 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Volumes: Learning Dynamic Renderable Volumes from Images
Paper and Code


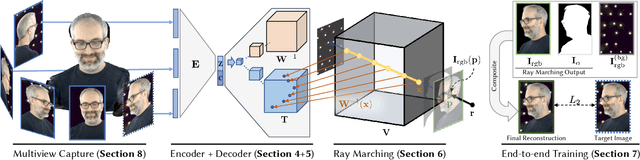
Modeling and rendering of dynamic scenes is challenging, as natural scenes often contain complex phenomena such as thin structures, evolving topology, translucency, scattering, occlusion, and biological motion. Mesh-based reconstruction and tracking often fail in these cases, and other approaches (e.g., light field video) typically rely on constrained viewing conditions, which limit interactivity. We circumvent these difficulties by presenting a learning-based approach to representing dynamic objects inspired by the integral projection model used in tomographic imaging. The approach is supervised directly from 2D images in a multi-view capture setting and does not require explicit reconstruction or tracking of the object. Our method has two primary components: an encoder-decoder network that transforms input images into a 3D volume representation, and a differentiable ray-marching operation that enables end-to-end training. By virtue of its 3D representation, our construction extrapolates better to novel viewpoints compared to screen-space rendering techniques. The encoder-decoder architecture learns a latent representation of a dynamic scene that enables us to produce novel content sequences not seen during training. To overcome memory limitations of voxel-based representations, we learn a dynamic irregular grid structure implemented with a warp field during ray-marching. This structure greatly improves the apparent resolution and reduces grid-like artifacts and jagged motion. Finally, we demonstrate how to incorporate surface-based representations into our volumetric-learning framework for applications where the highest resolution is required, using facial performance capture as a case in point.