 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Generation of Human-Object Interaction Videos
Paper and Code
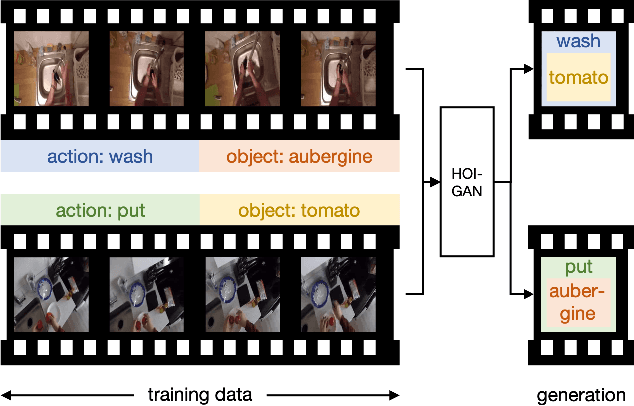
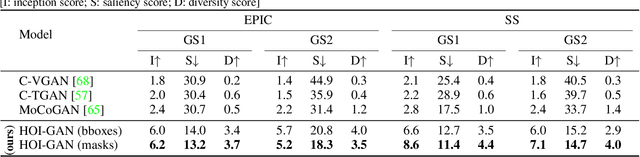
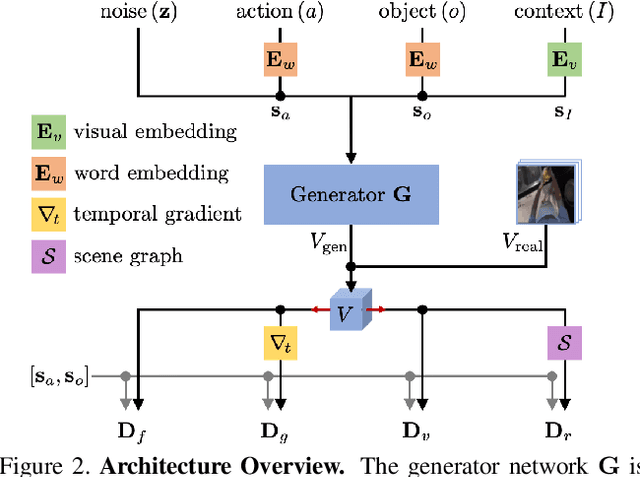
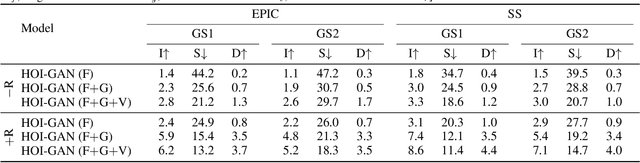
Generation of videos of complex scenes is an important open problem in computer vision research. Human activity videos are a good example of such complex scenes. Human activities are typically formed as compositions of actions applied to objects -- modeling interactions between people and the physical world are a core part of visual understanding. In this paper, we introduce the task of generating human-object interaction videos in a zero-shot compositional setting, i.e., generating videos for action-object compositions that are unseen during training, having seen the target action and target object independently. To generate human-object interaction videos, we propose a novel adversarial framework HOI-GAN which includes multiple discriminators focusing on different aspects of a video. To demonstrate the effectiveness of our proposed framework, we perform extensive quantitative and qualitative evaluation on two challenging datasets: EPIC-Kitchens and 20BN-Something-Something v2.