate this problem, but they suffer from quadratic complexity. In this paper, we tackle this complexity by leveraging a linear self-attention approximation. Through this approximation, we propose an efficient vision model called HCT that stands for High resolution Convolutional Transformer. HCT brings transformers' merits to high resolution images at a significantly lower cost. We evaluate HCT using a high resolution mammography dataset. HCT is significantly superior to its CNN counterpart. Furthermore, we demonstrate HCT's fitness for medical images by evaluating its effective receptive field.Code available at https://bit.ly/3ykBhhf
A Hypersensitive Breast Cancer Detector
Jan 23, 2020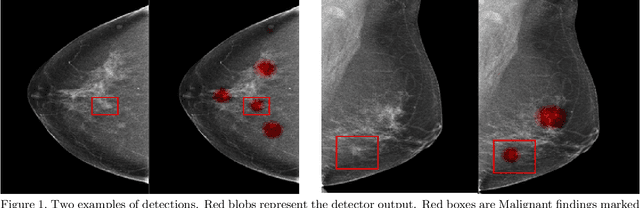
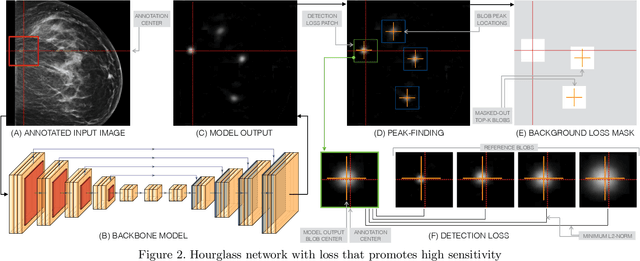
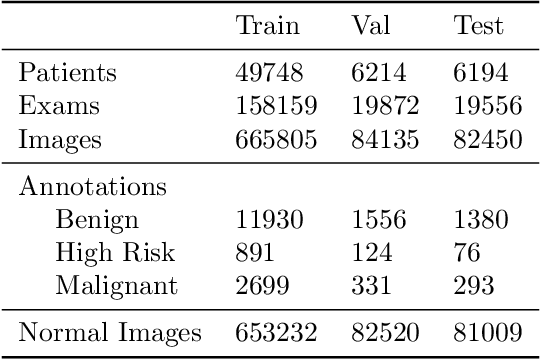
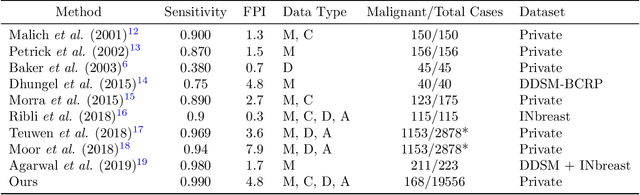
Early detection of breast cancer through screening mammography yields a 20-35% increase in survival rate; however, there are not enough radiologists to serve the growing population of women seeking screening mammography. Although commercial computer aided detection (CADe) software has been available to radiologists for decades, it has failed to improve the interpretation of full-field digital mammography (FFDM) images due to its low sensitivity over the spectrum of findings. In this work, we leverage a large set of FFDM images with loose bounding boxes of mammographically significant findings to train a deep learning detector with extreme sensitivity. Building upon work from the Hourglass architecture, we train a model that produces segmentation-like images with high spatial resolution, with the aim of producing 2D Gaussian blobs centered on ground-truth boxes. We replace the pixel-wise $L_2$ norm with a weak-supervision loss designed to achieve high sensitivity, asymmetrically penalizing false positives and false negatives while softening the noise of the loose bounding boxes by permitting a tolerance in misaligned predictions. The resulting system achieves a sensitivity for malignant findings of 0.99 with only 4.8 false positive markers per image. When utilized in a CADe system, this model could enable a novel workflow where radiologists can focus their attention with trust on only the locations proposed by the model, expediting the interpretation process and bringing attention to potential findings that could otherwise have been missed. Due to its nearly perfect sensitivity, the proposed detector can also be used as a high-performance proposal generator in two-stage detection systems.
Adaptation of a deep learning malignancy model from full-field digital mammography to digital breast tomosynthesis
Jan 23, 2020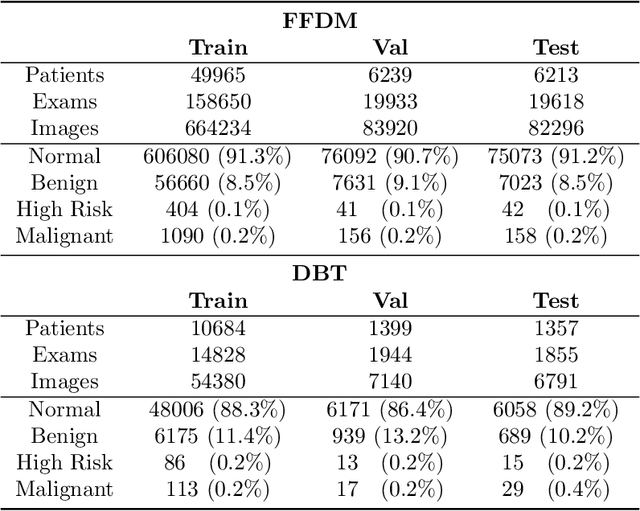
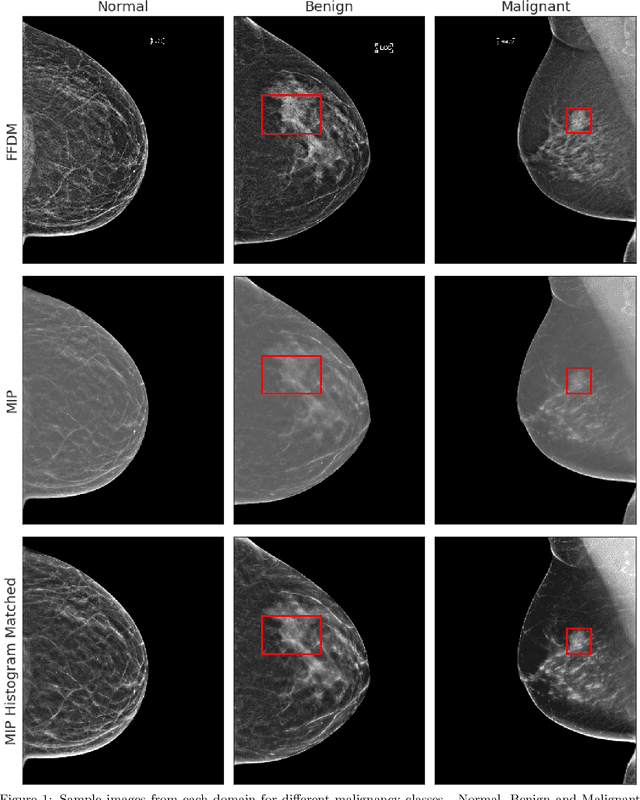
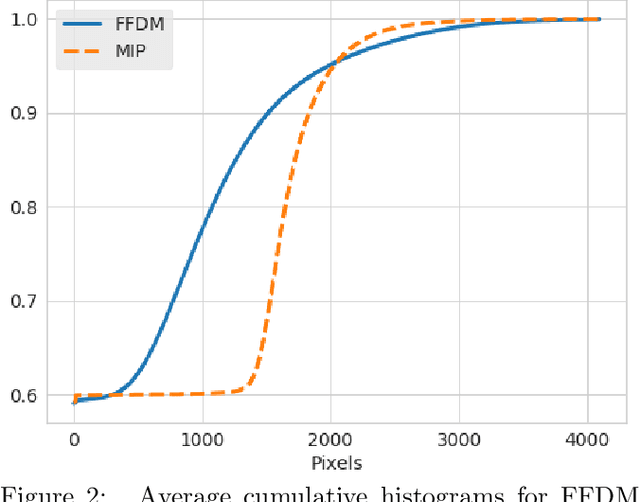

Mammography-based screening has helped reduce the breast cancer mortality rate, but has also been associated with potential harms due to low specificity, leading to unnecessary exams or procedures, and low sensitivity. Digital breast tomosynthesis (DBT) improves on conventional mammography by increasing both sensitivity and specificity and is becoming common in clinical settings. However, deep learning (DL) models have been developed mainly on conventional 2D full-field digital mammography (FFDM) or scanned film images. Due to a lack of large annotated DBT datasets, it is difficult to train a model on DBT from scratch. In this work, we present methods to generalize a model trained on FFDM images to DBT images. In particular, we use average histogram matching (HM) and DL fine-tuning methods to generalize a FFDM model to the 2D maximum intensity projection (MIP) of DBT images. In the proposed approach, the differences between the FFDM and DBT domains are reduced via HM and then the base model, which was trained on abundant FFDM images, is fine-tuned. When evaluating on image patches extracted around identified findings, we are able to achieve similar areas under the receiver operating characteristic curve (ROC AUC) of $\sim 0.9$ for FFDM and $\sim 0.85$ for MIP images, as compared to a ROC AUC of $\sim 0.75$ when tested directly on MIP images.