 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Defense of the Triplet Loss for Visual Recognition
Paper and Code
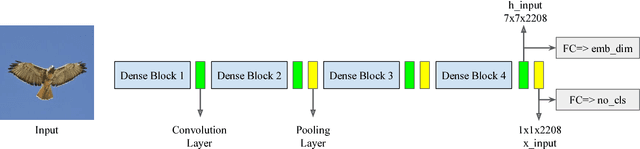
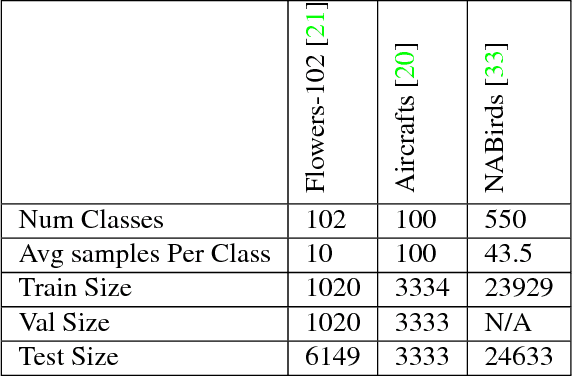
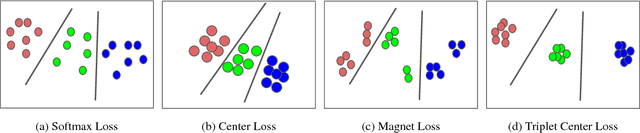

We employ triplet loss as a space embedding regularizer to boost classification performance. Standard architectures, like ResNet and DesneNet, are extended to support both losses with minimal hyper-parameter tuning. This promotes generality while fine-tuning pretrained networks. Triplet loss is a powerful surrogate for recently proposed embedding regularizers. Yet, it is avoided for large batch-size requirement and high computational cost. Through our experiments, we re-assess these assumptions. During inference, our network supports both classification and embedding tasks without any computational overhead. Quantitative evaluation highlights how our approach compares favorably to the existing state of the art on multiple fine-grained recognition datasets. Further evaluation on an imbalanced video dataset achieves significant improvement (>7%). Beyond boosting efficiency, triplet loss brings retrieval and interpretability to classification models.