 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURAvatar: Universal Relightable Gaussian Codec Avatars
Oct 31, 2024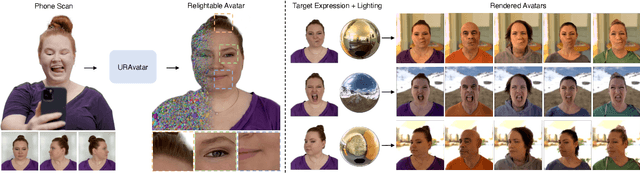

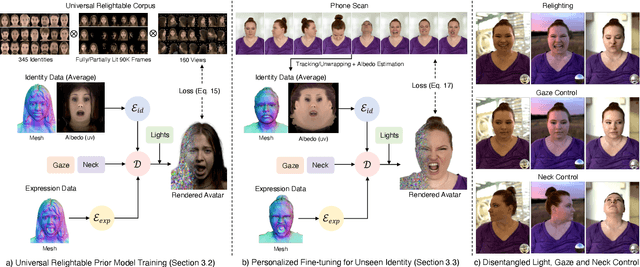
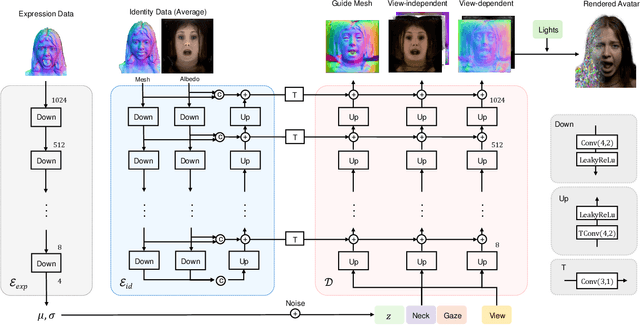
We present a new approach to creating photorealistic and relightable head avatars from a phone scan with unknown illumination. The reconstructed avatars can be animated and relit in real time with the global illumination of diverse environments. Unlike existing approaches that estimate parametric reflectance parameters via inverse rendering, our approach directly models learnable radiance transfer that incorporates global light transport in an efficient manner for real-time rendering. However, learning such a complex light transport that can generalize across identities is non-trivial. A phone scan in a single environment lacks sufficient information to infer how the head would appear in general environments. To address this, we build a universal relightable avatar model represented by 3D Gaussians. We train on hundreds of high-quality multi-view human scans with controllable point lights. High-resolution geometric guidance further enhances the reconstruction accuracy and generalization. Once trained, we finetune the pretrained model on a phone scan using inverse rendering to obtain a personalized relightable avatar. Our experiments establish the efficacy of our design, outperforming existing approaches while retaining real-time rendering capability.
Universal Facial Encoding of Codec Avatars from VR Headsets
Jul 17, 2024



Faithful real-time facial animation is essential for avatar-mediated telepresence in Virtual Reality (VR). To emulate authentic communication, avatar animation needs to be efficient and accurate: able to capture both extreme and subtle expressions within a few milliseconds to sustain the rhythm of natural conversations. The oblique and incomplete views of the face, variability in the donning of headsets, and illumination variation due to the environment are some of the unique challenges in generalization to unseen faces. In this paper, we present a method that can animate a photorealistic avatar in realtime from head-mounted cameras (HMCs) on a consumer VR headset. We present a self-supervised learning approach, based on a cross-view reconstruction objective, that enables generalization to unseen users. We present a lightweight expression calibration mechanism that increases accuracy with minimal additional cost to run-time efficiency. We present an improved parameterization for precise ground-truth generation that provides robustness to environmental variation. The resulting system produces accurate facial animation for unseen users wearing VR headsets in realtime. We compare our approach to prior face-encoding methods demonstrating significant improvements in both quantitative metrics and qualitative results.
* SIGGRAPH 2024 (ACM Transactions on Graphics (TOG))
Rasterized Edge Gradients: Handling Discontinuities Differentiably
May 03, 2024



Computing the gradients of a rendering process is paramount for diverse applications in computer vision and graphics. However, accurate computation of these gradients is challenging due to discontinuities and rendering approximations, particularly for surface-based representations and rasterization-based rendering. We present a novel method for computing gradients at visibility discontinuities for rasterization-based differentiable renderers. Our method elegantly simplifies the traditionally complex problem through a carefully designed approximation strategy, allowing for a straightforward, effective, and performant solution. We introduce a novel concept of micro-edges, which allows us to treat the rasterized images as outcomes of a differentiable, continuous process aligned with the inherently non-differentiable, discrete-pixel rasterization. This technique eliminates the necessity for rendering approximations or other modifications to the forward pass, preserving the integrity of the rendered image, which makes it applicable to rasterized masks, depth, and normals images where filtering is prohibitive. Utilizing micro-edges simplifies gradient interpretation at discontinuities and enables handling of geometry intersections, offering an advantage over the prior art. We showcase our method in dynamic human head scene reconstruction, demonstrating effective handling of camera images and segmentation masks.
Relightable Gaussian Codec Avatars
Dec 06, 2023



The fidelity of relighting is bounded by both geometry and appearance representations. For geometry, both mesh and volumetric approaches have difficulty modeling intricate structures like 3D hair geometry. For appearance, existing relighting models are limited in fidelity and often too slow to render in real-time with high-resolution continuous environments. In this work, we present Relightable Gaussian Codec Avatars, a method to build high-fidelity relightable head avatars that can be animated to generate novel expressions. Our geometry model based on 3D Gaussians can capture 3D-consistent sub-millimeter details such as hair strands and pores on dynamic face sequences. To support diverse materials of human heads such as the eyes, skin, and hair in a unified manner, we present a novel relightable appearance model based on learnable radiance transfer. Together with global illumination-aware spherical harmonics for the diffuse components, we achieve real-time relighting with spatially all-frequency reflections using spherical Gaussians. This appearance model can be efficiently relit under both point light and continuous illumination. We further improve the fidelity of eye reflections and enable explicit gaze control by introducing relightable explicit eye models. Our method outperforms existing approaches without compromising real-time performance. We also demonstrate real-time relighting of avatars on a tethered consumer VR headset, showcasing the efficiency and fidelity of our avatars.
AlteredAvatar: Stylizing Dynamic 3D Avatars with Fast Style Adaptation
May 30, 2023This paper presents a method that can quickly adapt dynamic 3D avatars to arbitrary text descriptions of novel styles. Among existing approaches for avatar stylization, direct optimization methods can produce excellent results for arbitrary styles but they are unpleasantly slow. Furthermore, they require redoing the optimization process from scratch for every new input. Fast approximation methods using feed-forward networks trained on a large dataset of style images can generate results for new inputs quickly, but tend not to generalize well to novel styles and fall short in quality. We therefore investigate a new approach, AlteredAvatar, that combines those two approaches using the meta-learning framework. In the inner loop, the model learns to optimize to match a single target style well; while in the outer loop, the model learns to stylize efficiently across many styles. After training, AlteredAvatar learns an initialization that can quickly adapt within a small number of update steps to a novel style, which can be given using texts, a reference image, or a combination of both. We show that AlteredAvatar can achieve a good balance between speed, flexibility and quality, while maintaining consistency across a wide range of novel views and facial expressions.
Mixture of Volumetric Primitives for Efficient Neural Rendering
Mar 02, 2021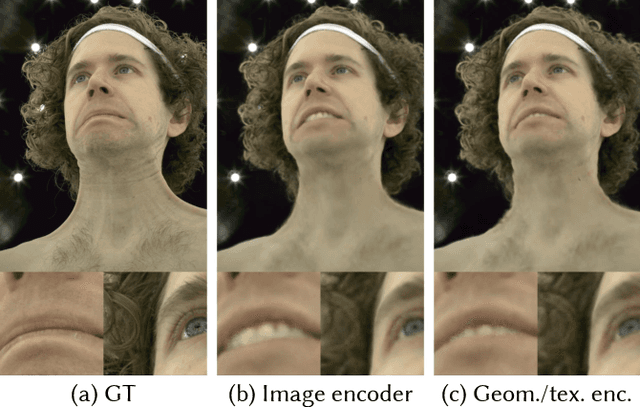
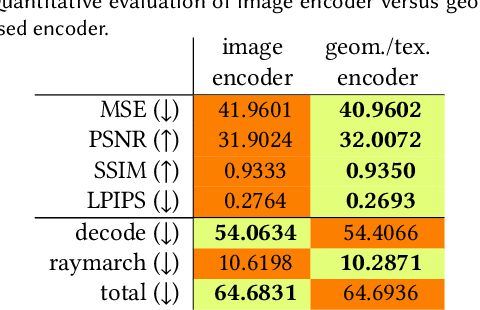
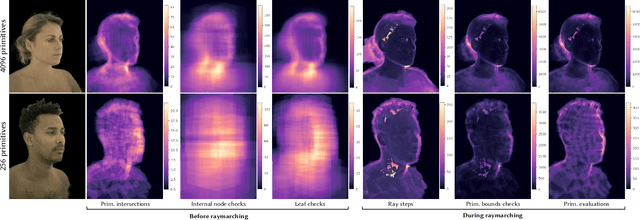
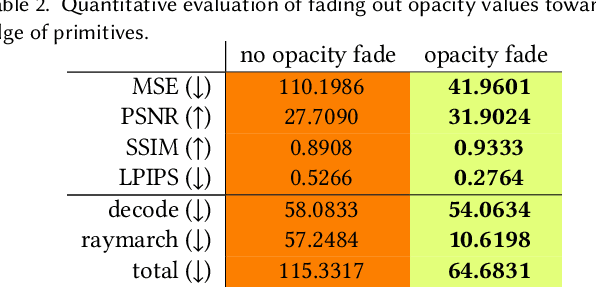
Real-time rendering and animation of humans is a core function in games, movies, and telepresence applications. Existing methods have a number of drawbacks we aim to address with our work. Triangle meshes have difficulty modeling thin structures like hair, volumetric representations like Neural Volumes are too low-resolution given a reasonable memory budget, and high-resolution implicit representations like Neural Radiance Fields are too slow for use in real-time applications. We present Mixture of Volumetric Primitives (MVP), a representation for rendering dynamic 3D content that combines the completeness of volumetric representations with the efficiency of primitive-based rendering, e.g., point-based or mesh-based methods. Our approach achieves this by leveraging spatially shared computation with a deconvolutional architecture and by minimizing computation in empty regions of space with volumetric primitives that can move to cover only occupied regions. Our parameterization supports the integration of correspondence and tracking constraints, while being robust to areas where classical tracking fails, such as around thin or translucent structures and areas with large topological variability. MVP is a hybrid that generalizes both volumetric and primitive-based representations. Through a series of extensive experiments we demonstrate that it inherits the strengths of each, while avoiding many of their limitations. We also compare our approach to several state-of-the-art methods and demonstrate that MVP produces superior results in terms of quality and runtime performance.
Neural Volumes: Learning Dynamic Renderable Volumes from Images
Jun 18, 2019

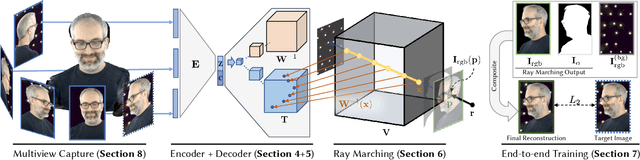
Modeling and rendering of dynamic scenes is challenging, as natural scenes often contain complex phenomena such as thin structures, evolving topology, translucency, scattering, occlusion, and biological motion. Mesh-based reconstruction and tracking often fail in these cases, and other approaches (e.g., light field video) typically rely on constrained viewing conditions, which limit interactivity. We circumvent these difficulties by presenting a learning-based approach to representing dynamic objects inspired by the integral projection model used in tomographic imaging. The approach is supervised directly from 2D images in a multi-view capture setting and does not require explicit reconstruction or tracking of the object. Our method has two primary components: an encoder-decoder network that transforms input images into a 3D volume representation, and a differentiable ray-marching operation that enables end-to-end training. By virtue of its 3D representation, our construction extrapolates better to novel viewpoints compared to screen-space rendering techniques. The encoder-decoder architecture learns a latent representation of a dynamic scene that enables us to produce novel content sequences not seen during training. To overcome memory limitations of voxel-based representations, we learn a dynamic irregular grid structure implemented with a warp field during ray-marching. This structure greatly improves the apparent resolution and reduces grid-like artifacts and jagged motion. Finally, we demonstrate how to incorporate surface-based representations into our volumetric-learning framework for applications where the highest resolution is required, using facial performance capture as a case in point.
Recognizing Material Properties from Images
Jan 09, 2018
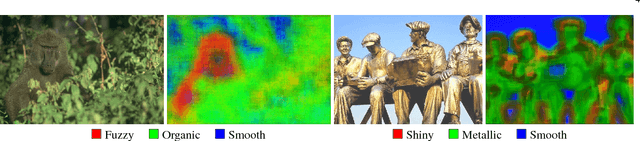


Humans rely on properties of the materials that make up objects to guide our interactions with them. Grasping smooth materials, for example, requires care, and softness is an ideal property for fabric used in bedding. Even when these properties are not visual (e.g. softness is a physical property), we may still infer their presence visually. We refer to such material properties as visual material attributes. Recognizing these attributes in images can contribute valuable information for general scene understanding and material recognition. Unlike well-known object and scene attributes, visual material attributes are local properties with no fixed shape or spatial extent. We show that given a set of images annotated with known material attributes, we may accurately recognize the attributes from small local image patches. Obtaining such annotations in a consistent fashion at scale, however, is challenging. To address this, we introduce a method that allows us to probe the human visual perception of materials by asking simple yes/no questions comparing pairs of image patches. This provides sufficient weak supervision to build a set of attributes and associated classifiers that, while unnamed, serve the same function as the named attributes we use to describe materials. Doing so allows us to recognize visual material attributes without resorting to exhaustive manual annotation of a fixed set of named attributes. Furthermore, we show that this method may be integrated in the end-to-end learning of a material classification CNN to simultaneously recognize materials and discover their visual attributes. Our experimental results show that visual material attributes, whether named or automatically discovered, provide a useful intermediate representation for known material categories themselves as well as a basis for transfer learning when recognizing previously-unseen categories.
Material Recognition from Local Appearance in Global Context
Apr 12, 2017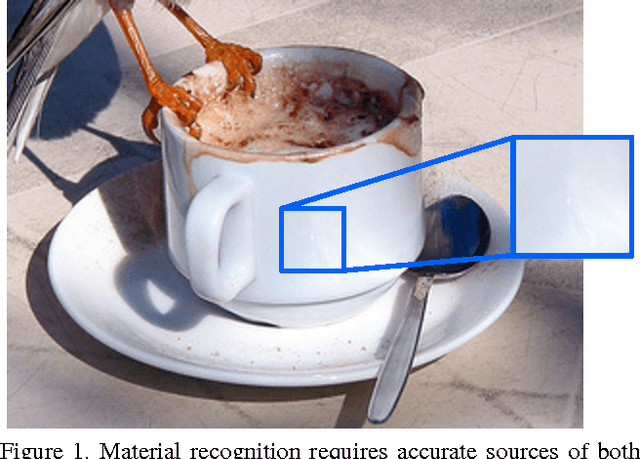

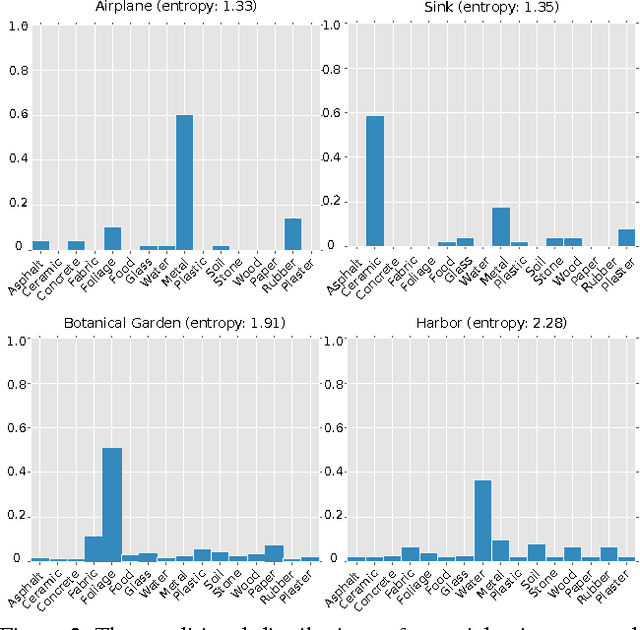
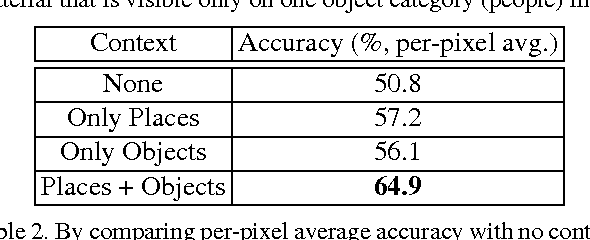
Recognition of materials has proven to be a challenging problem due to the wide variation in appearance within and between categories. Global image context, such as where the material is or what object it makes up, can be crucial to recognizing the material. Existing methods, however, operate on an implicit fusion of materials and context by using large receptive fields as input (i.e., large image patches). Many recent material recognition methods treat materials as yet another set of labels like objects. Materials are, however, fundamentally different from objects as they have no inherent shape or defined spatial extent. Approaches that ignore this can only take advantage of limited implicit context as it appears during training. We instead show that recognizing materials purely from their local appearance and integrating separately recognized global contextual cues including objects and places leads to superior dense, per-pixel, material recognition. We achieve this by training a fully-convolutional material recognition network end-to-end with only material category supervision. We integrate object and place estimates to this network from independent CNNs. This approach avoids the necessity of preparing an impractically-large amount of training data to cover the product space of materials, objects, and scenes, while fully leveraging contextual cues for dense material recognition. Furthermore, we perform a detailed analysis of the effects of context granularity, spatial resolution, and the network level at which we introduce context. On a recently introduced comprehensive and diverse material database \cite{Schwartz2016}, we confirm that our method achieves state-of-the-art accuracy with significantly less training data compared to past methods.
Integrating Local Material Recognition with Large-Scale Perceptual Attribute Discovery
Apr 12, 2017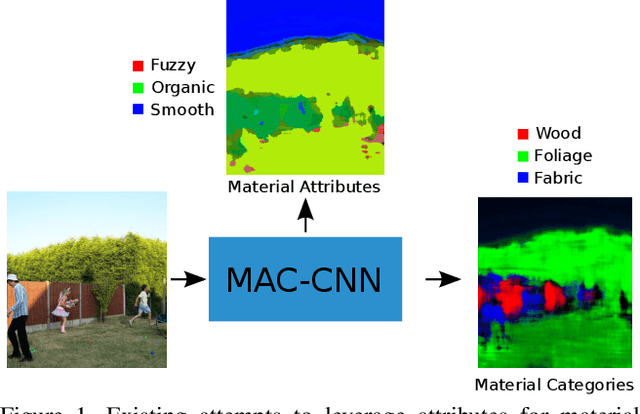



Material attributes have been shown to provide a discriminative intermediate representation for recognizing materials, especially for the challenging task of recognition from local material appearance (i.e., regardless of object and scene context). In the past, however, material attributes have been recognized separately preceding category recognition. In contrast, neuroscience studies on material perception and computer vision research on object and place recognition have shown that attributes are produced as a by-product during the category recognition process. Does the same hold true for material attribute and category recognition? In this paper, we introduce a novel material category recognition network architecture to show that perceptual attributes can, in fact, be automatically discovered inside a local material recognition framework. The novel material-attribute-category convolutional neural network (MAC-CNN) produces perceptual material attributes from the intermediate pooling layers of an end-to-end trained category recognition network using an auxiliary loss function that encodes human material perception. To train this model, we introduce a novel large-scale database of local material appearance organized under a canonical material category taxonomy and careful image patch extraction that avoids unwanted object and scene context. We show that the discovered attributes correspond well with semantically-meaningful visual material traits via Boolean algebra, and enable recognition of previously unseen material categories given only a few examples. These results have strong implications in how perceptually meaningful attributes can be learned in other recognition tasks.