 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiggyback GAN: Efficient Lifelong Learning for Image Conditioned Generation
Apr 24, 2021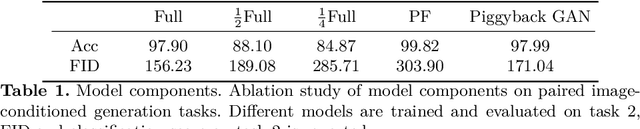
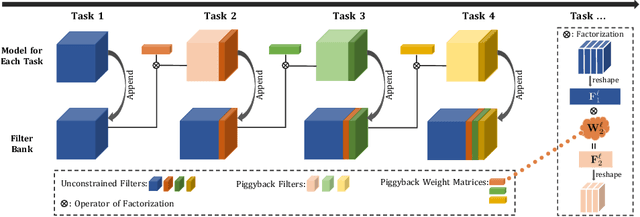
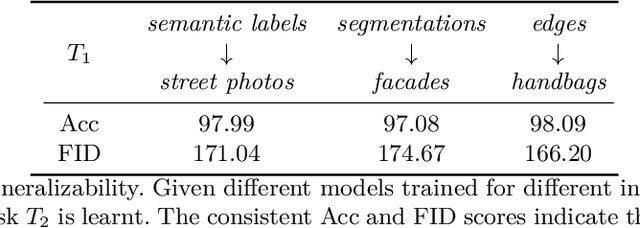
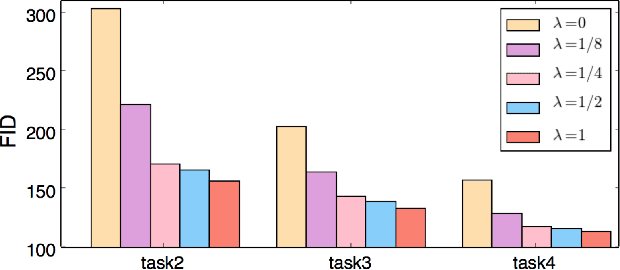
Humans accumulate knowledge in a lifelong fashion. Modern deep neural networks, on the other hand, are susceptible to catastrophic forgetting: when adapted to perform new tasks, they often fail to preserve their performance on previously learned tasks. Given a sequence of tasks, a naive approach addressing catastrophic forgetting is to train a separate standalone model for each task, which scales the total number of parameters drastically without efficiently utilizing previous models. In contrast, we propose a parameter efficient framework, Piggyback GAN, which learns the current task by building a set of convolutional and deconvolutional filters that are factorized into filters of the models trained on previous tasks. For the current task, our model achieves high generation quality on par with a standalone model at a lower number of parameters. For previous tasks, our model can also preserve generation quality since the filters for previous tasks are not altered. We validate Piggyback GAN on various image-conditioned generation tasks across different domains, and provide qualitative and quantitative results to show that the proposed approach can address catastrophic forgetting effectively and efficiently.
Activity Graph Transformer for Temporal Action Localization
Jan 28, 2021



We introduce Activity Graph Transformer, an end-to-end learnable model for temporal action localization, that receives a video as input and directly predicts a set of action instances that appear in the video. Detecting and localizing action instances in untrimmed videos requires reasoning over multiple action instances in a video. The dominant paradigms in the literature process videos temporally to either propose action regions or directly produce frame-level detections. However, sequential processing of videos is problematic when the action instances have non-sequential dependencies and/or non-linear temporal ordering, such as overlapping action instances or re-occurrence of action instances over the course of the video. In this work, we capture this non-linear temporal structure by reasoning over the videos as non-sequential entities in the form of graphs. We evaluate our model on challenging datasets: THUMOS14, Charades, and EPIC-Kitchens-100. Our results show that our proposed model outperforms the state-of-the-art by a considerable margin.
MCMI: Multi-Cycle Image Translation with Mutual Information Constraints
Jul 06, 2020
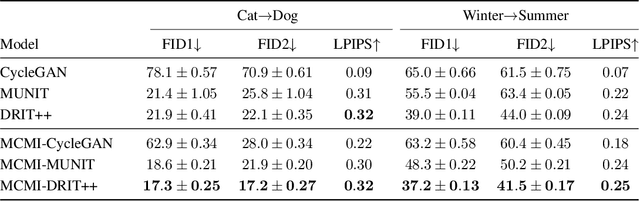

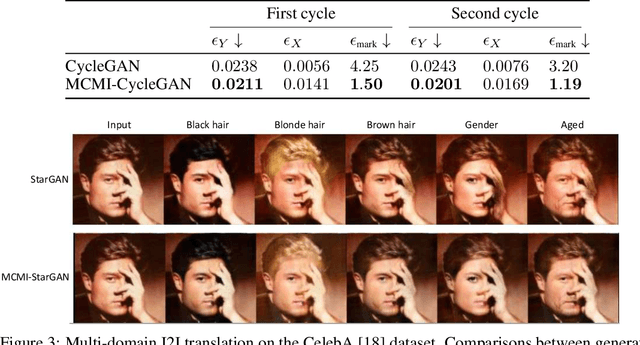
We present a mutual information-based framework for unsupervised image-to-image translation. Our MCMI approach treats single-cycle image translation models as modules that can be used recurrently in a multi-cycle translation setting where the translation process is bounded by mutual information constraints between the input and output images. The proposed mutual information constraints can improve cross-domain mappings by optimizing out translation functions that fail to satisfy the Markov property during image translations. We show that models trained with MCMI produce higher quality images and learn more semantically-relevant mappings compared to state-of-the-art image translation methods. The MCMI framework can be applied to existing unpaired image-to-image translation models with minimum modifications. Qualitative experiments and a perceptual study demonstrate the image quality improvements and generality of our approach using several backbone models and a variety of image datasets.
Zero-Shot Generation of Human-Object Interaction Videos
Dec 09, 2019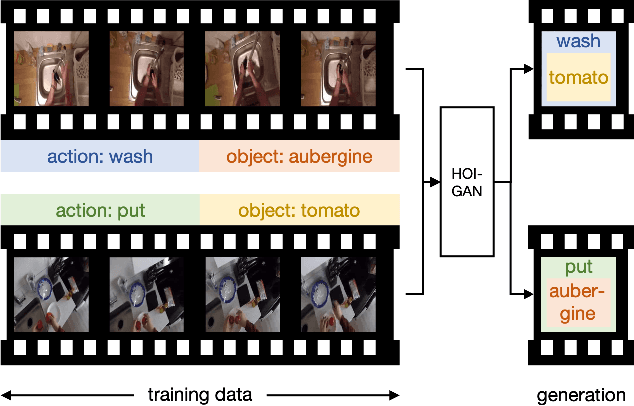
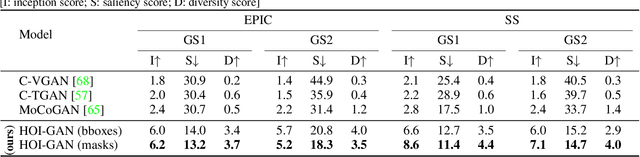
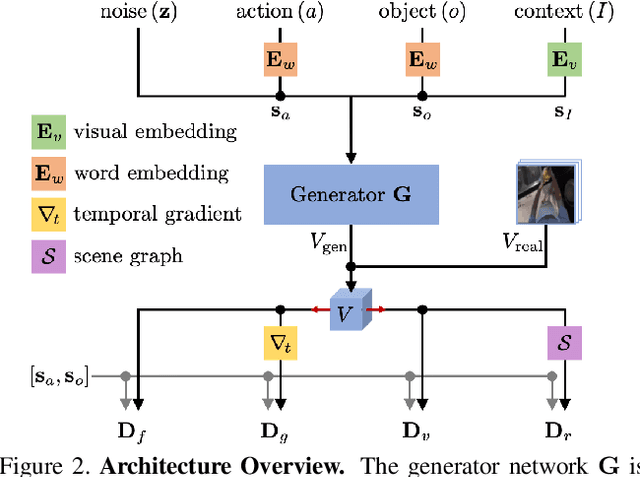
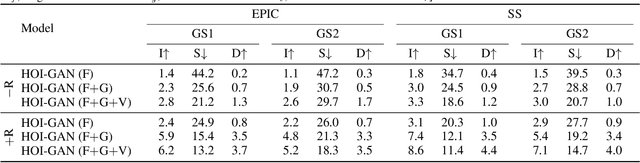
Generation of videos of complex scenes is an important open problem in computer vision research. Human activity videos are a good example of such complex scenes. Human activities are typically formed as compositions of actions applied to objects -- modeling interactions between people and the physical world are a core part of visual understanding. In this paper, we introduce the task of generating human-object interaction videos in a zero-shot compositional setting, i.e., generating videos for action-object compositions that are unseen during training, having seen the target action and target object independently. To generate human-object interaction videos, we propose a novel adversarial framework HOI-GAN which includes multiple discriminators focusing on different aspects of a video. To demonstrate the effectiveness of our proposed framework, we perform extensive quantitative and qualitative evaluation on two challenging datasets: EPIC-Kitchens and 20BN-Something-Something v2.
Lifelong GAN: Continual Learning for Conditional Image Generation
Aug 22, 2019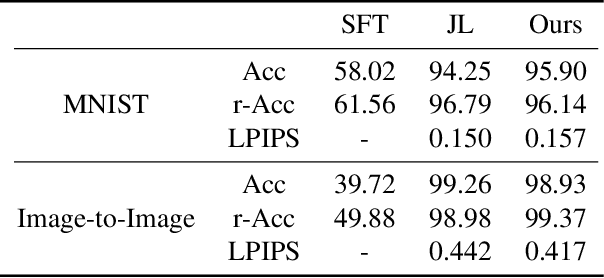
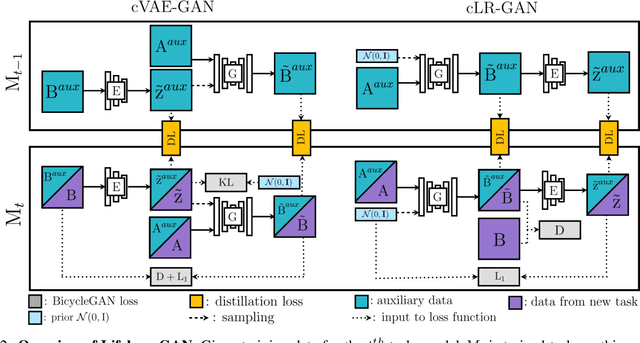
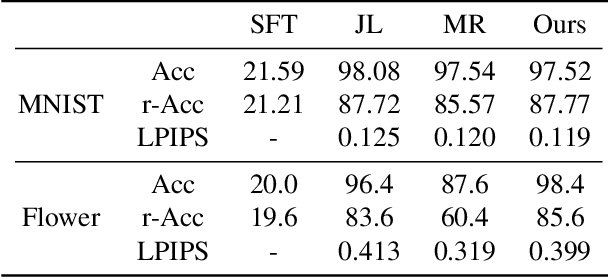

Lifelong learning is challenging for deep neural networks due to their susceptibility to catastrophic forgetting. Catastrophic forgetting occurs when a trained network is not able to maintain its ability to accomplish previously learned tasks when it is trained to perform new tasks. We study the problem of lifelong learning for generative models, extending a trained network to new conditional generation tasks without forgetting previous tasks, while assuming access to the training data for the current task only. In contrast to state-of-the-art memory replay based approaches which are limited to label-conditioned image generation tasks, a more generic framework for continual learning of generative models under different conditional image generation settings is proposed in this paper. Lifelong GAN employs knowledge distillation to transfer learned knowledge from previous networks to the new network. This makes it possible to perform image-conditioned generation tasks in a lifelong learning setting. We validate Lifelong GAN for both image-conditioned and label-conditioned generation tasks, and provide qualitative and quantitative results to show the generality and effectiveness of our method.
Continuous Graph Flow for Flexible Density Estimation
Aug 07, 2019



In this paper, we propose Continuous Graph Flow, a generative continuous flow based method that aims to model distributions of graph-structured complex data. The model is formulated as an ordinary differential equation system with shared and reusable functions that operate over the graph structure. This leads to a new type of neural graph message passing scheme that performs continuous message passing over time. This class of models offer several advantages: (1) modeling complex graphical distributions without rigid assumptions on the distributions; (2) not limited to modeling data of fixed dimensions and can generalize probability evaluation and data generation over unseen subset of variables; (3) the underlying continuous graph message passing process is reversible and memory-efficient. We demonstrate the effectiveness of our model on two generation tasks, namely, image puzzle generation, and layout generation from scene graphs. Compared to unstructured and structured latent-space VAE models, we show that our proposed model achieves significant performance improvement (up to 400% in negative log-likelihood).