 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Paediatric Sleep Apnoea Detection Using Physiology-Guided Acoustic Models
Sep 18, 2025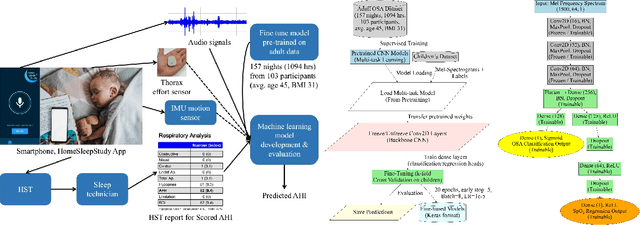



Paediatric obstructive sleep apnoea (OSA) is clinically significant yet difficult to diagnose, as children poorly tolerate sensor-based polysomnography. Acoustic monitoring provides a non-invasive alternative for home-based OSA screening, but limited paediatric data hinders the development of robust deep learning approaches. This paper proposes a transfer learning framework that adapts acoustic models pretrained on adult sleep data to paediatric OSA detection, incorporating SpO2-based desaturation patterns to enhance model training. Using a large adult sleep dataset (157 nights) and a smaller paediatric dataset (15 nights), we systematically evaluate (i) single- versus multi-task learning, (ii) encoder freezing versus full fine-tuning, and (iii) the impact of delaying SpO2 labels to better align them with the acoustics and capture physiologically meaningful features. Results show that fine-tuning with SpO2 integration consistently improves paediatric OSA detection compared with baseline models without adaptation. These findings demonstrate the feasibility of transfer learning for home-based OSA screening in children and offer its potential clinical value for early diagnosis.
GenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Aug 24, 2024

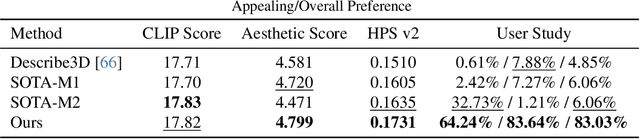
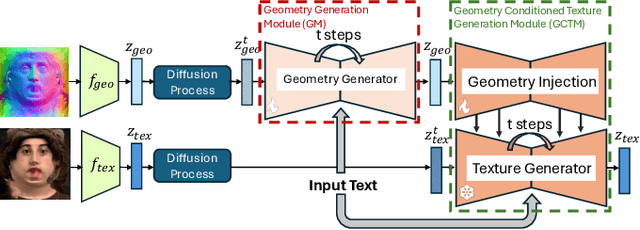
Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
Multimodal active speaker detection and virtual cinematography for video conferencing
Feb 12, 2020
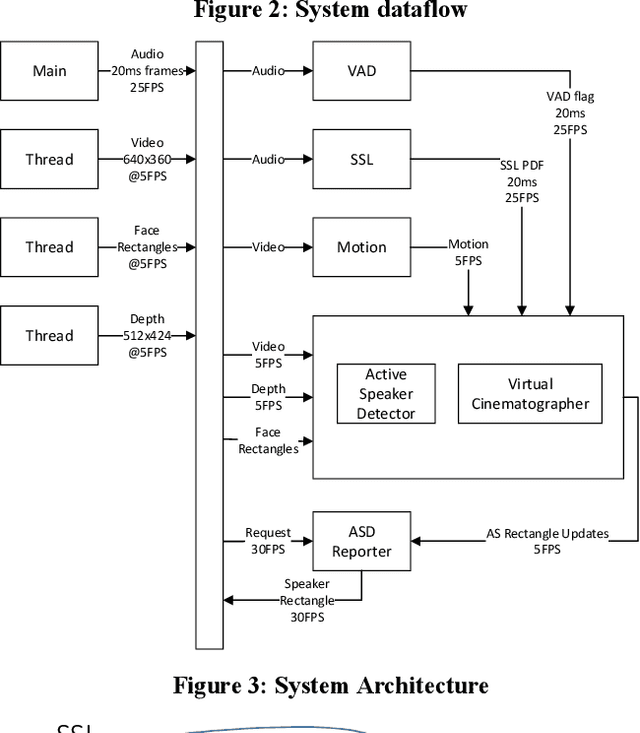

Active speaker detection (ASD) and virtual cinematography (VC) can significantly improve the remote user experience of a video conference by automatically panning, tilting and zooming of a video conferencing camera: users subjectively rate an expert video cinematographer's video significantly higher than unedited video. We describe a new automated ASD and VC that performs within 0.3 MOS of an expert cinematographer based on subjective ratings with a 1-5 scale. This system uses a 4K wide-FOV camera, a depth camera, and a microphone array; it extracts features from each modality and trains an ASD using an AdaBoost machine learning system that is very efficient and runs in real-time. A VC is similarly trained using machine learning to optimize the subjective quality of the overall experience. To avoid distracting the room participants and reduce switching latency the system has no moving parts -- the VC works by cropping and zooming the 4K wide-FOV video stream. The system was tuned and evaluated using extensive crowdsourcing techniques and evaluated on a dataset with N=100 meetings, each 2-5 minutes in length.
On Design of Problem Token Questions in Quality of Experience Surveys
Aug 19, 2018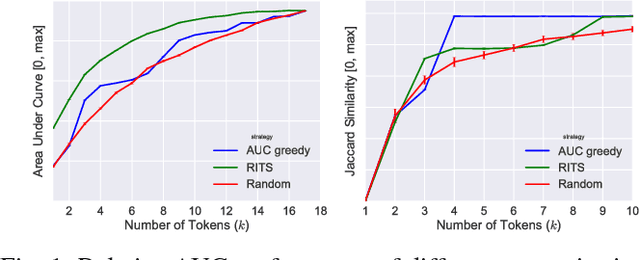
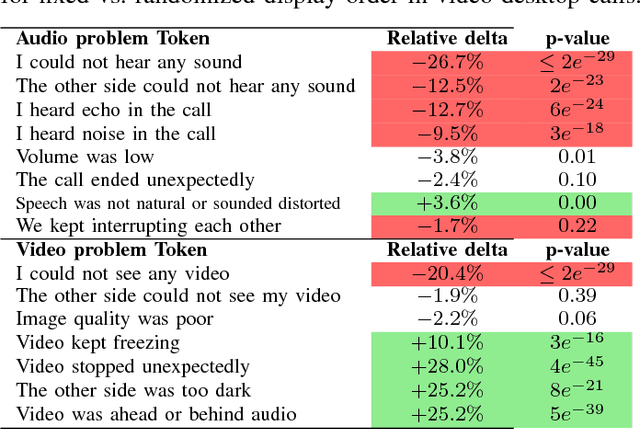
User surveys for Quality of Experience (QoE) are a critical source of information. In addition to the common "star rating" used to estimate Mean Opinion Score (MOS), more detailed survey questions (problem tokens) about specific areas provide valuable insight into the factors impacting QoE. This paper explores two aspects of the problem token questionnaire design. First, we study the bias introduced by fixed question order, and second, we study the challenge of selecting a subset of questions to keep the token set small. Based on 900,000 calls gathered using a randomized controlled experiment from a live system, we find that the order bias can be significantly reduced by randomizing the display order of tokens. The difference in response rate varies based on token position and display design. It is worth noting that the users respond to the randomized-order variant at levels that are comparable to the fixed-order variant. The effective selection of a subset of token questions is achieved by extracting tokens that provide the highest information gain over user ratings. This selection is known to be in the class of NP-hard problems. We apply a well-known greedy submodular maximization method on our dataset to capture 94% of the information using just 30% of the questions.