 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal active speaker detection and virtual cinematography for video conferencing
Paper and Code
Feb 12, 2020
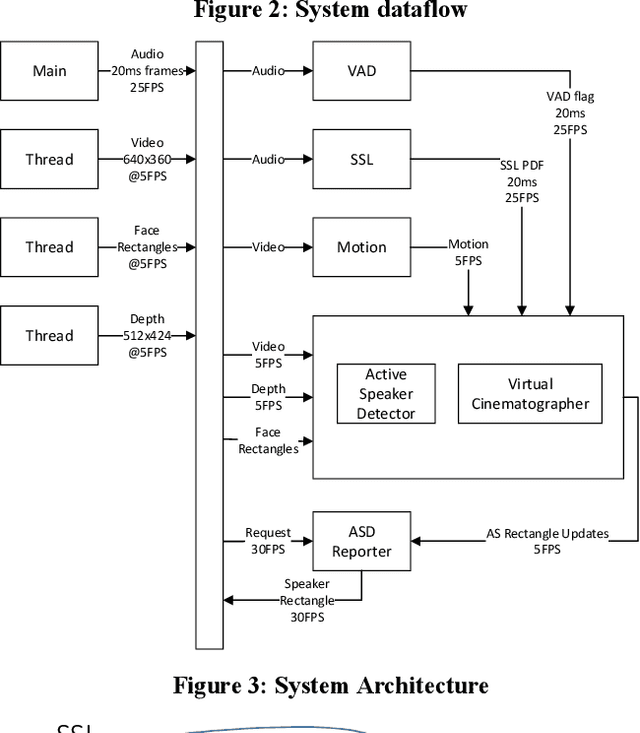

Active speaker detection (ASD) and virtual cinematography (VC) can significantly improve the remote user experience of a video conference by automatically panning, tilting and zooming of a video conferencing camera: users subjectively rate an expert video cinematographer's video significantly higher than unedited video. We describe a new automated ASD and VC that performs within 0.3 MOS of an expert cinematographer based on subjective ratings with a 1-5 scale. This system uses a 4K wide-FOV camera, a depth camera, and a microphone array; it extracts features from each modality and trains an ASD using an AdaBoost machine learning system that is very efficient and runs in real-time. A VC is similarly trained using machine learning to optimize the subjective quality of the overall experience. To avoid distracting the room participants and reduce switching latency the system has no moving parts -- the VC works by cropping and zooming the 4K wide-FOV video stream. The system was tuned and evaluated using extensive crowdsourcing techniques and evaluated on a dataset with N=100 meetings, each 2-5 minutes in length.