 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Overcomplicating Selective Classification: Use Max-Logit
Paper and Code
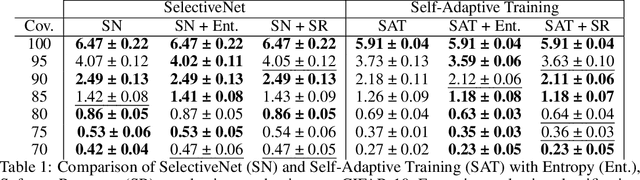
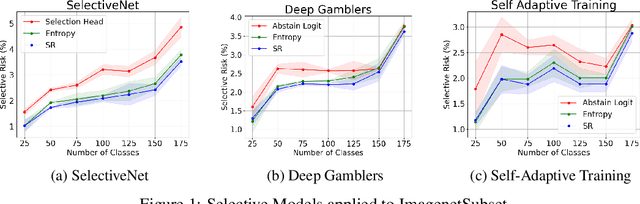
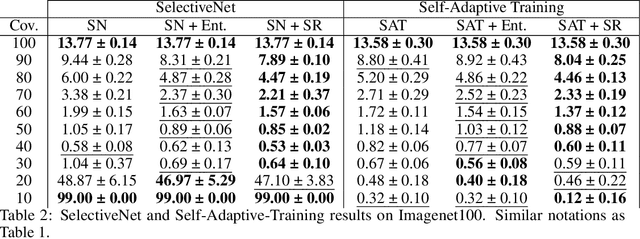
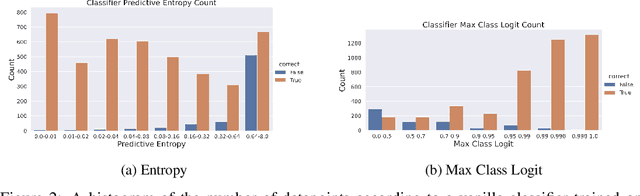
We tackle the problem of Selective Classification where the goal is to achieve the best performance on the desired coverages of the dataset. Recent state-of-the-art selective methods come with architectural changes either via introducing a separate selection head or an extra abstention logit. In this paper, we present surprising results for Selective Classification by confirming that the superior performance of state-of-the-art methods is owed to training a more generalizable classifier; however, their selection mechanism is suboptimal. We argue that the selection mechanism should be rooted in the objective function instead of a separately calculated score. Accordingly, in this paper, we motivate an alternative selection strategy that is based on the cross entropy loss for the classification settings, namely, max of the logits. Our proposed selection strategy achieves better results by a significant margin, consistently, across all coverages and all datasets, without any additional computation. Finally, inspired by our superior selection mechanism, we propose to further regularize the objective function with entropy-minimization. Our proposed max-logit selection with the modified loss function achieves new state-of-the-art results for Selective Classification.