 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaConF: Dynamic Forecasting of Non-Stationary Time-Series
Sep 17, 2022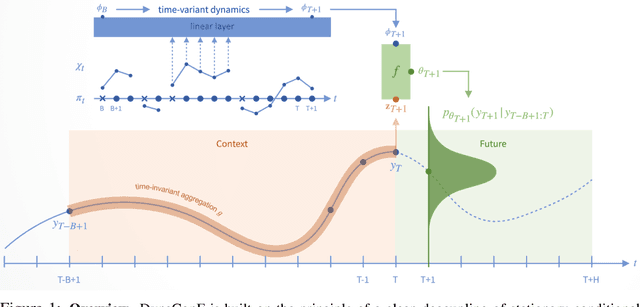
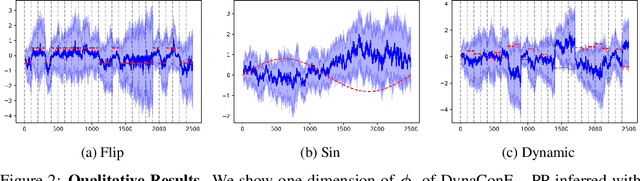
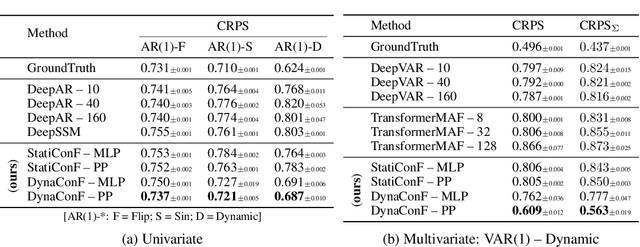
Deep learning models have shown impressive results in a variety of time series forecasting tasks, where modeling the conditional distribution of the future given the past is the essence. However, when this conditional distribution is non-stationary, it poses challenges for these models to learn consistently and to predict accurately. In this work, we propose a new method to model non-stationary conditional distributions over time by clearly decoupling stationary conditional distribution modeling from non-stationary dynamics modeling. Our method is based on a Bayesian dynamic model that can adapt to conditional distribution changes and a deep conditional distribution model that can handle large multivariate time series using a factorized output space. Our experimental results on synthetic and popular public datasets show that our model can adapt to non-stationary time series better than state-of-the-art deep learning solutions.
Efficient CDF Approximations for Normalizing Flows
Feb 23, 2022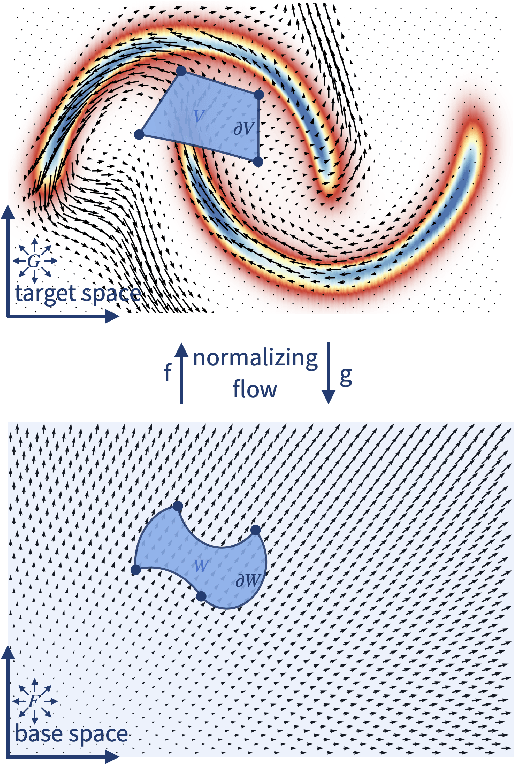

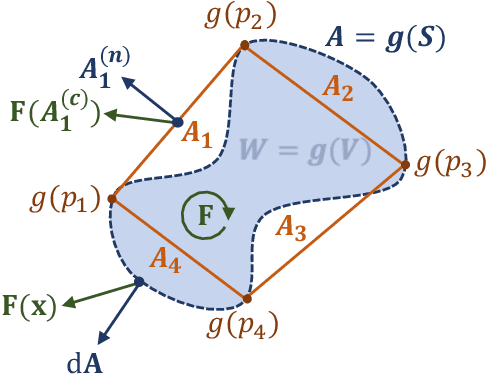
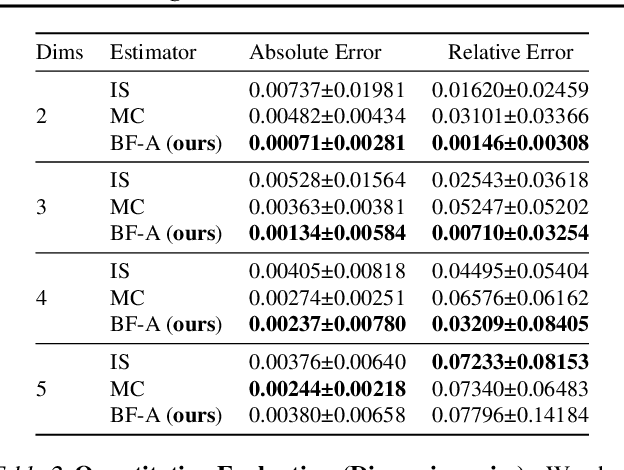
Normalizing flows model a complex target distribution in terms of a bijective transform operating on a simple base distribution. As such, they enable tractable computation of a number of important statistical quantities, particularly likelihoods and samples. Despite these appealing properties, the computation of more complex inference tasks, such as the cumulative distribution function (CDF) over a complex region (e.g., a polytope) remains challenging. Traditional CDF approximations using Monte-Carlo techniques are unbiased but have unbounded variance and low sample efficiency. Instead, we build upon the diffeomorphic properties of normalizing flows and leverage the divergence theorem to estimate the CDF over a closed region in target space in terms of the flux across its \emph{boundary}, as induced by the normalizing flow. We describe both deterministic and stochastic instances of this estimator: while the deterministic variant iteratively improves the estimate by strategically subdividing the boundary, the stochastic variant provides unbiased estimates. Our experiments on popular flow architectures and UCI benchmark datasets show a marked improvement in sample efficiency as compared to traditional estimators.
Modeling Continuous Stochastic Processes with Dynamic Normalizing Flows
Feb 24, 2020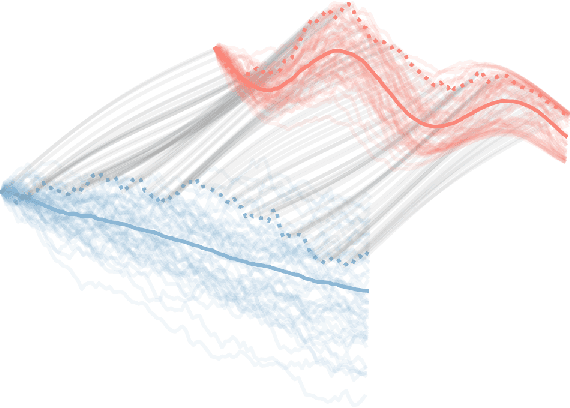
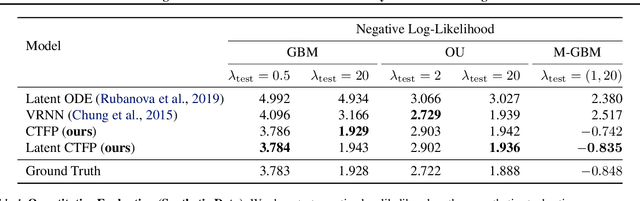
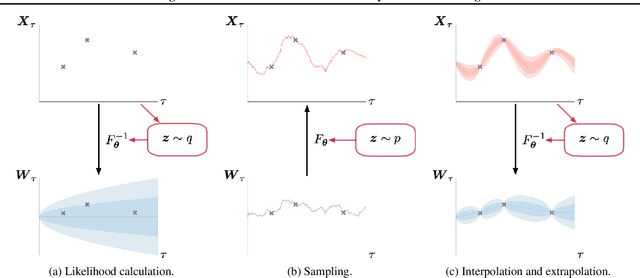

Normalizing flows transform a simple base distribution into a complex target distribution and have proved to be powerful models for data generation and density estimation. In this work, we propose a novel type of normalizing flow driven by a differential deformation of the continuous-time Wiener process. As a result, we obtain a rich time series model whose observable process inherits many of the appealing properties of its base process, such as efficient computation of likelihoods and marginals. Furthermore, our continuous treatment provides a natural framework for irregular time series with an independent arrival process, including straightforward interpolation. We illustrate the desirable properties of the proposed model on popular stochastic processes and demonstrate its superior flexibility to variational RNN and latent ODE baselines in a series of experiments on synthetic and real-world data.
Zero-Shot Generation of Human-Object Interaction Videos
Dec 09, 2019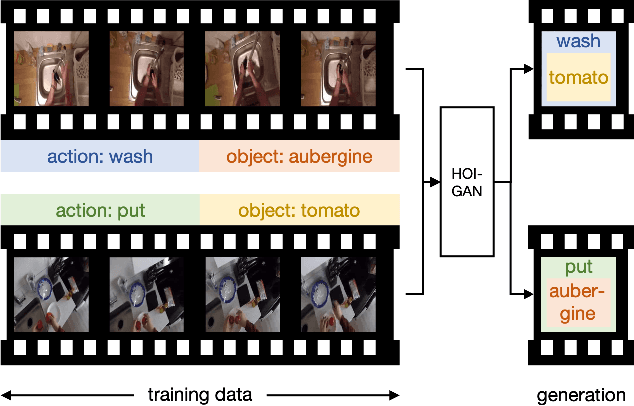
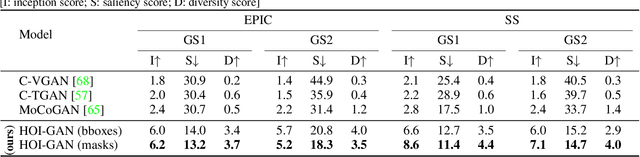
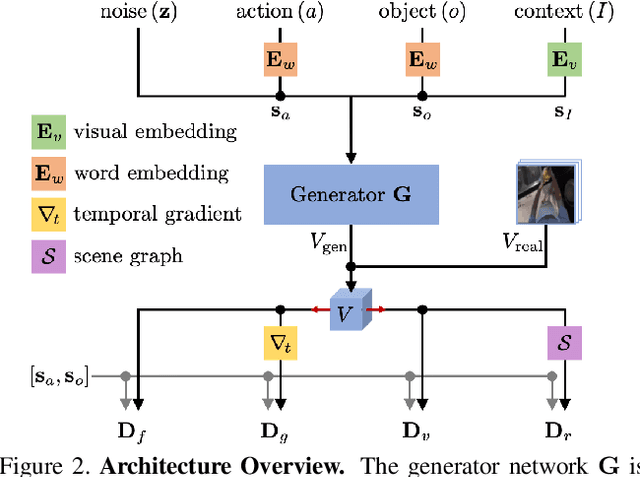
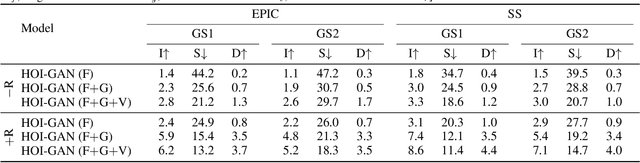
Generation of videos of complex scenes is an important open problem in computer vision research. Human activity videos are a good example of such complex scenes. Human activities are typically formed as compositions of actions applied to objects -- modeling interactions between people and the physical world are a core part of visual understanding. In this paper, we introduce the task of generating human-object interaction videos in a zero-shot compositional setting, i.e., generating videos for action-object compositions that are unseen during training, having seen the target action and target object independently. To generate human-object interaction videos, we propose a novel adversarial framework HOI-GAN which includes multiple discriminators focusing on different aspects of a video. To demonstrate the effectiveness of our proposed framework, we perform extensive quantitative and qualitative evaluation on two challenging datasets: EPIC-Kitchens and 20BN-Something-Something v2.
Neural Volumes: Learning Dynamic Renderable Volumes from Images
Jun 18, 2019

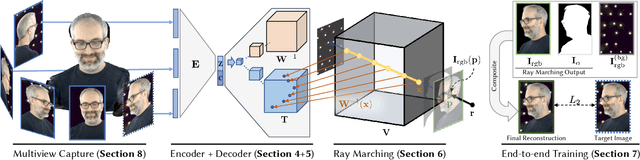
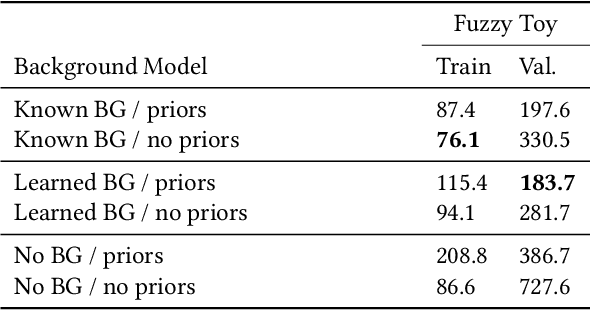
Modeling and rendering of dynamic scenes is challenging, as natural scenes often contain complex phenomena such as thin structures, evolving topology, translucency, scattering, occlusion, and biological motion. Mesh-based reconstruction and tracking often fail in these cases, and other approaches (e.g., light field video) typically rely on constrained viewing conditions, which limit interactivity. We circumvent these difficulties by presenting a learning-based approach to representing dynamic objects inspired by the integral projection model used in tomographic imaging. The approach is supervised directly from 2D images in a multi-view capture setting and does not require explicit reconstruction or tracking of the object. Our method has two primary components: an encoder-decoder network that transforms input images into a 3D volume representation, and a differentiable ray-marching operation that enables end-to-end training. By virtue of its 3D representation, our construction extrapolates better to novel viewpoints compared to screen-space rendering techniques. The encoder-decoder architecture learns a latent representation of a dynamic scene that enables us to produce novel content sequences not seen during training. To overcome memory limitations of voxel-based representations, we learn a dynamic irregular grid structure implemented with a warp field during ray-marching. This structure greatly improves the apparent resolution and reduces grid-like artifacts and jagged motion. Finally, we demonstrate how to incorporate surface-based representations into our volumetric-learning framework for applications where the highest resolution is required, using facial performance capture as a case in point.
Visual Reference Resolution using Attention Memory for Visual Dialog
Aug 06, 2018
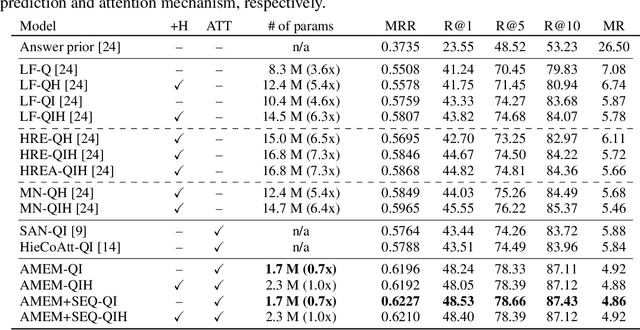
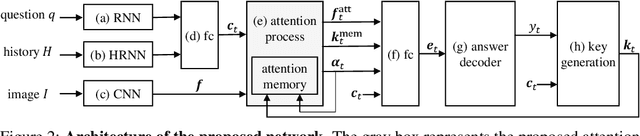
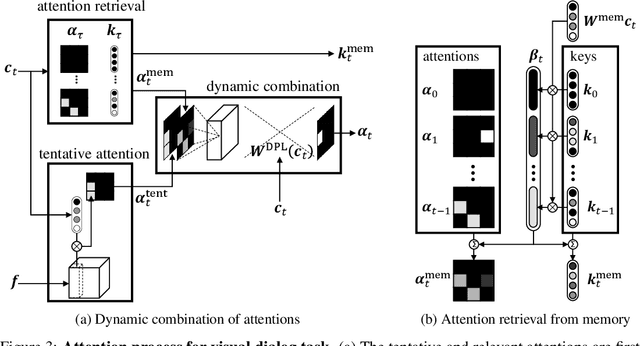
Visual dialog is a task of answering a series of inter-dependent questions given an input image, and often requires to resolve visual references among the questions. This problem is different from visual question answering (VQA), which relies on spatial attention (a.k.a. visual grounding) estimated from an image and question pair. We propose a novel attention mechanism that exploits visual attentions in the past to resolve the current reference in the visual dialog scenario. The proposed model is equipped with an associative attention memory storing a sequence of previous (attention, key) pairs. From this memory, the model retrieves the previous attention, taking into account recency, which is most relevant for the current question, in order to resolve potentially ambiguous references. The model then merges the retrieved attention with a tentative one to obtain the final attention for the current question; specifically, we use dynamic parameter prediction to combine the two attentions conditioned on the question. Through extensive experiments on a new synthetic visual dialog dataset, we show that our model significantly outperforms the state-of-the-art (by ~16 % points) in situations, where visual reference resolution plays an important role. Moreover, the proposed model achieves superior performance (~ 2 % points improvement) in the Visual Dialog dataset, despite having significantly fewer parameters than the baselines.
Probabilistic Video Generation using Holistic Attribute Control
Mar 21, 2018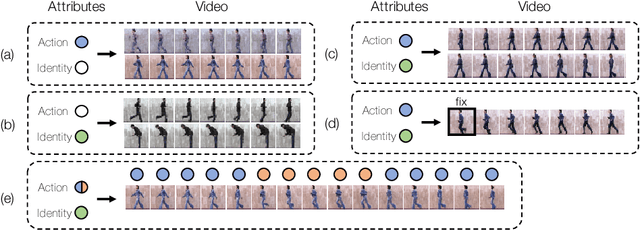
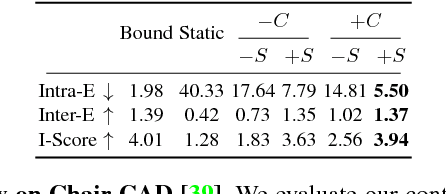
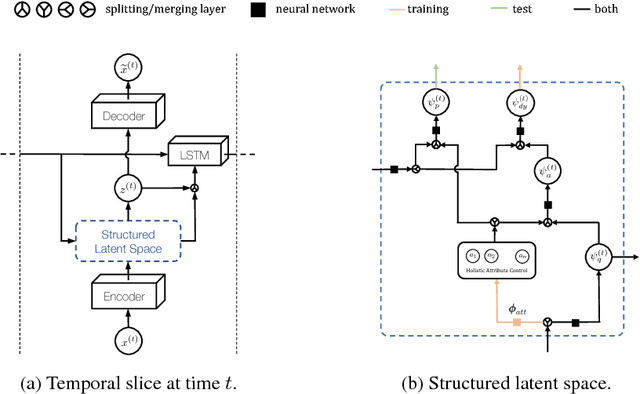

Videos express highly structured spatio-temporal patterns of visual data. A video can be thought of as being governed by two factors: (i) temporally invariant (e.g., person identity), or slowly varying (e.g., activity), attribute-induced appearance, encoding the persistent content of each frame, and (ii) an inter-frame motion or scene dynamics (e.g., encoding evolution of the person ex-ecuting the action). Based on this intuition, we propose a generative framework for video generation and future prediction. The proposed framework generates a video (short clip) by decoding samples sequentially drawn from a latent space distribution into full video frames. Variational Autoencoders (VAEs) are used as a means of encoding/decoding frames into/from the latent space and RNN as a wayto model the dynamics in the latent space. We improve the video generation consistency through temporally-conditional sampling and quality by structuring the latent space with attribute controls; ensuring that attributes can be both inferred and conditioned on during learning/generation. As a result, given attributes and/orthe first frame, our model is able to generate diverse but highly consistent sets ofvideo sequences, accounting for the inherent uncertainty in the prediction task. Experimental results on Chair CAD, Weizmann Human Action, and MIT-Flickr datasets, along with detailed comparison to the state-of-the-art, verify effectiveness of the framework.