 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial Recognition from Local Appearance in Global Context
Paper and Code
Apr 12, 2017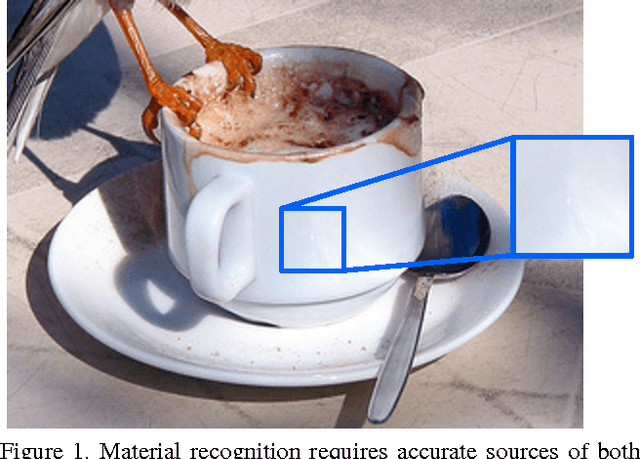

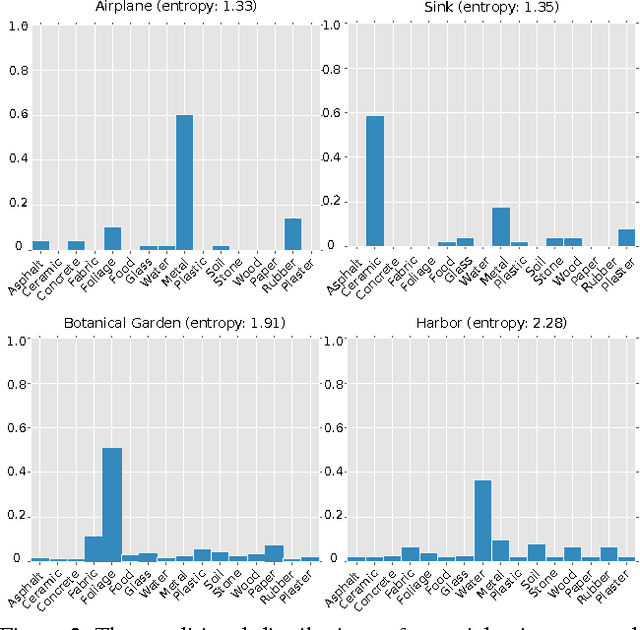
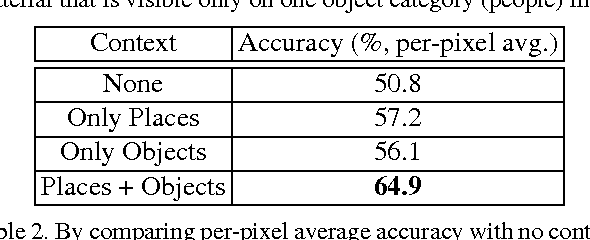
Recognition of materials has proven to be a challenging problem due to the wide variation in appearance within and between categories. Global image context, such as where the material is or what object it makes up, can be crucial to recognizing the material. Existing methods, however, operate on an implicit fusion of materials and context by using large receptive fields as input (i.e., large image patches). Many recent material recognition methods treat materials as yet another set of labels like objects. Materials are, however, fundamentally different from objects as they have no inherent shape or defined spatial extent. Approaches that ignore this can only take advantage of limited implicit context as it appears during training. We instead show that recognizing materials purely from their local appearance and integrating separately recognized global contextual cues including objects and places leads to superior dense, per-pixel, material recognition. We achieve this by training a fully-convolutional material recognition network end-to-end with only material category supervision. We integrate object and place estimates to this network from independent CNNs. This approach avoids the necessity of preparing an impractically-large amount of training data to cover the product space of materials, objects, and scenes, while fully leveraging contextual cues for dense material recognition. Furthermore, we perform a detailed analysis of the effects of context granularity, spatial resolution, and the network level at which we introduce context. On a recently introduced comprehensive and diverse material database \cite{Schwartz2016}, we confirm that our method achieves state-of-the-art accuracy with significantly less training data compared to past methods.