 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Spatial Decouple before Act: Disentangled Representation Learning for Multimodal Sentiment Analysis
Jan 20, 2026Multimodal Sentiment Analysis integrates Linguistic, Visual, and Acoustic. Mainstream approaches based on modality-invariant and modality-specific factorization or on complex fusion still rely on spatiotemporal mixed modeling. This ignores spatiotemporal heterogeneity, leading to spatiotemporal information asymmetry and thus limited performance. Hence, we propose TSDA, Temporal-Spatial Decouple before Act, which explicitly decouples each modality into temporal dynamics and spatial structural context before any interaction. For every modality, a temporal encoder and a spatial encoder project signals into separate temporal and spatial body. Factor-Consistent Cross-Modal Alignment then aligns temporal features only with their temporal counterparts across modalities, and spatial features only with their spatial counterparts. Factor specific supervision and decorrelation regularization reduce cross factor leakage while preserving complementarity. A Gated Recouple module subsequently recouples the aligned streams for task. Extensive experiments show that TSDA outperforms baselines. Ablation analysis studies confirm the necessity and interpretability of the design.
Pheromone-Focused Ant Colony Optimization algorithm for path planning
Jan 12, 2026Ant Colony Optimization (ACO) is a prominent swarm intelligence algorithm extensively applied to path planning. However, traditional ACO methods often exhibit shortcomings, such as blind search behavior and slow convergence within complex environments. To address these challenges, this paper proposes the Pheromone-Focused Ant Colony Optimization (PFACO) algorithm, which introduces three key strategies to enhance the problem-solving ability of the ant colony. First, the initial pheromone distribution is concentrated in more promising regions based on the Euclidean distances of nodes to the start and end points, balancing the trade-off between exploration and exploitation. Second, promising solutions are reinforced during colony iterations to intensify pheromone deposition along high-quality paths, accelerating convergence while maintaining solution diversity. Third, a forward-looking mechanism is implemented to penalize redundant path turns, promoting smoother and more efficient solutions. These strategies collectively produce the focused pheromones to guide the ant colony's search, which enhances the global optimization capabilities of the PFACO algorithm, significantly improving convergence speed and solution quality across diverse optimization problems. The experimental results demonstrate that PFACO consistently outperforms comparative ACO algorithms in terms of convergence speed and solution quality.
Resolving State Ambiguity in Robot Manipulation via Adaptive Working Memory Recoding
Dec 31, 2025State ambiguity is common in robotic manipulation. Identical observations may correspond to multiple valid behavior trajectories. The visuomotor policy must correctly extract the appropriate types and levels of information from the history to identify the current task phase. However, naively extending the history window is computationally expensive and may cause severe overfitting. Inspired by the continuous nature of human reasoning and the recoding of working memory, we introduce PAM, a novel visuomotor Policy equipped with Adaptive working Memory. With minimal additional training cost in a two-stage manner, PAM supports a 300-frame history window while maintaining high inference speed. Specifically, a hierarchical frame feature extractor yields two distinct representations for motion primitives and temporal disambiguation. For compact representation, a context router with range-specific queries is employed to produce compact context features across multiple history lengths. And an auxiliary objective of reconstructing historical information is introduced to ensure that the context router acts as an effective bottleneck. We meticulously design 7 tasks and verify that PAM can handle multiple scenarios of state ambiguity simultaneously. With a history window of approximately 10 seconds, PAM still supports stable training and maintains inference speeds above 20Hz. Project website: https://tinda24.github.io/pam/
LMPOcc: 3D Semantic Occupancy Prediction Utilizing Long-Term Memory Prior from Historical Traversals
Apr 18, 2025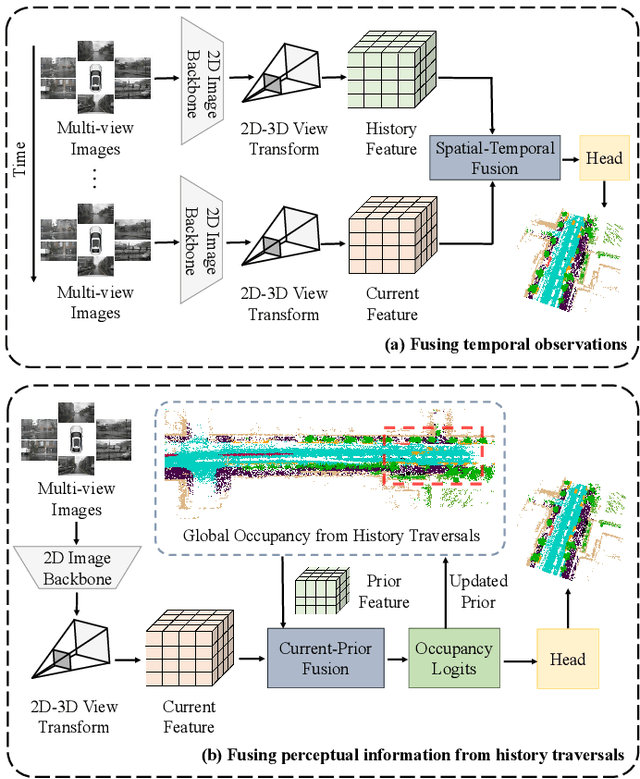
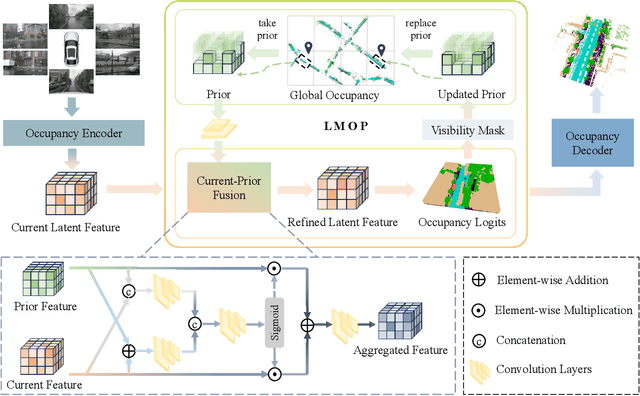
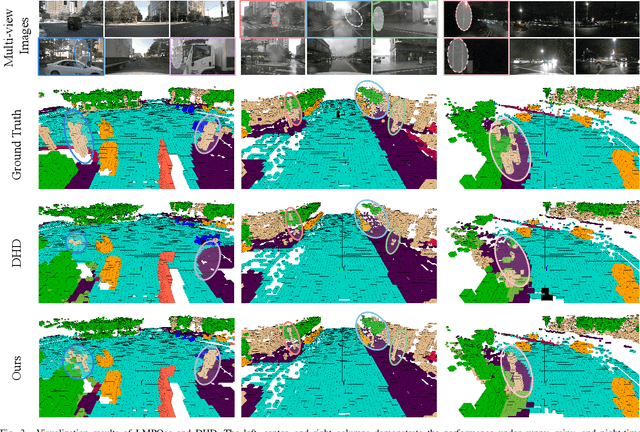
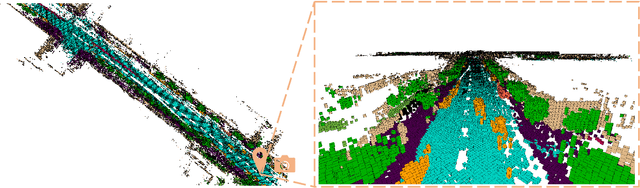
Vision-based 3D semantic occupancy prediction is critical for autonomous driving, enabling unified modeling of static infrastructure and dynamic agents. In practice, autonomous vehicles may repeatedly traverse identical geographic locations under varying environmental conditions, such as weather fluctuations and illumination changes. Existing methods in 3D occupancy prediction predominantly integrate adjacent temporal contexts. However, these works neglect to leverage perceptual information, which is acquired from historical traversals of identical geographic locations. In this paper, we propose Longterm Memory Prior Occupancy (LMPOcc), the first 3D occupancy prediction methodology that exploits long-term memory priors derived from historical traversal perceptual outputs. We introduce a plug-and-play architecture that integrates long-term memory priors to enhance local perception while simultaneously constructing global occupancy representations. To adaptively aggregate prior features and current features, we develop an efficient lightweight Current-Prior Fusion module. Moreover, we propose a model-agnostic prior format to ensure compatibility across diverse occupancy prediction baselines. LMPOcc achieves state-of-the-art performance validated on the Occ3D-nuScenes benchmark, especially on static semantic categories. Additionally, experimental results demonstrate LMPOcc's ability to construct global occupancy through multi-vehicle crowdsourcing.
ViG3D-UNet: Volumetric Vascular Connectivity-Aware Segmentation via 3D Vision Graph Representation
Apr 18, 2025Accurate vascular segmentation is essential for coronary visualization and the diagnosis of coronary heart disease. This task involves the extraction of sparse tree-like vascular branches from the volumetric space. However, existing methods have faced significant challenges due to discontinuous vascular segmentation and missing endpoints. To address this issue, a 3D vision graph neural network framework, named ViG3D-UNet, was introduced. This method integrates 3D graph representation and aggregation within a U-shaped architecture to facilitate continuous vascular segmentation. The ViG3D module captures volumetric vascular connectivity and topology, while the convolutional module extracts fine vascular details. These two branches are combined through channel attention to form the encoder feature. Subsequently, a paperclip-shaped offset decoder minimizes redundant computations in the sparse feature space and restores the feature map size to match the original input dimensions. To evaluate the effectiveness of the proposed approach for continuous vascular segmentation, evaluations were performed on two public datasets, ASOCA and ImageCAS. The segmentation results show that the ViG3D-UNet surpassed competing methods in maintaining vascular segmentation connectivity while achieving high segmentation accuracy. Our code will be available soon.
SO-DETR: Leveraging Dual-Domain Features and Knowledge Distillation for Small Object Detection
Apr 11, 2025Detection Transformer-based methods have achieved significant advancements in general object detection. However, challenges remain in effectively detecting small objects. One key difficulty is that existing encoders struggle to efficiently fuse low-level features. Additionally, the query selection strategies are not effectively tailored for small objects. To address these challenges, this paper proposes an efficient model, Small Object Detection Transformer (SO-DETR). The model comprises three key components: a dual-domain hybrid encoder, an enhanced query selection mechanism, and a knowledge distillation strategy. The dual-domain hybrid encoder integrates spatial and frequency domains to fuse multi-scale features effectively. This approach enhances the representation of high-resolution features while maintaining relatively low computational overhead. The enhanced query selection mechanism optimizes query initialization by dynamically selecting high-scoring anchor boxes using expanded IoU, thereby improving the allocation of query resources. Furthermore, by incorporating a lightweight backbone network and implementing a knowledge distillation strategy, we develop an efficient detector for small objects. Experimental results on the VisDrone-2019-DET and UAVVaste datasets demonstrate that SO-DETR outperforms existing methods with similar computational demands. The project page is available at https://github.com/ValiantDiligent/SO_DETR.
Drive in Corridors: Enhancing the Safety of End-to-end Autonomous Driving via Corridor Learning and Planning
Apr 10, 2025Safety remains one of the most critical challenges in autonomous driving systems. In recent years, the end-to-end driving has shown great promise in advancing vehicle autonomy in a scalable manner. However, existing approaches often face safety risks due to the lack of explicit behavior constraints. To address this issue, we uncover a new paradigm by introducing the corridor as the intermediate representation. Widely adopted in robotics planning, the corridors represents spatio-temporal obstacle-free zones for the vehicle to traverse. To ensure accurate corridor prediction in diverse traffic scenarios, we develop a comprehensive learning pipeline including data annotation, architecture refinement and loss formulation. The predicted corridor is further integrated as the constraint in a trajectory optimization process. By extending the differentiability of the optimization, we enable the optimized trajectory to be seamlessly trained within the end-to-end learning framework, improving both safety and interpretability. Experimental results on the nuScenes dataset demonstrate state-of-the-art performance of our approach, showing a 66.7% reduction in collisions with agents and a 46.5% reduction with curbs, significantly enhancing the safety of end-to-end driving. Additionally, incorporating the corridor contributes to higher success rates in closed-loop evaluations.
Topology-Driven Trajectory Optimization for Modelling Controllable Interactions Within Multi-Vehicle Scenario
Mar 07, 2025Trajectory optimization in multi-vehicle scenarios faces challenges due to its non-linear, non-convex properties and sensitivity to initial values, making interactions between vehicles difficult to control. In this paper, inspired by topological planning, we propose a differentiable local homotopy invariant metric to model the interactions. By incorporating this topological metric as a constraint into multi-vehicle trajectory optimization, our framework is capable of generating multiple interactive trajectories from the same initial values, achieving controllable interactions as well as supporting user-designed interaction patterns. Extensive experiments demonstrate its superior optimality and efficiency over existing methods. We will release open-source code to advance relative research.
Primitive-Planner: An Ultra Lightweight Quadrotor Planner with Time-optimal Primitives
Feb 24, 2025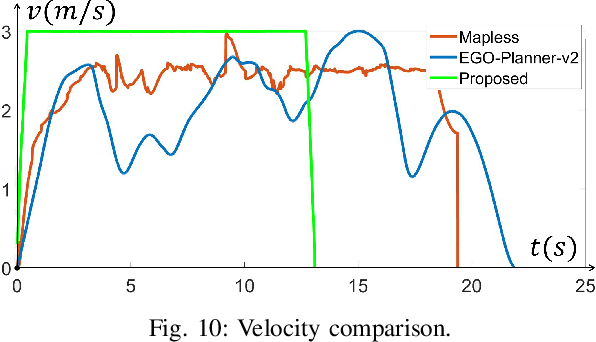
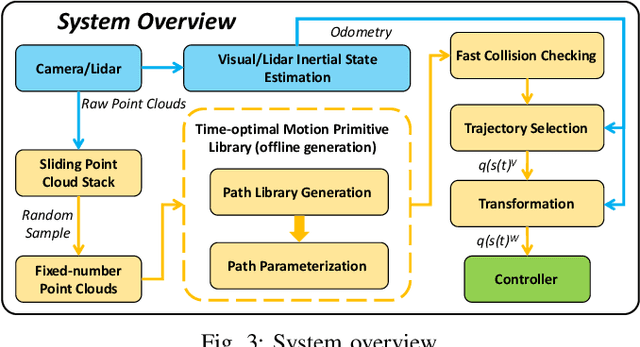
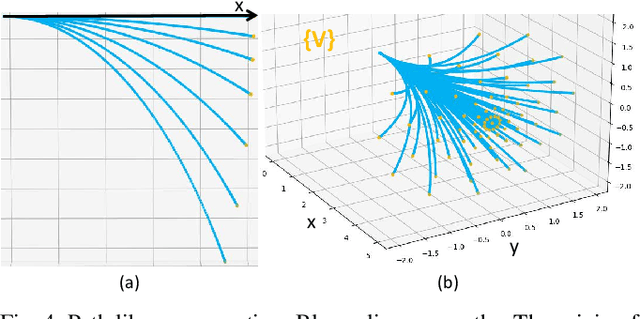
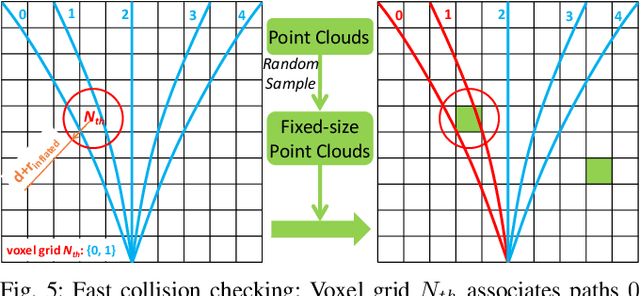
It is a significant requirement for a quadrotor trajectory planner to simultaneously guarantee trajectory quality and system lightweight. Many researchers focus on this problem, but there's still a gap between their performance and our common wish. In this paper, we propose an ultra lightweight quadrotor planner with time-optimal primitives. Firstly, a novel motion primitive library is proposed to generate time-optimal and dynamical feasible trajectories offline. Secondly, we propose a fast collision checking method with a deterministic time consumption, independent of the sampling resolution of the primitives. Finally, we select the minimum cost trajectory to execute among the safe primitives based on user-defined requirements. The propsed transformation relation between the local trajectories ensures the smoothness of the global trajectory. The planner reduces unnecessary online computing power consumption as much as possible, while ensuring a high-quality trajectory. Benchmark comparisons show that our method can generate the shortest flight time and distance of trajectory with the lowest computation overload. Challenging real-world experiments validate the robustness of our method.
Primitive-Swarm: An Ultra-lightweight and Scalable Planner for Large-scale Aerial Swarms
Feb 24, 2025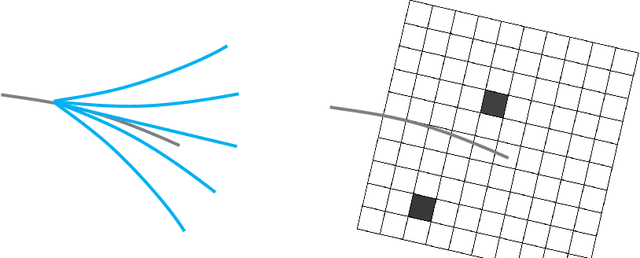
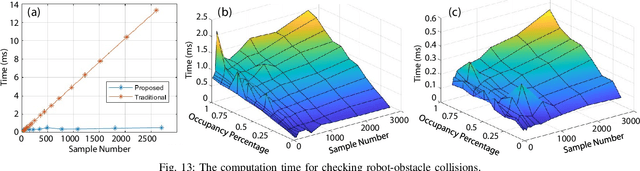
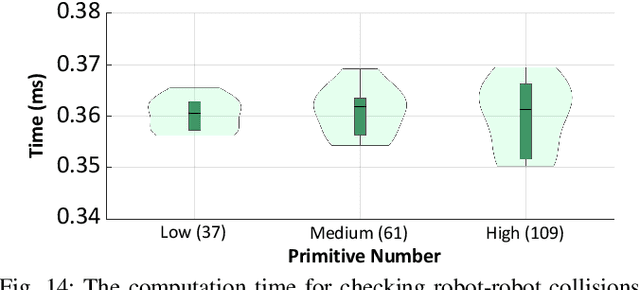
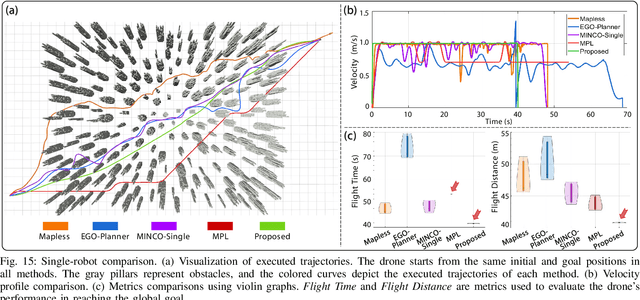
Achieving large-scale aerial swarms is challenging due to the inherent contradictions in balancing computational efficiency and scalability. This paper introduces Primitive-Swarm, an ultra-lightweight and scalable planner designed specifically for large-scale autonomous aerial swarms. The proposed approach adopts a decentralized and asynchronous replanning strategy. Within it is a novel motion primitive library consisting of time-optimal and dynamically feasible trajectories. They are generated utlizing a novel time-optimial path parameterization algorithm based on reachability analysis (TOPP-RA). Then, a rapid collision checking mechanism is developed by associating the motion primitives with the discrete surrounding space according to conflicts. By considering both spatial and temporal conflicts, the mechanism handles robot-obstacle and robot-robot collisions simultaneously. Then, during a replanning process, each robot selects the safe and minimum cost trajectory from the library based on user-defined requirements. Both the time-optimal motion primitive library and the occupancy information are computed offline, turning a time-consuming optimization problem into a linear-complexity selection problem. This enables the planner to comprehensively explore the non-convex, discontinuous 3-D safe space filled with numerous obstacles and robots, effectively identifying the best hidden path. Benchmark comparisons demonstrate that our method achieves the shortest flight time and traveled distance with a computation time of less than 1 ms in dense environments. Super large-scale swarm simulations, involving up to 1000 robots, running in real-time, verify the scalability of our method. Real-world experiments validate the feasibility and robustness of our approach. The code will be released to foster community collaboration.