 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Conversational Medical AI with Eyes, Ears and a Voice
May 10, 2026The practice of medicine relies not only upon skillful dialogue but also on the nuanced exchange and interpretation of rich auditory and visual cues between doctors and patients. Building on the low-latency voice and video processing capabilities of Gemini, we introduce AI co-clinician, a first-of-its-kind conversational AI system utilizing continuous streams of audio-visual data from live patient conversations to inform real-time clinical decisions. Its dual-agent architecture balances deep clinical reasoning with the low latency required for natural dialogue. To assess this system, we implemented a video-based interface emulating telemedicine consultations. We crafted 20 standardized outpatient scenarios requiring proactive real-time auditory and visual reasoning and designed "TelePACES" evaluation criteria alongside case-specific rubrics. In a randomized, interface-blinded, crossover simulation study (n = 120 encounters) with 10 internal medicine residents as patient actors, we compared AI co-clinician with primary care physicians (PCPs), GPT-Realtime, and a baseline agent. AI co-clinician approached PCPs in key TelePACES dimensions, including management plans and differential diagnosis, while significantly outperforming GPT-Realtime across all general criteria. While our agent demonstrated parity with PCPs in case-specific triage measures, physicians maintained superior overall performance in case-specific assessments. Although AI co-clinician marks a significant advance in real-time telemedical AI, gaps remain in physical examination and disease-specific reasoning. Our work shows that text-only approaches fail to capture the true challenges of medical consultation and suggests that high-stakes real-time diagnostic AI is most safely advanced in collaborative, triadic models where AI can be a supportive co-clinician for doctors and patients.
A deep learning algorithm for reducing false positives in screening mammography
Apr 13, 2022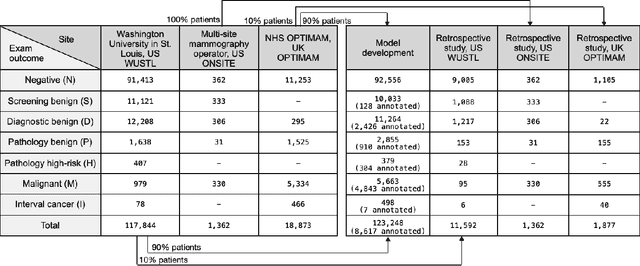
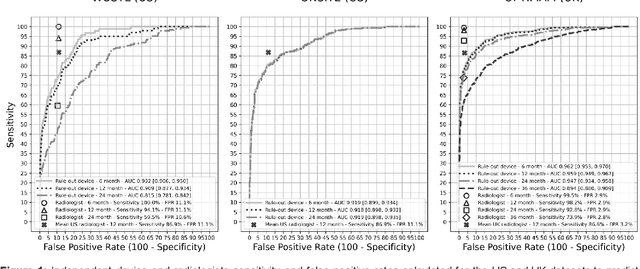
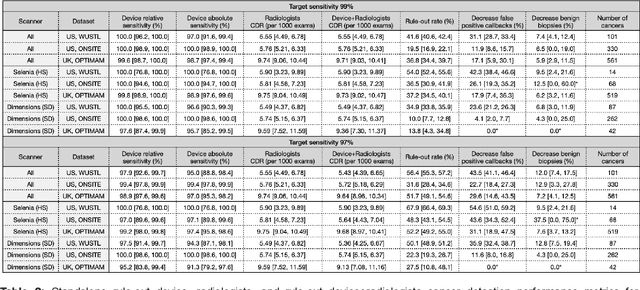
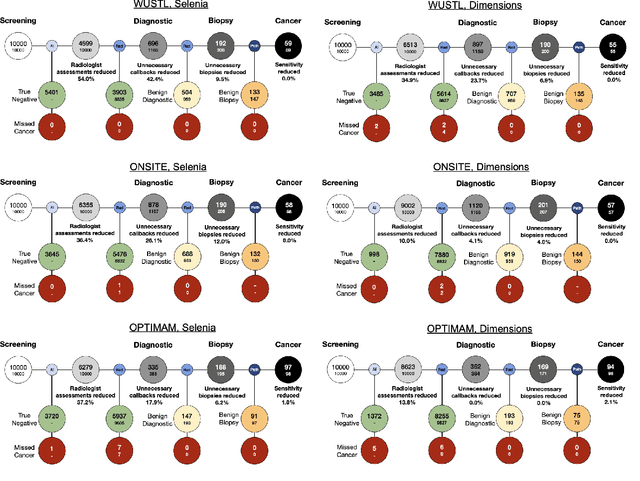
Screening mammography improves breast cancer outcomes by enabling early detection and treatment. However, false positive callbacks for additional imaging from screening exams cause unnecessary procedures, patient anxiety, and financial burden. This work demonstrates an AI algorithm that reduces false positives by identifying mammograms not suspicious for breast cancer. We trained the algorithm to determine the absence of cancer using 123,248 2D digital mammograms (6,161 cancers) and performed a retrospective study on 14,831 screening exams (1,026 cancers) from 15 US and 3 UK sites. Retrospective evaluation of the algorithm on the largest of the US sites (11,592 mammograms, 101 cancers) a) left the cancer detection rate unaffected (p=0.02, non-inferiority margin 0.25 cancers per 1000 exams), b) reduced callbacks for diagnostic exams by 31.1% compared to standard clinical readings, c) reduced benign needle biopsies by 7.4%, and d) reduced screening exams requiring radiologist interpretation by 41.6% in the simulated clinical workflow. This work lays the foundation for semi-autonomous breast cancer screening systems that could benefit patients and healthcare systems by reducing false positives, unnecessary procedures, patient anxiety, and expenses.
LiRaNet: End-to-End Trajectory Prediction using Spatio-Temporal Radar Fusion
Oct 15, 2020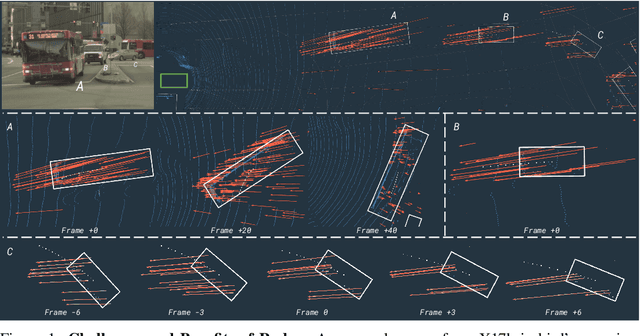
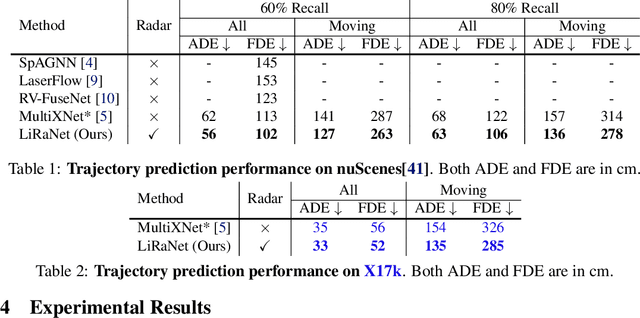
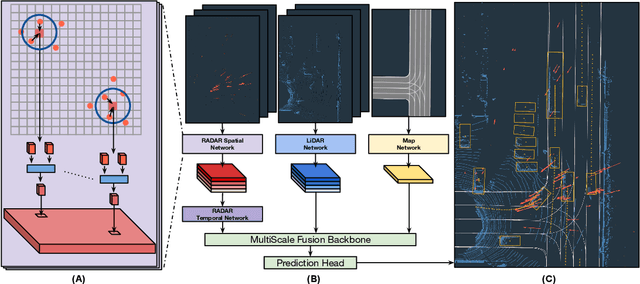

In this paper, we present LiRaNet, a novel end-to-end trajectory prediction method which utilizes radar sensor information along with widely used lidar and high definition (HD) maps. Automotive radar provides rich, complementary information, allowing for longer range vehicle detection as well as instantaneous radial velocity measurements. However, there are factors that make the fusion of lidar and radar information challenging, such as the relatively low angular resolution of radar measurements, their sparsity and the lack of exact time synchronization with lidar. To overcome these challenges, we propose an efficient spatio-temporal radar feature extraction scheme which achieves state-of-the-art performance on multiple large-scale datasets.Further, by incorporating radar information, we show a 52% reduction in prediction error for objects with high acceleration and a 16% reduction in prediction error for objects at longer range.
Conditional Entropy Coding for Efficient Video Compression
Aug 20, 2020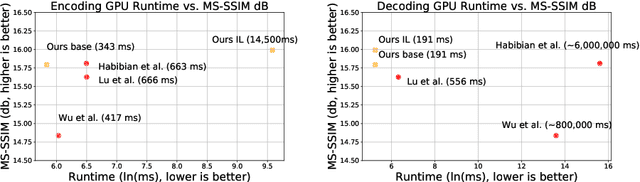
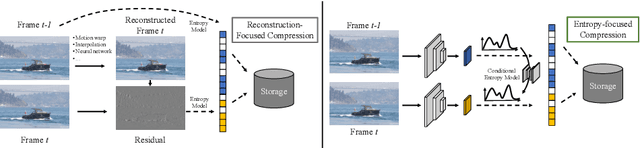
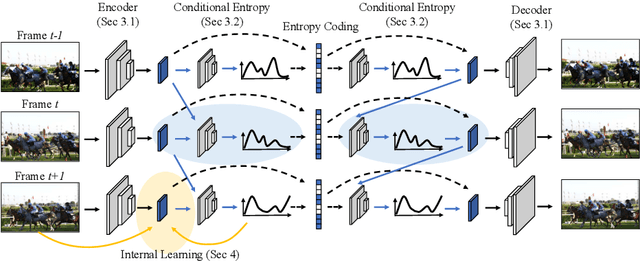
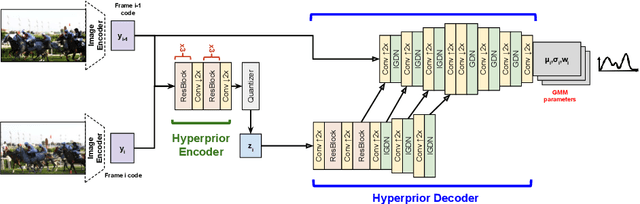
We propose a very simple and efficient video compression framework that only focuses on modeling the conditional entropy between frames. Unlike prior learning-based approaches, we reduce complexity by not performing any form of explicit transformations between frames and assume each frame is encoded with an independent state-of-the-art deep image compressor. We first show that a simple architecture modeling the entropy between the image latent codes is as competitive as other neural video compression works and video codecs while being much faster and easier to implement. We then propose a novel internal learning extension on top of this architecture that brings an additional 10% bitrate savings without trading off decoding speed. Importantly, we show that our approach outperforms H.265 and other deep learning baselines in MS-SSIM on higher bitrate UVG video, and against all video codecs on lower framerates, while being thousands of times faster in decoding than deep models utilizing an autoregressive entropy model.
A Hypersensitive Breast Cancer Detector
Jan 23, 2020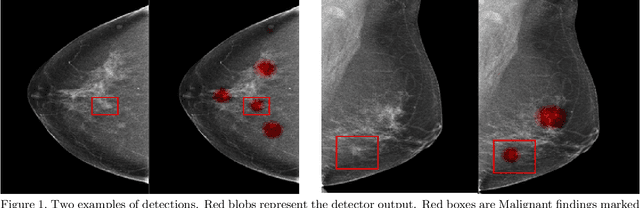
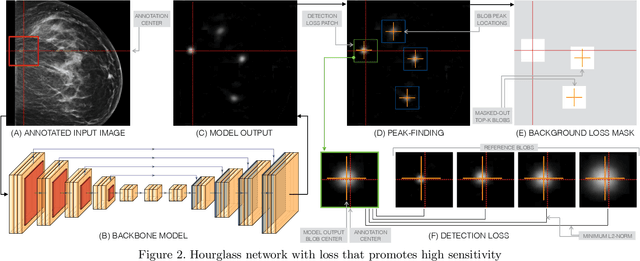
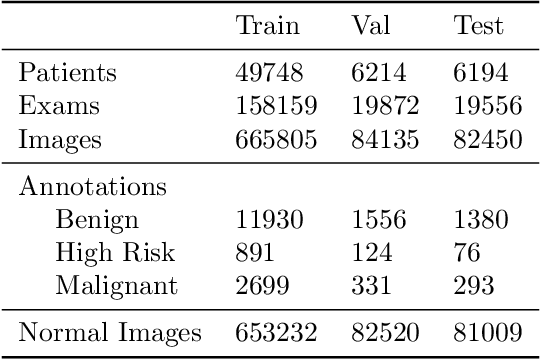
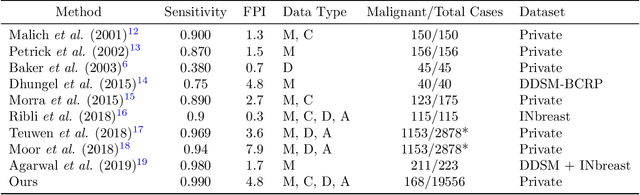
Early detection of breast cancer through screening mammography yields a 20-35% increase in survival rate; however, there are not enough radiologists to serve the growing population of women seeking screening mammography. Although commercial computer aided detection (CADe) software has been available to radiologists for decades, it has failed to improve the interpretation of full-field digital mammography (FFDM) images due to its low sensitivity over the spectrum of findings. In this work, we leverage a large set of FFDM images with loose bounding boxes of mammographically significant findings to train a deep learning detector with extreme sensitivity. Building upon work from the Hourglass architecture, we train a model that produces segmentation-like images with high spatial resolution, with the aim of producing 2D Gaussian blobs centered on ground-truth boxes. We replace the pixel-wise $L_2$ norm with a weak-supervision loss designed to achieve high sensitivity, asymmetrically penalizing false positives and false negatives while softening the noise of the loose bounding boxes by permitting a tolerance in misaligned predictions. The resulting system achieves a sensitivity for malignant findings of 0.99 with only 4.8 false positive markers per image. When utilized in a CADe system, this model could enable a novel workflow where radiologists can focus their attention with trust on only the locations proposed by the model, expediting the interpretation process and bringing attention to potential findings that could otherwise have been missed. Due to its nearly perfect sensitivity, the proposed detector can also be used as a high-performance proposal generator in two-stage detection systems.
Adaptation of a deep learning malignancy model from full-field digital mammography to digital breast tomosynthesis
Jan 23, 2020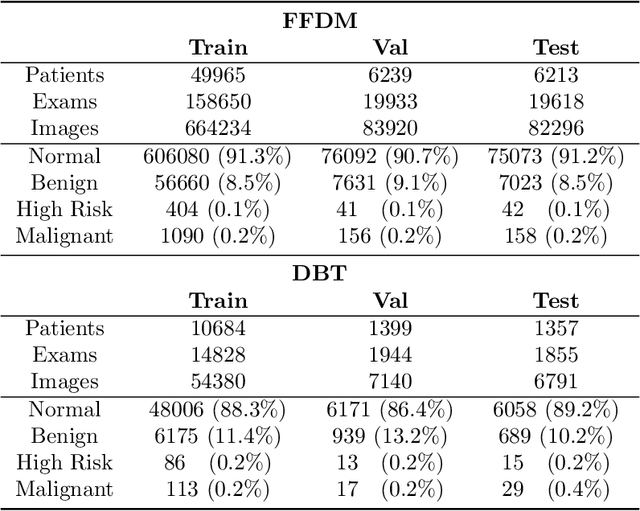
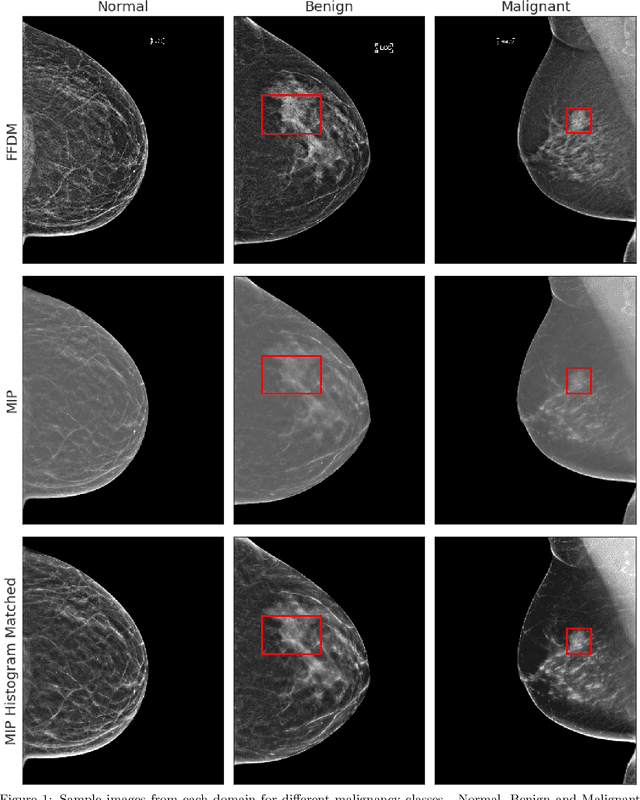
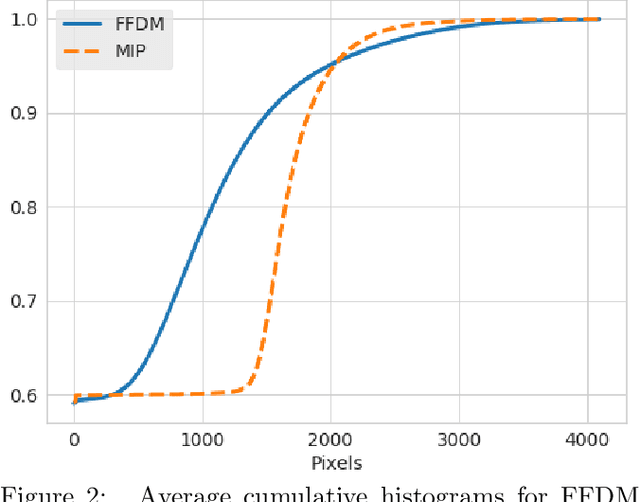

Mammography-based screening has helped reduce the breast cancer mortality rate, but has also been associated with potential harms due to low specificity, leading to unnecessary exams or procedures, and low sensitivity. Digital breast tomosynthesis (DBT) improves on conventional mammography by increasing both sensitivity and specificity and is becoming common in clinical settings. However, deep learning (DL) models have been developed mainly on conventional 2D full-field digital mammography (FFDM) or scanned film images. Due to a lack of large annotated DBT datasets, it is difficult to train a model on DBT from scratch. In this work, we present methods to generalize a model trained on FFDM images to DBT images. In particular, we use average histogram matching (HM) and DL fine-tuning methods to generalize a FFDM model to the 2D maximum intensity projection (MIP) of DBT images. In the proposed approach, the differences between the FFDM and DBT domains are reduced via HM and then the base model, which was trained on abundant FFDM images, is fine-tuned. When evaluating on image patches extracted around identified findings, we are able to achieve similar areas under the receiver operating characteristic curve (ROC AUC) of $\sim 0.9$ for FFDM and $\sim 0.85$ for MIP images, as compared to a ROC AUC of $\sim 0.75$ when tested directly on MIP images.
Towards VQA Models That Can Read
May 13, 2019
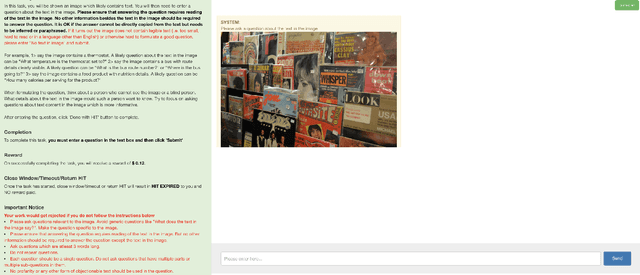
Studies have shown that a dominant class of questions asked by visually impaired users on images of their surroundings involves reading text in the image. But today's VQA models can not read! Our paper takes a first step towards addressing this problem. First, we introduce a new "TextVQA" dataset to facilitate progress on this important problem. Existing datasets either have a small proportion of questions about text (e.g., the VQA dataset) or are too small (e.g., the VizWiz dataset). TextVQA contains 45,336 questions on 28,408 images that require reasoning about text to answer. Second, we introduce a novel model architecture that reads text in the image, reasons about it in the context of the image and the question, and predicts an answer which might be a deduction based on the text and the image or composed of the strings found in the image. Consequently, we call our approach Look, Read, Reason & Answer (LoRRA). We show that LoRRA outperforms existing state-of-the-art VQA models on our TextVQA dataset. We find that the gap between human performance and machine performance is significantly larger on TextVQA than on VQA 2.0, suggesting that TextVQA is well-suited to benchmark progress along directions complementary to VQA 2.0.
Cycle-Consistency for Robust Visual Question Answering
Feb 15, 2019
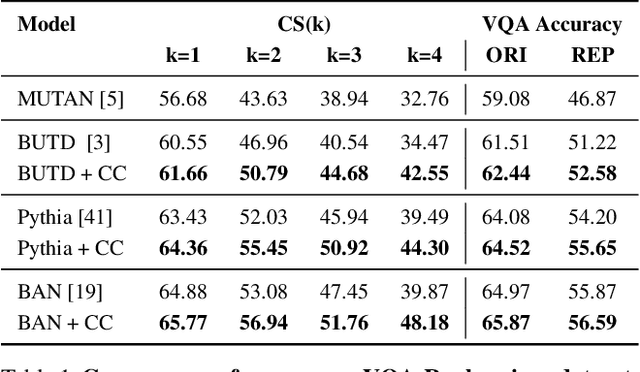
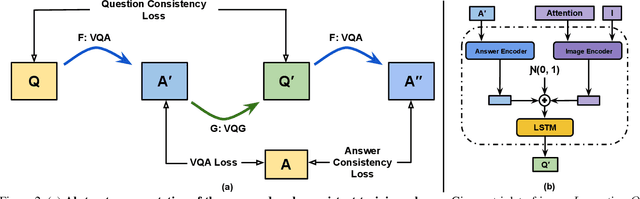
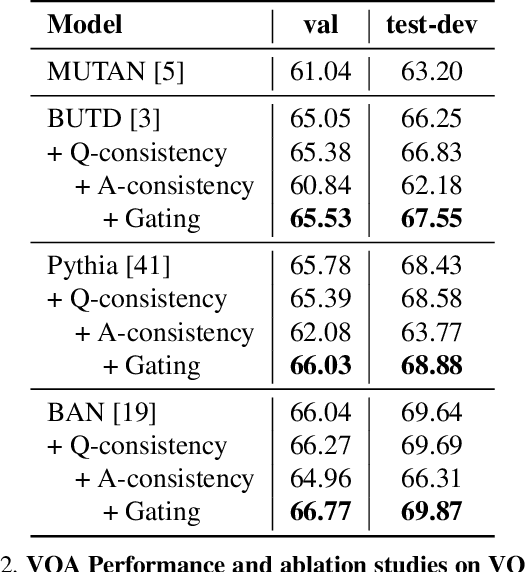
Despite significant progress in Visual Question Answering over the years, robustness of today's VQA models leave much to be desired. We introduce a new evaluation protocol and associated dataset (VQA-Rephrasings) and show that state-of-the-art VQA models are notoriously brittle to linguistic variations in questions. VQA-Rephrasings contains 3 human-provided rephrasings for 40k questions spanning 40k images from the VQA v2.0 validation dataset. As a step towards improving robustness of VQA models, we propose a model-agnostic framework that exploits cycle consistency. Specifically, we train a model to not only answer a question, but also generate a question conditioned on the answer, such that the answer predicted for the generated question is the same as the ground truth answer to the original question. Without the use of additional annotations, we show that our approach is significantly more robust to linguistic variations than state-of-the-art VQA models, when evaluated on the VQA-Rephrasings dataset. In addition, our approach outperforms state-of-the-art approaches on the standard VQA and Visual Question Generation tasks on the challenging VQA v2.0 dataset.
Annotation-cost Minimization for Medical Image Segmentation using Suggestive Mixed Supervision Fully Convolutional Networks
Dec 29, 2018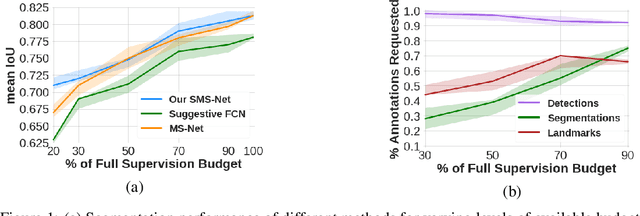
For medical image segmentation, most fully convolutional networks (FCNs) need strong supervision through a large sample of high-quality dense segmentations, which is taxing in terms of costs, time and logistics involved. This burden of annotation can be alleviated by exploiting weak inexpensive annotations such as bounding boxes and anatomical landmarks. However, it is very difficult to \textit{a priori} estimate the optimal balance between the number of annotations needed for each supervision type that leads to maximum performance with the least annotation cost. To optimize this cost-performance trade off, we present a budget-based cost-minimization framework in a mixed-supervision setting via dense segmentations, bounding boxes, and landmarks. We propose a linear programming (LP) formulation combined with uncertainty and similarity based ranking strategy to judiciously select samples to be annotated next for optimal performance. In the results section, we show that our proposed method achieves comparable performance to state-of-the-art approaches with significantly reduced cost of annotations.