 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSO-DETR: Leveraging Dual-Domain Features and Knowledge Distillation for Small Object Detection
Apr 11, 2025



Detection Transformer-based methods have achieved significant advancements in general object detection. However, challenges remain in effectively detecting small objects. One key difficulty is that existing encoders struggle to efficiently fuse low-level features. Additionally, the query selection strategies are not effectively tailored for small objects. To address these challenges, this paper proposes an efficient model, Small Object Detection Transformer (SO-DETR). The model comprises three key components: a dual-domain hybrid encoder, an enhanced query selection mechanism, and a knowledge distillation strategy. The dual-domain hybrid encoder integrates spatial and frequency domains to fuse multi-scale features effectively. This approach enhances the representation of high-resolution features while maintaining relatively low computational overhead. The enhanced query selection mechanism optimizes query initialization by dynamically selecting high-scoring anchor boxes using expanded IoU, thereby improving the allocation of query resources. Furthermore, by incorporating a lightweight backbone network and implementing a knowledge distillation strategy, we develop an efficient detector for small objects. Experimental results on the VisDrone-2019-DET and UAVVaste datasets demonstrate that SO-DETR outperforms existing methods with similar computational demands. The project page is available at https://github.com/ValiantDiligent/SO_DETR.
Concept-Aware Latent and Explicit Knowledge Integration for Enhanced Cognitive Diagnosis
Feb 04, 2025



Cognitive diagnosis can infer the students' mastery of specific knowledge concepts based on historical response logs. However, the existing cognitive diagnostic models (CDMs) represent students' proficiency via a unidimensional perspective, which can't assess the students' mastery on each knowledge concept comprehensively. Moreover, the Q-matrix binarizes the relationship between exercises and knowledge concepts, and it can't represent the latent relationship between exercises and knowledge concepts. Especially, when the granularity of knowledge attributes refines increasingly, the Q-matrix becomes incomplete correspondingly and the sparse binary representation (0/1) fails to capture the intricate relationships among knowledge concepts. To address these issues, we propose a Concept-aware Latent and Explicit Knowledge Integration model for cognitive diagnosis (CLEKI-CD). Specifically, a multidimensional vector is constructed according to the students' mastery and exercise difficulty for each knowledge concept from multiple perspectives, which enhances the representation capabilities of the model. Moreover, a latent Q-matrix is generated by our proposed attention-based knowledge aggregation method, and it can uncover the coverage degree of exercises over latent knowledge. The latent Q-matrix can supplement the sparse explicit Q-matrix with the inherent relationships among knowledge concepts, and mitigate the knowledge coverage problem. Furthermore, we employ a combined cognitive diagnosis layer to integrate both latent and explicit knowledge, further enhancing cognitive diagnosis performance. Extensive experiments on real-world datasets demonstrate that CLEKI-CD outperforms the state-of-the-art models. The proposed CLEKI-CD is promising in practical applications in the field of intelligent education, as it exhibits good interpretability with diagnostic results.
HFGCN:Hypergraph Fusion Graph Convolutional Networks for Skeleton-Based Action Recognition
Jan 19, 2025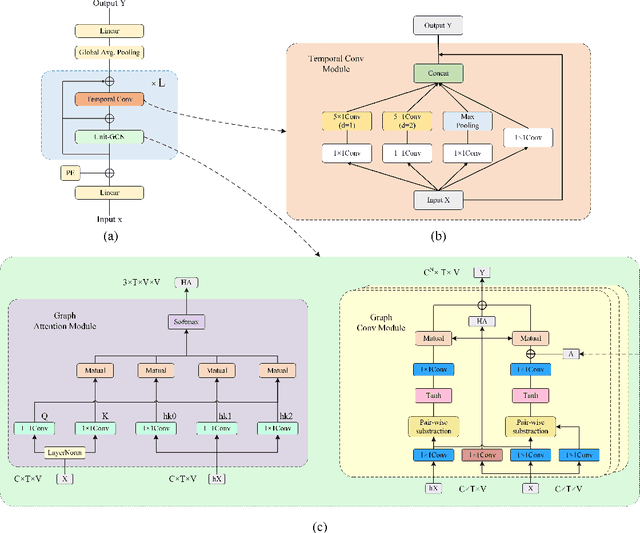
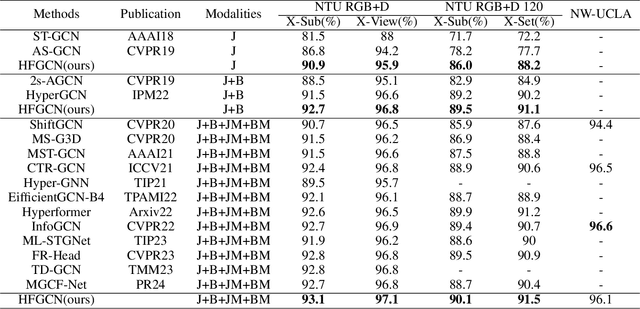
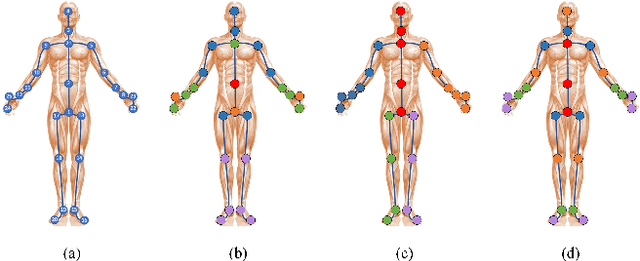
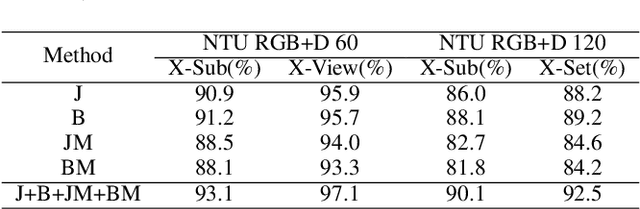
In recent years, action recognition has received much attention and wide application due to its important role in video understanding. Most of the researches on action recognition methods focused on improving the performance via various deep learning methods rather than the classification of skeleton points. The topological modeling between skeleton points and body parts was seldom considered. Although some studies have used a data-driven approach to classify the topology of the skeleton point, the nature of the skeleton point in terms of kinematics has not been taken into consideration. Therefore, in this paper, we draw on the theory of kinematics to adapt the topological relations of the skeleton point and propose a topological relation classification based on body parts and distance from core of body. To synthesize these topological relations for action recognition, we propose a novel Hypergraph Fusion Graph Convolutional Network (HFGCN). In particular, the proposed model is able to focus on the human skeleton points and the different body parts simultaneously, and thus construct the topology, which improves the recognition accuracy obviously. We use a hypergraph to represent the categorical relationships of these skeleton points and incorporate the hypergraph into a graph convolution network to model the higher-order relationships among the skeleton points and enhance the feature representation of the network. In addition, our proposed hypergraph attention module and hypergraph graph convolution module optimize topology modeling in temporal and channel dimensions, respectively, to further enhance the feature representation of the network. We conducted extensive experiments on three widely used datasets.The results validate that our proposed method can achieve the best performance when compared with the state-of-the-art skeleton-based methods.
UAV-DETR: Efficient End-to-End Object Detection for Unmanned Aerial Vehicle Imagery
Jan 03, 2025



Unmanned aerial vehicle object detection (UAV-OD) has been widely used in various scenarios. However, most existing UAV-OD algorithms rely on manually designed components, which require extensive tuning. End-to-end models that do not depend on such manually designed components are mainly designed for natural images, which are less effective for UAV imagery. To address such challenges, this paper proposes an efficient detection transformer (DETR) framework tailored for UAV imagery, i.e., UAV-DETR. The framework includes a multi-scale feature fusion with frequency enhancement module, which captures both spatial and frequency information at different scales. In addition, a frequency-focused down-sampling module is presented to retain critical spatial details during down-sampling. A semantic alignment and calibration module is developed to align and fuse features from different fusion paths. Experimental results demonstrate the effectiveness and generalization of our approach across various UAV imagery datasets. On the VisDrone dataset, our method improves AP by 3.1\% and $\text{AP}_{50}$ by 4.2\% over the baseline. Similar enhancements are observed on the UAVVaste dataset. The project page: https://github.com/ValiantDiligent/UAV-DETR
ReplanVLM: Replanning Robotic Tasks with Visual Language Models
Jul 31, 2024Large language models (LLMs) have gained increasing popularity in robotic task planning due to their exceptional abilities in text analytics and generation, as well as their broad knowledge of the world. However, they fall short in decoding visual cues. LLMs have limited direct perception of the world, which leads to a deficient grasp of the current state of the world. By contrast, the emergence of visual language models (VLMs) fills this gap by integrating visual perception modules, which can enhance the autonomy of robotic task planning. Despite these advancements, VLMs still face challenges, such as the potential for task execution errors, even when provided with accurate instructions. To address such issues, this paper proposes a ReplanVLM framework for robotic task planning. In this study, we focus on error correction interventions. An internal error correction mechanism and an external error correction mechanism are presented to correct errors under corresponding phases. A replan strategy is developed to replan tasks or correct error codes when task execution fails. Experimental results on real robots and in simulation environments have demonstrated the superiority of the proposed framework, with higher success rates and robust error correction capabilities in open-world tasks. Videos of our experiments are available at https://youtu.be/NPk2pWKazJc.
InsightSee: Advancing Multi-agent Vision-Language Models for Enhanced Visual Understanding
May 31, 2024Accurate visual understanding is imperative for advancing autonomous systems and intelligent robots. Despite the powerful capabilities of vision-language models (VLMs) in processing complex visual scenes, precisely recognizing obscured or ambiguously presented visual elements remains challenging. To tackle such issues, this paper proposes InsightSee, a multi-agent framework to enhance VLMs' interpretative capabilities in handling complex visual understanding scenarios. The framework comprises a description agent, two reasoning agents, and a decision agent, which are integrated to refine the process of visual information interpretation. The design of these agents and the mechanisms by which they can be enhanced in visual information processing are presented. Experimental results demonstrate that the InsightSee framework not only boosts performance on specific visual tasks but also retains the original models' strength. The proposed framework outperforms state-of-the-art algorithms in 6 out of 9 benchmark tests, with a substantial advancement in multimodal understanding.
GAN-based Image Compression with Improved RDO Process
Jun 18, 2023


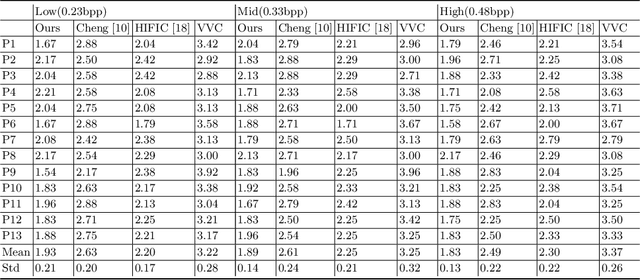
GAN-based image compression schemes have shown remarkable progress lately due to their high perceptual quality at low bit rates. However, there are two main issues, including 1) the reconstructed image perceptual degeneration in color, texture, and structure as well as 2) the inaccurate entropy model. In this paper, we present a novel GAN-based image compression approach with improved rate-distortion optimization (RDO) process. To achieve this, we utilize the DISTS and MS-SSIM metrics to measure perceptual degeneration in color, texture, and structure. Besides, we absorb the discretized gaussian-laplacian-logistic mixture model (GLLMM) for entropy modeling to improve the accuracy in estimating the probability distributions of the latent representation. During the evaluation process, instead of evaluating the perceptual quality of the reconstructed image via IQA metrics, we directly conduct the Mean Opinion Score (MOS) experiment among different codecs, which fully reflects the actual perceptual results of humans. Experimental results demonstrate that the proposed method outperforms the existing GAN-based methods and the state-of-the-art hybrid codec (i.e., VVC).
Full RGB Just Noticeable Difference (JND) Modelling
Mar 01, 2022



Just Noticeable Difference (JND) has many applications in multimedia signal processing, especially for visual data processing up to date. It's generally defined as the minimum visual content changes that the human can perspective, which has been studied for decades. However, most of the existing methods only focus on the luminance component of JND modelling and simply regard chrominance components as scaled versions of luminance. In this paper, we propose a JND model to generate the JND by taking the characteristics of full RGB channels into account, termed as the RGB-JND. To this end, an RGB-JND-NET is proposed, where the visual content in full RGB channels is used to extract features for JND generation. To supervise the JND generation, an adaptive image quality assessment combination (AIC) is developed. Besides, the RDB-JND-NET also takes the visual attention into account by automatically mining the underlying relationship between visual attention and the JND, which is further used to constrain the JND spatial distribution. To the best of our knowledge, this is the first work on careful investigation of JND modelling for full-color space. Experimental results demonstrate that the RGB-JND-NET model outperforms the relevant state-of-the-art JND models. Besides, the JND of the red and blue channels are larger than that of the green one according to the experimental results of the proposed model, which demonstrates that more changes can be tolerated in the red and blue channels, in line with the well-known fact that the human visual system is more sensitive to the green channel in comparison with the red and blue ones.
Auto-Weighted Layer Representation Based View Synthesis Distortion Estimation for 3-D Video Coding
Jan 07, 2022



Recently, various view synthesis distortion estimation models have been studied to better serve for 3-D video coding. However, they can hardly model the relationship quantitatively among different levels of depth changes, texture degeneration, and the view synthesis distortion (VSD), which is crucial for rate-distortion optimization and rate allocation. In this paper, an auto-weighted layer representation based view synthesis distortion estimation model is developed. Firstly, the sub-VSD (S-VSD) is defined according to the level of depth changes and their associated texture degeneration. After that, a set of theoretical derivations demonstrate that the VSD can be approximately decomposed into the S-VSDs multiplied by their associated weights. To obtain the S-VSDs, a layer-based representation of S-VSD is developed, where all the pixels with the same level of depth changes are represented with a layer to enable efficient S-VSD calculation at the layer level. Meanwhile, a nonlinear mapping function is learnt to accurately represent the relationship between the VSD and S-VSDs, automatically providing weights for S-VSDs during the VSD estimation. To learn such function, a dataset of VSD and its associated S-VSDs are built. Experimental results show that the VSD can be accurately estimated with the weights learnt by the nonlinear mapping function once its associated S-VSDs are available. The proposed method outperforms the relevant state-of-the-art methods in both accuracy and efficiency. The dataset and source code of the proposed method will be available at https://github.com/jianjin008/.
A New Image Codec Paradigm for Human and Machine Uses
Dec 19, 2021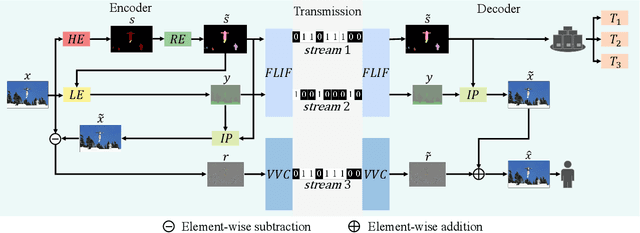
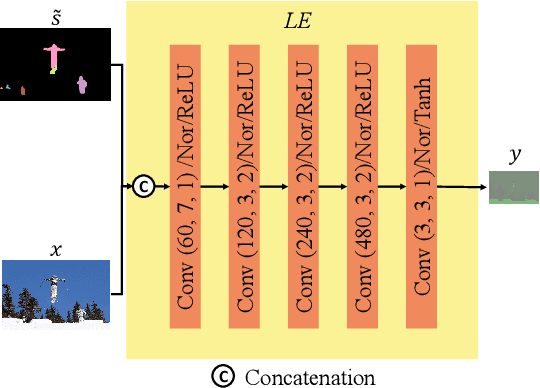
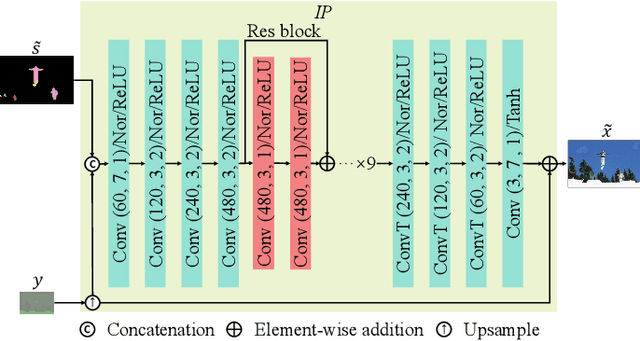
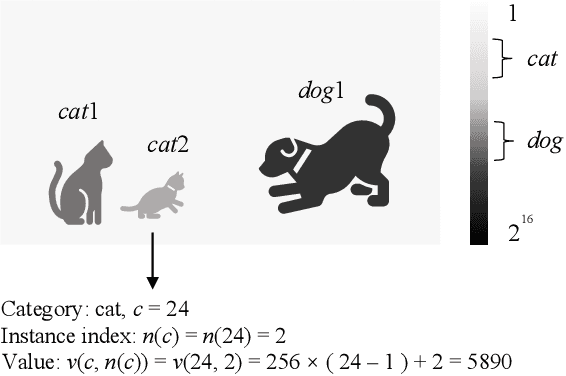
With the AI of Things (AIoT) development, a huge amount of visual data, e.g., images and videos, are produced in our daily work and life. These visual data are not only used for human viewing or understanding but also for machine analysis or decision-making, e.g., intelligent surveillance, automated vehicles, and many other smart city applications. To this end, a new image codec paradigm for both human and machine uses is proposed in this work. Firstly, the high-level instance segmentation map and the low-level signal features are extracted with neural networks. Then, the instance segmentation map is further represented as a profile with the proposed 16-bit gray-scale representation. After that, both 16-bit gray-scale profile and signal features are encoded with a lossless codec. Meanwhile, an image predictor is designed and trained to achieve the general-quality image reconstruction with the 16-bit gray-scale profile and signal features. Finally, the residual map between the original image and the predicted one is compressed with a lossy codec, used for high-quality image reconstruction. With such designs, on the one hand, we can achieve scalable image compression to meet the requirements of different human consumption; on the other hand, we can directly achieve several machine vision tasks at the decoder side with the decoded 16-bit gray-scale profile, e.g., object classification, detection, and segmentation. Experimental results show that the proposed codec achieves comparable results as most learning-based codecs and outperforms the traditional codecs (e.g., BPG and JPEG2000) in terms of PSNR and MS-SSIM for image reconstruction. At the same time, it outperforms the existing codecs in terms of the mAP for object detection and segmentation.