 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Audio-Visual Quality Assessment Dataset via Crowdsourcing
Feb 26, 2026Audio-visual quality assessment (AVQA) research has been stalled by limitations of existing datasets: they are typically small in scale, with insufficient diversity in content and quality, and annotated only with overall scores. These shortcomings provide limited support for model development and multimodal perception research. We propose a practical approach for AVQA dataset construction. First, we design a crowdsourced subjective experiment framework for AVQA, breaks the constraints of in-lab settings and achieves reliable annotation across varied environments. Second, a systematic data preparation strategy is further employed to ensure broad coverage of both quality levels and semantic scenarios. Third, we extend the dataset with additional annotations, enabling research on multimodal perception mechanisms and their relation to content. Finally, we validate this approach through YT-NTU-AVQ, the largest and most diverse AVQA dataset to date, consisting of 1,620 user-generated audio and video (A/V) sequences. The dataset and platform code are available at https://github.com/renyu12/YT-NTU-AVQ
Contextual bandits with entropy-based human feedback
Feb 12, 2025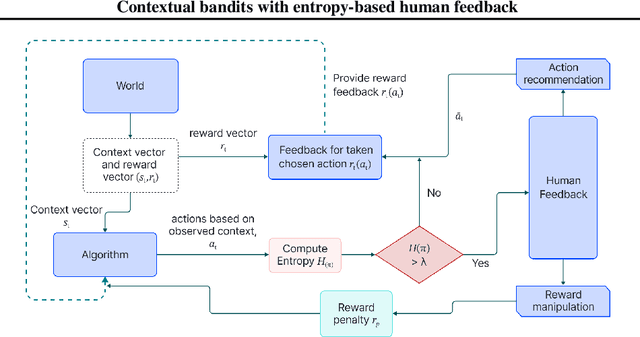
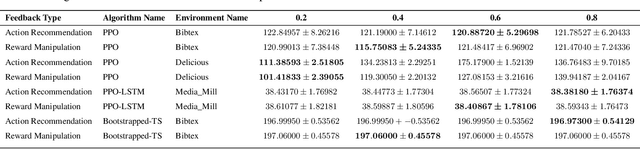
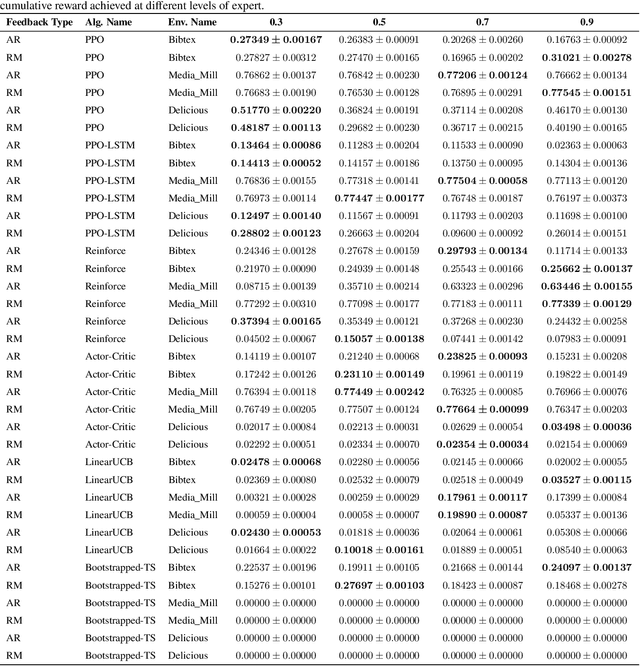
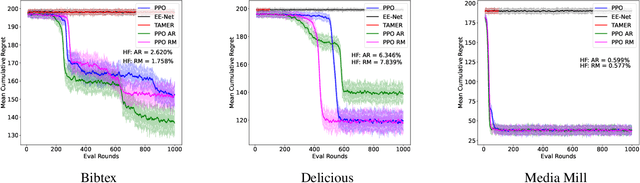
In recent years, preference-based human feedback mechanisms have become essential for enhancing model performance across diverse applications, including conversational AI systems such as ChatGPT. However, existing approaches often neglect critical aspects, such as model uncertainty and the variability in feedback quality. To address these challenges, we introduce an entropy-based human feedback framework for contextual bandits, which dynamically balances exploration and exploitation by soliciting expert feedback only when model entropy exceeds a predefined threshold. Our method is model-agnostic and can be seamlessly integrated with any contextual bandit agent employing stochastic policies. Through comprehensive experiments, we show that our approach achieves significant performance improvements while requiring minimal human feedback, even under conditions of suboptimal feedback quality. This work not only presents a novel strategy for feedback solicitation but also highlights the robustness and efficacy of incorporating human guidance into machine learning systems. Our code is publicly available: https://github.com/BorealisAI/CBHF
AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
Oct 03, 2023



Machine-based prediction of real-world events is garnering attention due to its potential for informed decision-making. Whereas traditional forecasting predominantly hinges on structured data like time-series, recent breakthroughs in language models enable predictions using unstructured text. In particular, (Zou et al., 2022) unveils AutoCast, a new benchmark that employs news articles for answering forecasting queries. Nevertheless, existing methods still trail behind human performance. The cornerstone of accurate forecasting, we argue, lies in identifying a concise, yet rich subset of news snippets from a vast corpus. With this motivation, we introduce AutoCast++, a zero-shot ranking-based context retrieval system, tailored to sift through expansive news document collections for event forecasting. Our approach first re-ranks articles based on zero-shot question-passage relevance, honing in on semantically pertinent news. Following this, the chosen articles are subjected to zero-shot summarization to attain succinct context. Leveraging a pre-trained language model, we conduct both the relevance evaluation and article summarization without needing domain-specific training. Notably, recent articles can sometimes be at odds with preceding ones due to new facts or unanticipated incidents, leading to fluctuating temporal dynamics. To tackle this, our re-ranking mechanism gives preference to more recent articles, and we further regularize the multi-passage representation learning to align with human forecaster responses made on different dates. Empirical results underscore marked improvements across multiple metrics, improving the performance for multiple-choice questions (MCQ) by 48% and true/false (TF) questions by up to 8%.
ConR: Contrastive Regularizer for Deep Imbalanced Regression
Sep 13, 2023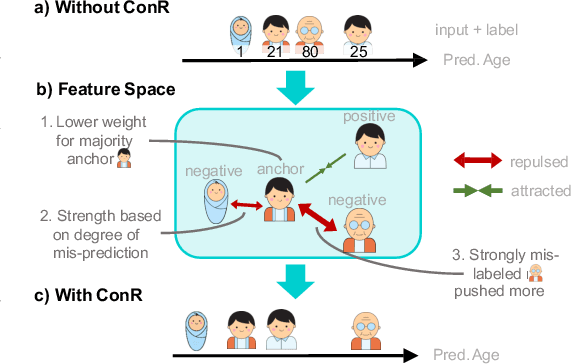
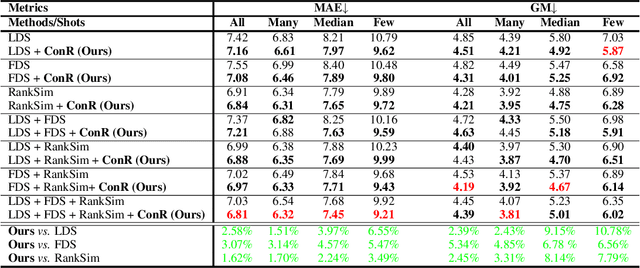
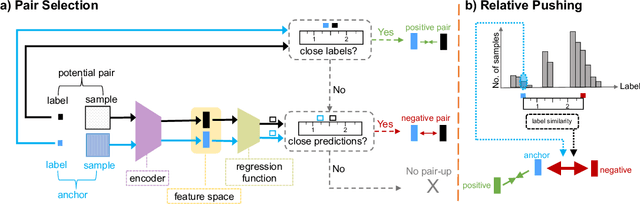

Imbalanced distributions are ubiquitous in real-world data. They create constraints on Deep Neural Networks to represent the minority labels and avoid bias towards majority labels. The extensive body of imbalanced approaches address categorical label spaces but fail to effectively extend to regression problems where the label space is continuous. Conversely, local and global correlations among continuous labels provide valuable insights towards effectively modelling relationships in feature space. In this work, we propose ConR, a contrastive regularizer that models global and local label similarities in feature space and prevents the features of minority samples from being collapsed into their majority neighbours. Serving the similarities of the predictions as an indicator of feature similarities, ConR discerns the dissagreements between the label space and feature space and imposes a penalty on these disagreements. ConR minds the continuous nature of label space with two main strategies in a contrastive manner: incorrect proximities are penalized proportionate to the label similarities and the correct ones are encouraged to model local similarities. ConR consolidates essential considerations into a generic, easy-to-integrate, and efficient method that effectively addresses deep imbalanced regression. Moreover, ConR is orthogonal to existing approaches and smoothly extends to uni- and multi-dimensional label spaces. Our comprehensive experiments show that ConR significantly boosts the performance of all the state-of-the-art methods on three large-scale deep imbalanced regression benchmarks. Our code is publicly available in https://github.com/BorealisAI/ConR.
What Constitutes Good Contrastive Learning in Time-Series Forecasting?
Jun 21, 2023
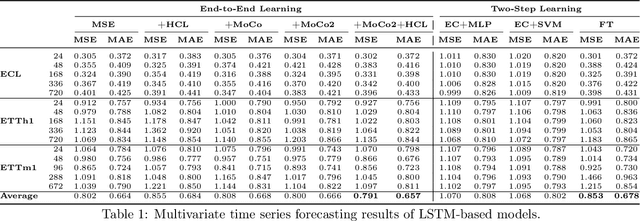

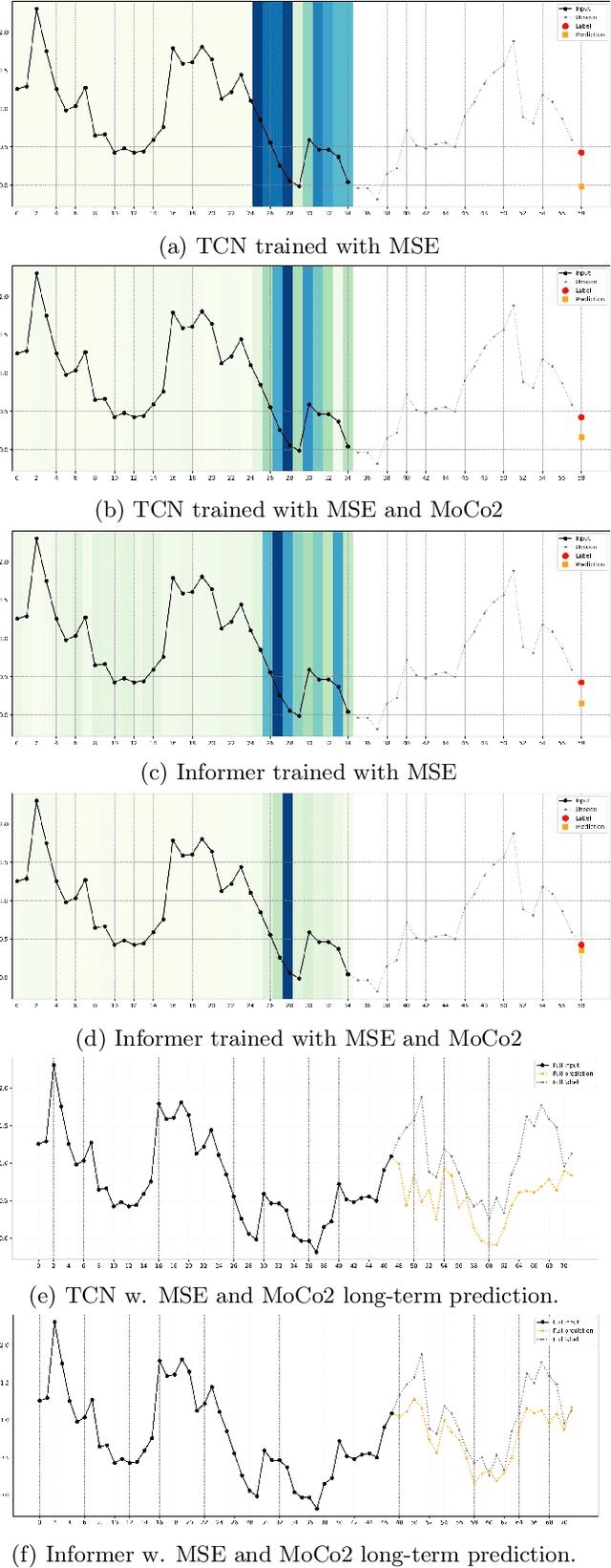
In recent years, the introduction of self-supervised contrastive learning (SSCL) has demonstrated remarkable improvements in representation learning across various domains, including natural language processing and computer vision. By leveraging the inherent benefits of self-supervision, SSCL enables the pre-training of representation models using vast amounts of unlabeled data. Despite these advances, there remains a significant gap in understanding the impact of different SSCL strategies on time series forecasting performance, as well as the specific benefits that SSCL can bring. This paper aims to address these gaps by conducting a comprehensive analysis of the effectiveness of various training variables, including different SSCL algorithms, learning strategies, model architectures, and their interplay. Additionally, to gain deeper insights into the improvements brought about by SSCL in the context of time-series forecasting, a qualitative analysis of the empirical receptive field is performed. Through our experiments, we demonstrate that the end-to-end training of a Transformer model using the Mean Squared Error (MSE) loss and SSCL emerges as the most effective approach in time series forecasting. Notably, the incorporation of the contrastive objective enables the model to prioritize more pertinent information for forecasting, such as scale and periodic relationships. These findings contribute to a better understanding of the benefits of SSCL in time series forecasting and provide valuable insights for future research in this area.
GAN-based Image Compression with Improved RDO Process
Jun 18, 2023


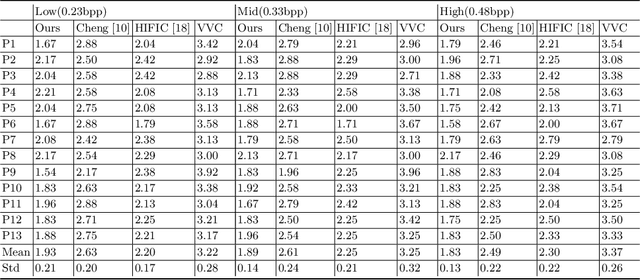
GAN-based image compression schemes have shown remarkable progress lately due to their high perceptual quality at low bit rates. However, there are two main issues, including 1) the reconstructed image perceptual degeneration in color, texture, and structure as well as 2) the inaccurate entropy model. In this paper, we present a novel GAN-based image compression approach with improved rate-distortion optimization (RDO) process. To achieve this, we utilize the DISTS and MS-SSIM metrics to measure perceptual degeneration in color, texture, and structure. Besides, we absorb the discretized gaussian-laplacian-logistic mixture model (GLLMM) for entropy modeling to improve the accuracy in estimating the probability distributions of the latent representation. During the evaluation process, instead of evaluating the perceptual quality of the reconstructed image via IQA metrics, we directly conduct the Mean Opinion Score (MOS) experiment among different codecs, which fully reflects the actual perceptual results of humans. Experimental results demonstrate that the proposed method outperforms the existing GAN-based methods and the state-of-the-art hybrid codec (i.e., VVC).
Robust Reinforcement Learning Objectives for Sequential Recommender Systems
May 30, 2023Attention-based sequential recommendation methods have demonstrated promising results by accurately capturing users' dynamic interests from historical interactions. In addition to generating superior user representations, recent studies have begun integrating reinforcement learning (RL) into these models. Framing sequential recommendation as an RL problem with reward signals, unlocks developing recommender systems (RS) that consider a vital aspect-incorporating direct user feedback in the form of rewards to deliver a more personalized experience. Nonetheless, employing RL algorithms presents challenges, including off-policy training, expansive combinatorial action spaces, and the scarcity of datasets with sufficient reward signals. Contemporary approaches have attempted to combine RL and sequential modeling, incorporating contrastive-based objectives and negative sampling strategies for training the RL component. In this study, we further emphasize the efficacy of contrastive-based objectives paired with augmentation to address datasets with extended horizons. Additionally, we recognize the potential instability issues that may arise during the application of negative sampling. These challenges primarily stem from the data imbalance prevalent in real-world datasets, which is a common issue in offline RL contexts. While our established baselines attempt to mitigate this through various techniques, instability remains an issue. Therefore, we introduce an enhanced methodology aimed at providing a more effective solution to these challenges.
JND-Based Perceptual Optimization For Learned Image Compression
Mar 08, 2023Recently, learned image compression schemes have achieved remarkable improvements in image fidelity (e.g., PSNR and MS-SSIM) compared to conventional hybrid image coding ones due to their high-efficiency non-linear transform, end-to-end optimization frameworks, etc. However, few of them take the Just Noticeable Difference (JND) characteristic of the Human Visual System (HVS) into account and optimize learned image compression towards perceptual quality. To address this issue, a JND-based perceptual quality loss is proposed. Considering that the amounts of distortion in the compressed image at different training epochs under different Quantization Parameters (QPs) are different, we develop a distortion-aware adjustor. After combining them together, we can better assign the distortion in the compressed image with the guidance of JND to preserve the high perceptual quality. All these designs enable the proposed method to be flexibly applied to various learned image compression schemes with high scalability and plug-and-play advantages. Experimental results on the Kodak dataset demonstrate that the proposed method has led to better perceptual quality than the baseline model under the same bit rate.
HVS-Inspired Signal Degradation Network for Just Noticeable Difference Estimation
Aug 16, 2022
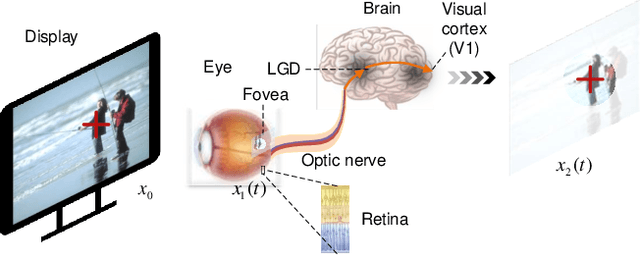
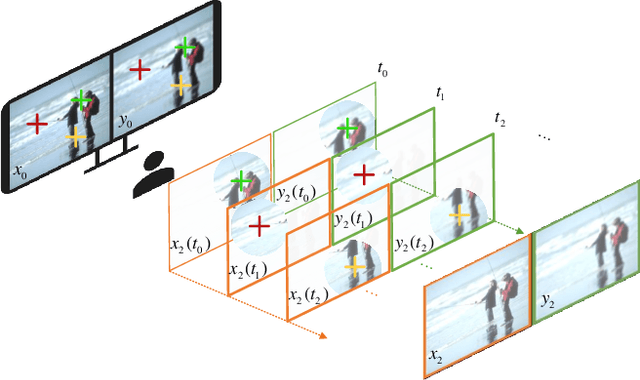
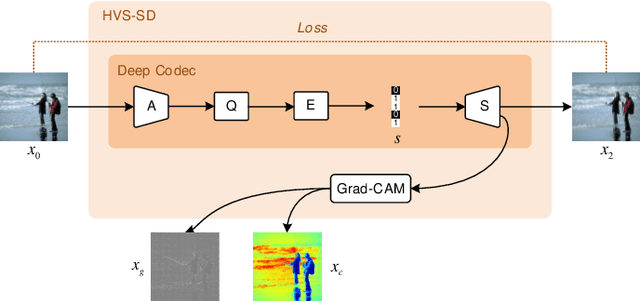
Significant improvement has been made on just noticeable difference (JND) modelling due to the development of deep neural networks, especially for the recently developed unsupervised-JND generation models. However, they have a major drawback that the generated JND is assessed in the real-world signal domain instead of in the perceptual domain in the human brain. There is an obvious difference when JND is assessed in such two domains since the visual signal in the real world is encoded before it is delivered into the brain with the human visual system (HVS). Hence, we propose an HVS-inspired signal degradation network for JND estimation. To achieve this, we carefully analyze the HVS perceptual process in JND subjective viewing to obtain relevant insights, and then design an HVS-inspired signal degradation (HVS-SD) network to represent the signal degradation in the HVS. On the one hand, the well learnt HVS-SD enables us to assess the JND in the perceptual domain. On the other hand, it provides more accurate prior information for better guiding JND generation. Additionally, considering the requirement that reasonable JND should not lead to visual attention shifting, a visual attention loss is proposed to control JND generation. Experimental results demonstrate that the proposed method achieves the SOTA performance for accurately estimating the redundancy of the HVS. Source code will be available at https://github.com/jianjin008/HVS-SD-JND.
Scaleformer: Iterative Multi-scale Refining Transformers for Time Series Forecasting
Jun 08, 2022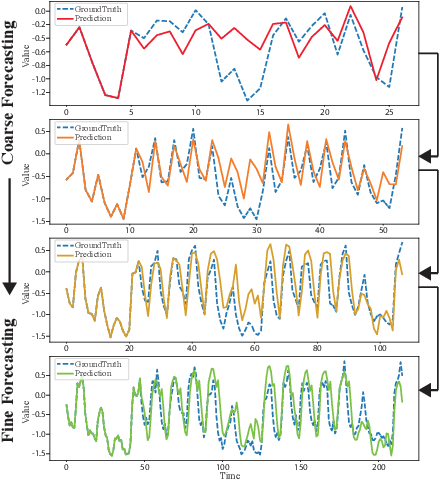
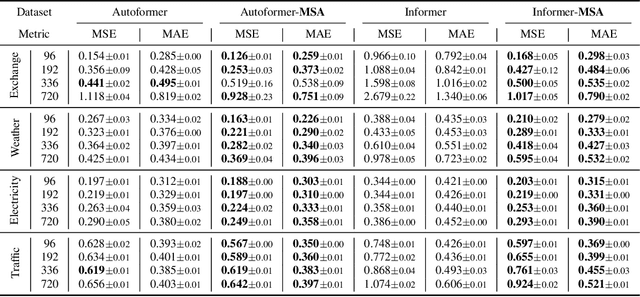
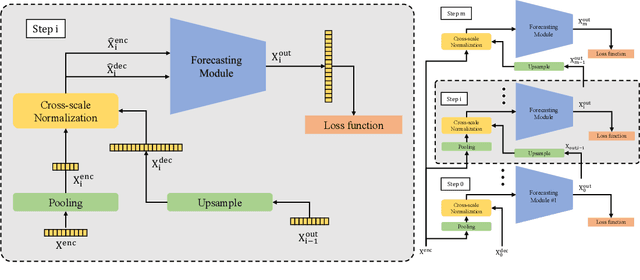
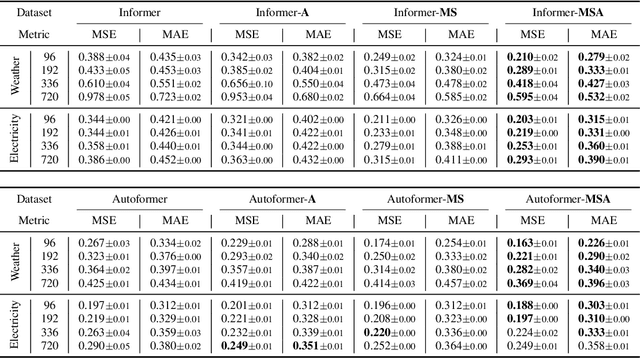
The performance of time series forecasting has recently been greatly improved by the introduction of transformers. In this paper, we propose a general multi-scale framework that can be applied to state-of-the-art transformer-based time series forecasting models including Autoformer and Informer. Using iteratively refining a forecasted time series at multiple scales with shared weights, architecture adaptations and a specially-designed normalization scheme, we are able to achieve significant performance improvements with minimal additional computational overhead. Via detailed ablation studies, we demonstrate the effectiveness of our proposed architectural and methodological innovations. Furthermore, our experiments on four public datasets show that the proposed multi-scale framework outperforms the corresponding baselines with an average improvement of 13% and 38% over Autoformer and Informer, respectively.