 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual bandits with entropy-based human feedback
Paper and Code
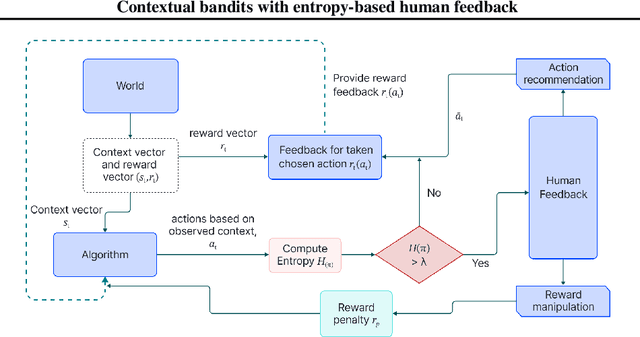
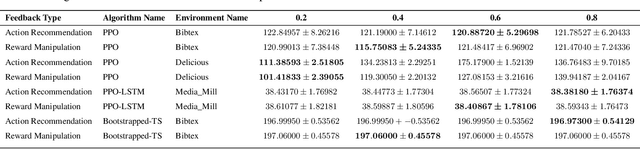
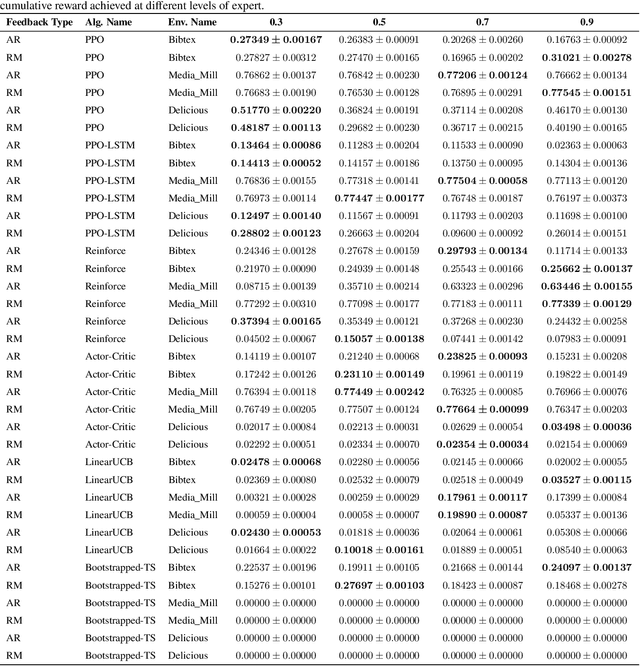
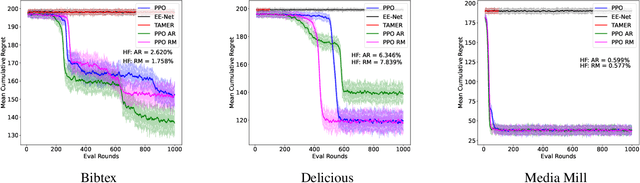
In recent years, preference-based human feedback mechanisms have become essential for enhancing model performance across diverse applications, including conversational AI systems such as ChatGPT. However, existing approaches often neglect critical aspects, such as model uncertainty and the variability in feedback quality. To address these challenges, we introduce an entropy-based human feedback framework for contextual bandits, which dynamically balances exploration and exploitation by soliciting expert feedback only when model entropy exceeds a predefined threshold. Our method is model-agnostic and can be seamlessly integrated with any contextual bandit agent employing stochastic policies. Through comprehensive experiments, we show that our approach achieves significant performance improvements while requiring minimal human feedback, even under conditions of suboptimal feedback quality. This work not only presents a novel strategy for feedback solicitation but also highlights the robustness and efficacy of incorporating human guidance into machine learning systems. Our code is publicly available: https://github.com/BorealisAI/CBHF