 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Overcomplicating Selective Classification: Use Max-Logit
Jun 17, 2022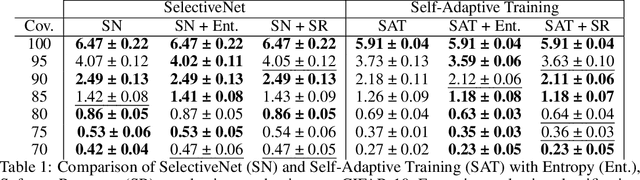
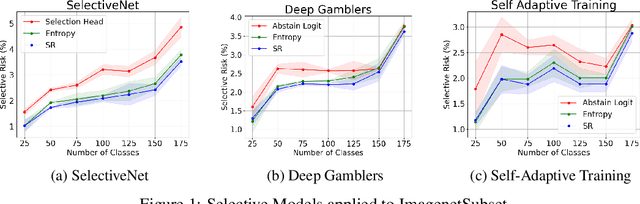
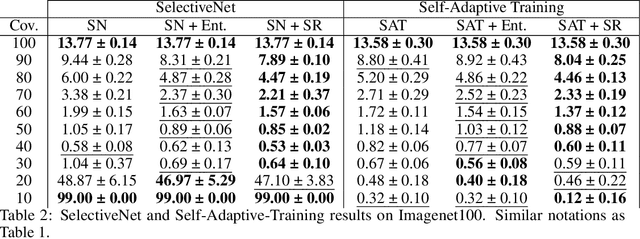
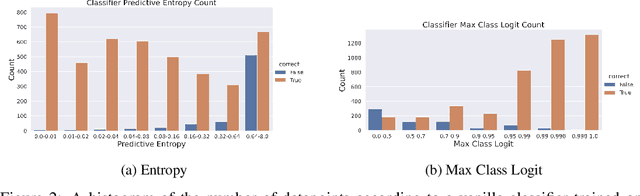
We tackle the problem of Selective Classification where the goal is to achieve the best performance on the desired coverages of the dataset. Recent state-of-the-art selective methods come with architectural changes either via introducing a separate selection head or an extra abstention logit. In this paper, we present surprising results for Selective Classification by confirming that the superior performance of state-of-the-art methods is owed to training a more generalizable classifier; however, their selection mechanism is suboptimal. We argue that the selection mechanism should be rooted in the objective function instead of a separately calculated score. Accordingly, in this paper, we motivate an alternative selection strategy that is based on the cross entropy loss for the classification settings, namely, max of the logits. Our proposed selection strategy achieves better results by a significant margin, consistently, across all coverages and all datasets, without any additional computation. Finally, inspired by our superior selection mechanism, we propose to further regularize the objective function with entropy-minimization. Our proposed max-logit selection with the modified loss function achieves new state-of-the-art results for Selective Classification.
Scaleformer: Iterative Multi-scale Refining Transformers for Time Series Forecasting
Jun 08, 2022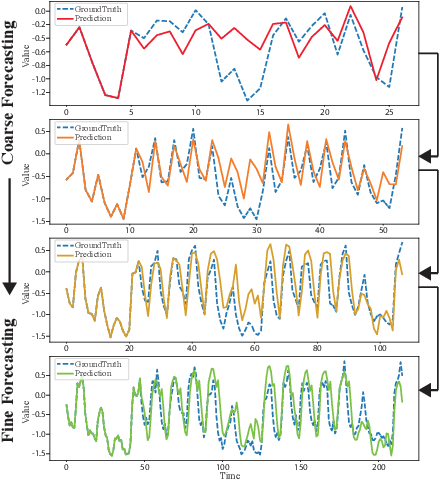
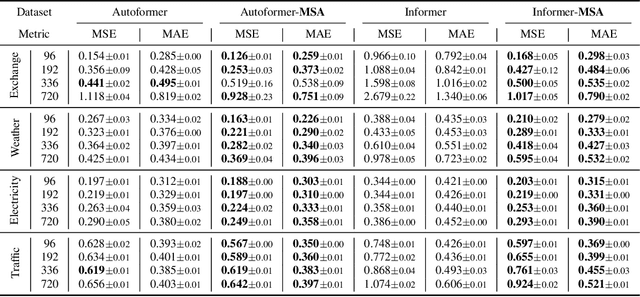
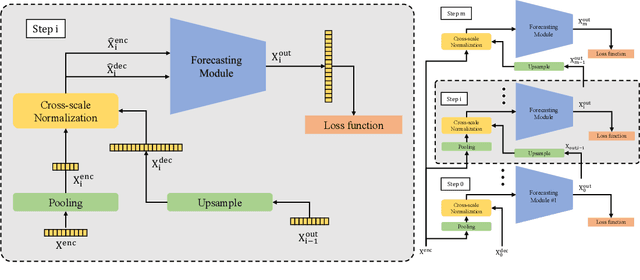
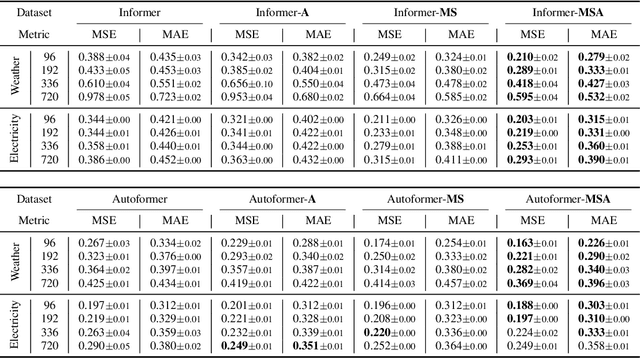
The performance of time series forecasting has recently been greatly improved by the introduction of transformers. In this paper, we propose a general multi-scale framework that can be applied to state-of-the-art transformer-based time series forecasting models including Autoformer and Informer. Using iteratively refining a forecasted time series at multiple scales with shared weights, architecture adaptations and a specially-designed normalization scheme, we are able to achieve significant performance improvements with minimal additional computational overhead. Via detailed ablation studies, we demonstrate the effectiveness of our proposed architectural and methodological innovations. Furthermore, our experiments on four public datasets show that the proposed multi-scale framework outperforms the corresponding baselines with an average improvement of 13% and 38% over Autoformer and Informer, respectively.
On Modelling Label Uncertainty in Deep Neural Networks: Automatic Estimation of Intra-observer Variability in 2D Echocardiography Quality Assessment
Nov 02, 2019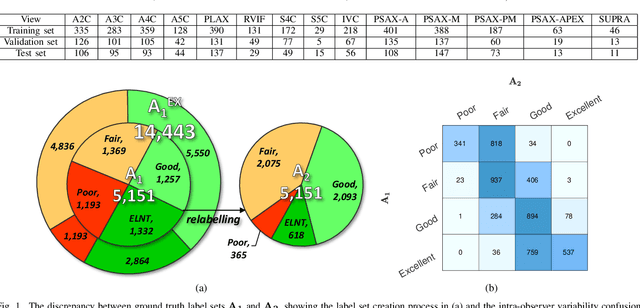
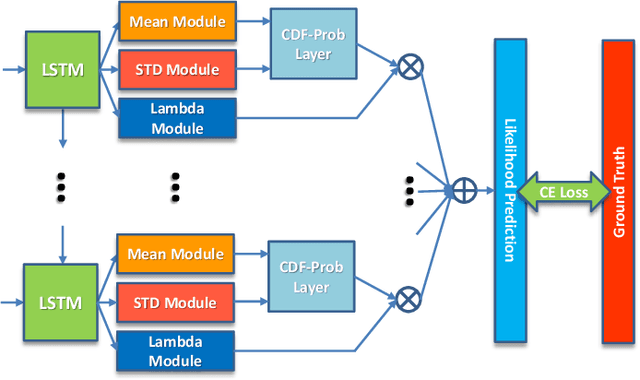
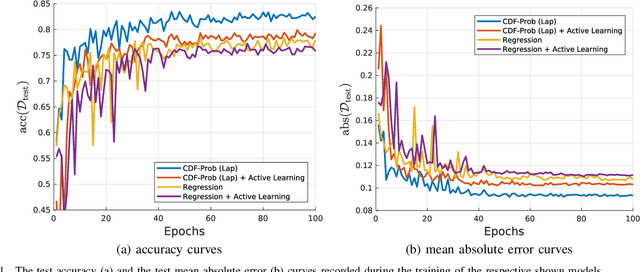
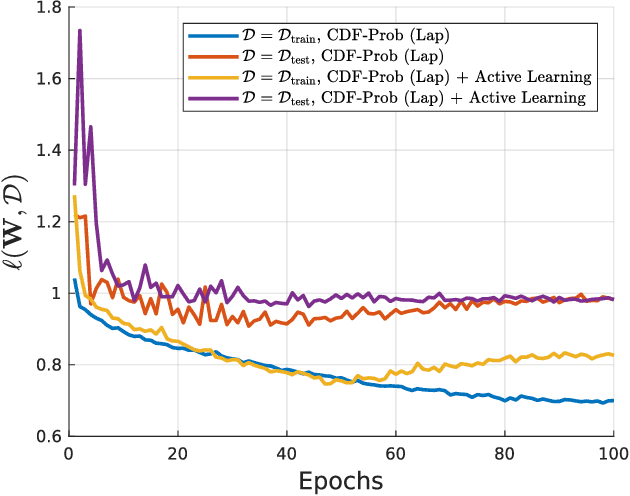
Uncertainty of labels in clinical data resulting from intra-observer variability can have direct impact on the reliability of assessments made by deep neural networks. In this paper, we propose a method for modelling such uncertainty in the context of 2D echocardiography (echo), which is a routine procedure for detecting cardiovascular disease at point-of-care. Echo imaging quality and acquisition time is highly dependent on the operator's experience level. Recent developments have shown the possibility of automating echo image quality quantification by mapping an expert's assessment of quality to the echo image via deep learning techniques. Nevertheless, the observer variability in the expert's assessment can impact the quality quantification accuracy. Here, we aim to model the intra-observer variability in echo quality assessment as an aleatoric uncertainty modelling regression problem with the introduction of a novel method that handles the regression problem with categorical labels. A key feature of our design is that only a single forward pass is sufficient to estimate the level of uncertainty for the network output. Compared to the $0.11 \pm 0.09$ absolute error (in a scale from 0 to 1) archived by the conventional regression method, the proposed method brings the error down to $0.09 \pm 0.08$, where the improvement is statistically significant and equivalents to $5.7\%$ test accuracy improvement. The simplicity of the proposed approach means that it could be generalized to other applications of deep learning in medical imaging, where there is often uncertainty in clinical labels.